 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Steganalyzer: A Green Learning Approach to Image Steganalysis
Jun 06, 2023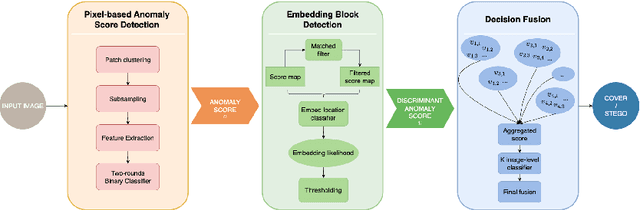



A novel learning solution to image steganalysis based on the green learning paradigm, called Green Steganalyzer (GS), is proposed in this work. GS consists of three modules: 1) pixel-based anomaly prediction, 2) embedding location detection, and 3) decision fusion for image-level detection. In the first module, GS decomposes an image into patches, adopts Saab transforms for feature extraction, and conducts self-supervised learning to predict an anomaly score of their center pixel. In the second module, GS analyzes the anomaly scores of a pixel and its neighborhood to find pixels of higher embedding probabilities. In the third module, GS focuses on pixels of higher embedding probabilities and fuses their anomaly scores to make final image-level classification. Compared with state-of-the-art deep-learning models, GS achieves comparable detection performance against S-UNIWARD, WOW and HILL steganography schemes with significantly lower computational complexity and a smaller model size, making it attractive for mobile/edge applications. Furthermore, GS is mathematically transparent because of its modular design.
A-PixelHop: A Green, Robust and Explainable Fake-Image Detector
Nov 07, 2021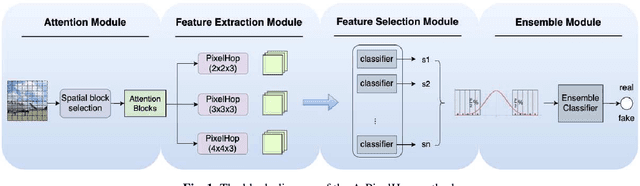


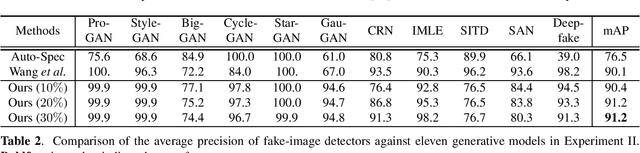
A novel method for detecting CNN-generated images, called Attentive PixelHop (or A-PixelHop), is proposed in this work. It has three advantages: 1) low computational complexity and a small model size, 2) high detection performance against a wide range of generative models, and 3) mathematical transparency. A-PixelHop is designed under the assumption that it is difficult to synthesize high-quality, high-frequency components in local regions. It contains four building modules: 1) selecting edge/texture blocks that contain significant high-frequency components, 2) applying multiple filter banks to them to obtain rich sets of spatial-spectral responses as features, 3) feeding features to multiple binary classifiers to obtain a set of soft decisions, 4) developing an effective ensemble scheme to fuse the soft decisions into the final decision. Experimental results show that A-PixelHop outperforms state-of-the-art methods in detecting CycleGAN-generated images. Furthermore, it can generalize well to unseen generative models and datasets.
Efficient Image Splicing Localization via Contrastive Feature Extraction
Jan 22, 2019

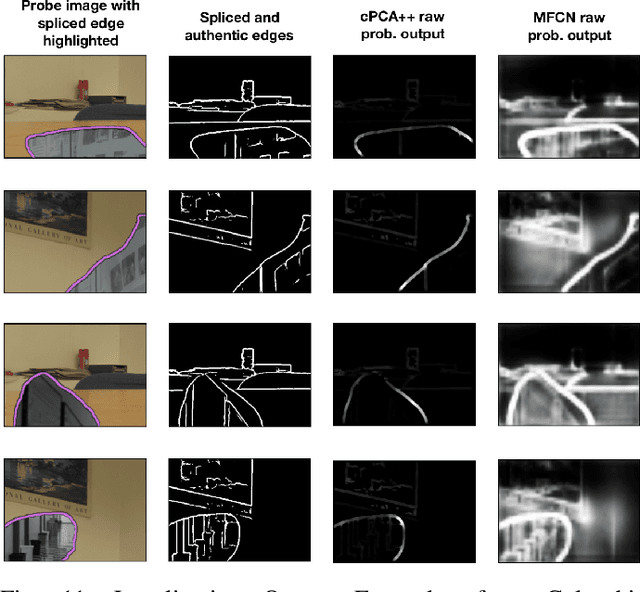

In this work, we propose a new data visualization and clustering technique for discovering discriminative structures in high-dimensional data. This technique, referred to as cPCA++, utilizes the fact that the interesting features of a "target" dataset may be obscured by high variance components during traditional PCA. By analyzing what is referred to as a "background" dataset (i.e., one that exhibits the high variance principal components but not the interesting structures), our technique is capable of efficiently highlighting the structure that is unique to the "target" dataset. Similar to another recently proposed algorithm called "contrastive PCA" (cPCA), the proposed cPCA++ method identifies important dataset specific patterns that are not detected by traditional PCA in a wide variety of settings. However, the proposed cPCA++ method is significantly more efficient than cPCA, because it does not require the parameter sweep in the latter approach. We applied the cPCA++ method to the problem of image splicing localization. In this application, we utilize authentic edges as the background dataset and the spliced edges as the target dataset. The proposed method is significantly more efficient than state-of-the-art methods, as the former does not require iterative updates of filter weights via stochastic gradient descent and backpropagation, nor the training of a classifier. Furthermore, the cPCA++ method is shown to provide performance scores comparable to the state-of-the-art Multi-task Fully Convolutional Network (MFCN).
Image Splicing Localization Using A Multi-Task Fully Convolutional Network (MFCN)
Sep 06, 2017



In this work, we propose a technique that utilizes a fully convolutional network (FCN) to localize image splicing attacks. We first evaluated a single-task FCN (SFCN) trained only on the surface label. Although the SFCN is shown to provide superior performance over existing methods, it still provides a coarse localization output in certain cases. Therefore, we propose the use of a multi-task FCN (MFCN) that utilizes two output branches for multi-task learning. One branch is used to learn the surface label, while the other branch is used to learn the edge or boundary of the spliced region. We trained the networks using the CASIA v2.0 dataset, and tested the trained models on the CASIA v1.0, Columbia Uncompressed, Carvalho, and the DARPA/NIST Nimble Challenge 2016 SCI datasets. Experiments show that the SFCN and MFCN outperform existing splicing localization algorithms, and that the MFCN can achieve finer localization than the SFCN.
* This manuscript was submitted for publication