 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Based Memory Editing for Task-Free Continual Learning
Jun 27, 2020
Prior work on continual learning often operate in a "task-aware" manner, by assuming that the task boundaries and identifies of the data instances are known at all times. While in practice, it is rarely the case that such information are exposed to the methods (i.e., thus called "task-free")--a setting that is relatively underexplored. Recent attempts on task-free continual learning build on previous memory replay methods and focus on developing memory management strategies such that model performance over priorly seen instances can be best retained. In this paper, looking from a complementary angle, we propose a principled approach to "edit" stored examples which aims to carry more updated information from the data stream in the memory. We use gradient updates to edit stored examples so that they are more likely to be forgotten in future updates. Experiments on five benchmark datasets show the proposed method can be seamlessly combined with baselines to significantly improve the performance. Code has been released at https://github.com/INK-USC/GMED.
Visually Grounded Continual Learning of Compositional Semantics
May 02, 2020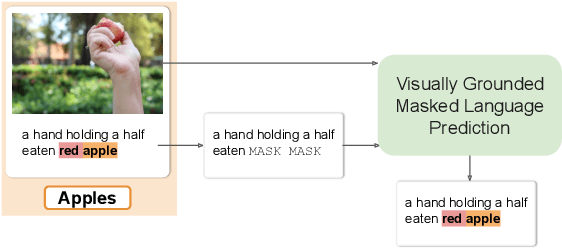
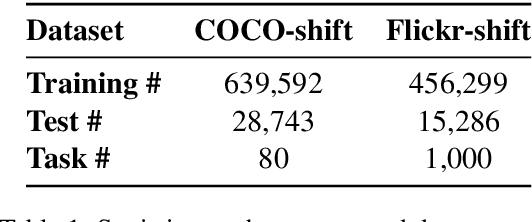
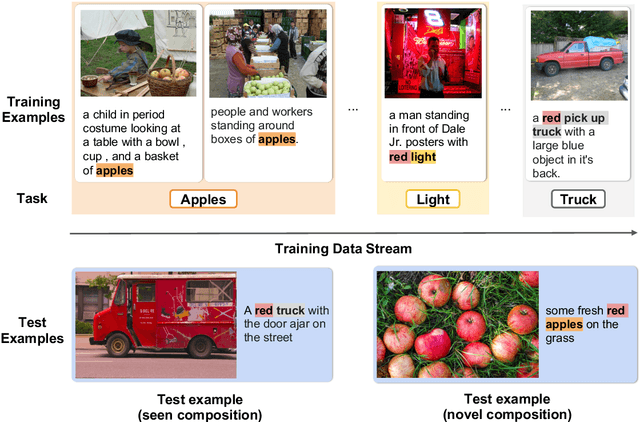
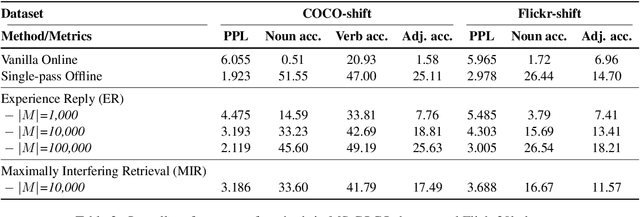
Children's language acquisition from the visual world is a real-world example of continual learning from dynamic and evolving environments; yet we lack a realistic setup to study neural networks' capability in human-like language acquisition. In this paper, we propose a realistic setup by simulating children's language acquisition process. We formulate language acquisition as a masked language modeling task where the model visits a stream of data with continuously shifting distribution. Our training and evaluation encode two important challenges in human's language learning, namely the continual learning and the compositionality. We show the performance of existing continual learning algorithms is far from satisfactory. We also study the interactions between memory based continual learning algorithms and compositional generalization and conclude that overcoming overfitting and compositional overfitting may be crucial for a good performance in our problem setup. Our code and data can be found at https://github.com/INK-USC/VG-CCL.
