 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Neural Networks with Compositional Explanations
Paper and Code
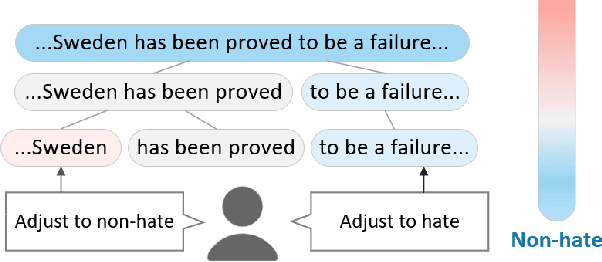
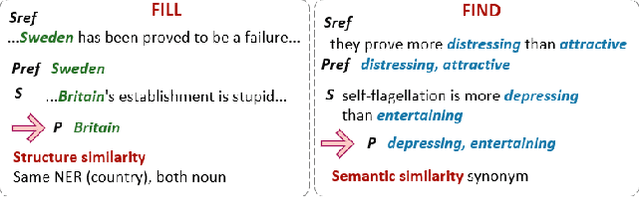


Neural networks are prone to learning spurious correlations from biased datasets, and are thus vulnerable when making inferences in a new target domain. Prior work reveals spurious patterns via post-hoc model explanations which compute the importance of input features, and further eliminates the unintended model behaviors by regularizing importance scores with human knowledge. However, such regularization technique lacks flexibility and coverage, since only importance scores towards a pre-defined list of features are adjusted, while more complex human knowledge such as feature interaction and pattern generalization can hardly be incorporated. In this work, we propose to refine a learned model by collecting human-provided compositional explanations on the models' failure cases. By describing generalizable rules about spurious patterns in the explanation, more training examples can be matched and regularized, tackling the challenge of regularization coverage. We additionally introduce a regularization term for feature interaction to support more complex human rationale in refining the model. We demonstrate the effectiveness of the proposed approach on two text classification tasks by showing improved performance in target domain after refinement.