A Benchmark for Structured Procedural Knowledge Extraction from Cooking Videos
May 02, 2020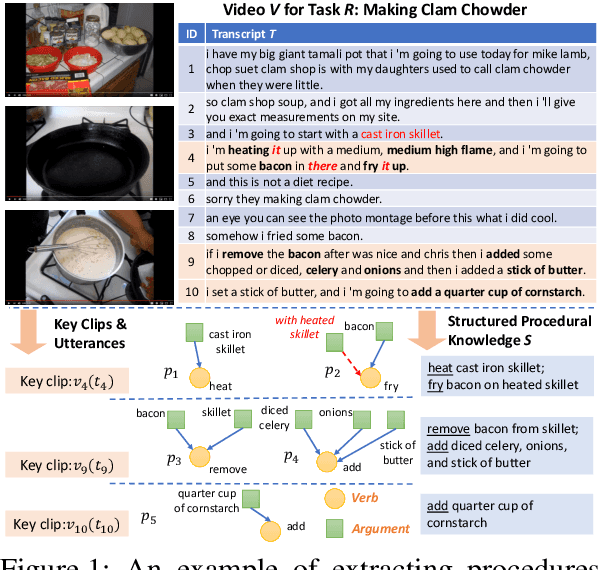
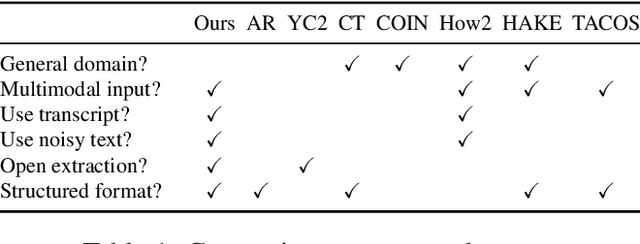
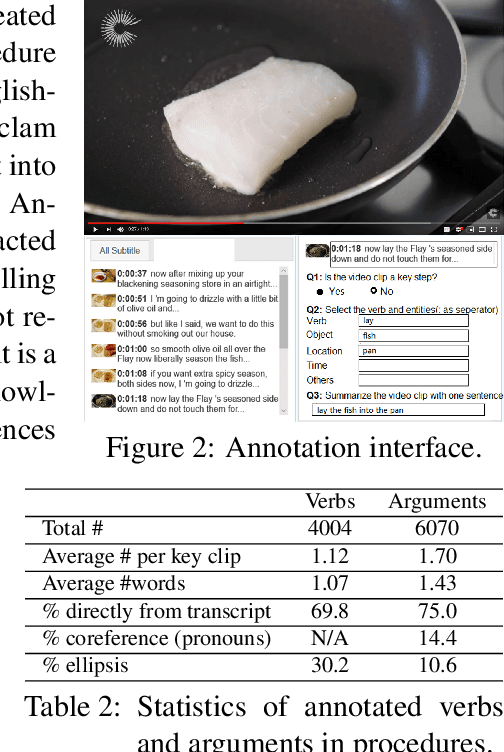

Procedural knowledge, which we define as concrete information about the sequence of actions that go into performing a particular procedure, plays an important role in understanding real-world tasks and actions. Humans often learn this knowledge from instructional text and video, and in this paper we aim to perform automatic extraction of this knowledge in a similar way. As a concrete step in this direction, we propose the new task of inferring procedures in a structured form(a data structure containing verbs and arguments) from multimodal instructional video contents and their corresponding transcripts. We first create a manually annotated, large evaluation dataset including over350 instructional cooking videos along with over 15,000 English sentences in transcripts spanning over 89 recipes. We conduct analysis of the challenges posed by this task and dataset with experiments with unsupervised segmentation, semantic role labeling, and visual action detection based baselines. The dataset and code will be publicly available at https://github.com/frankxu2004/cooking-procedural-extraction.
Improving BERT Fine-tuning with Embedding Normalization
Nov 10, 2019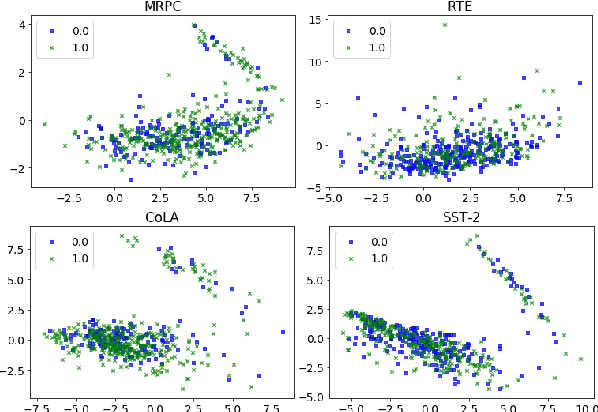
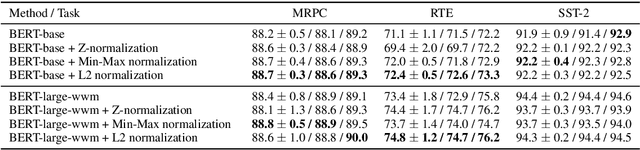
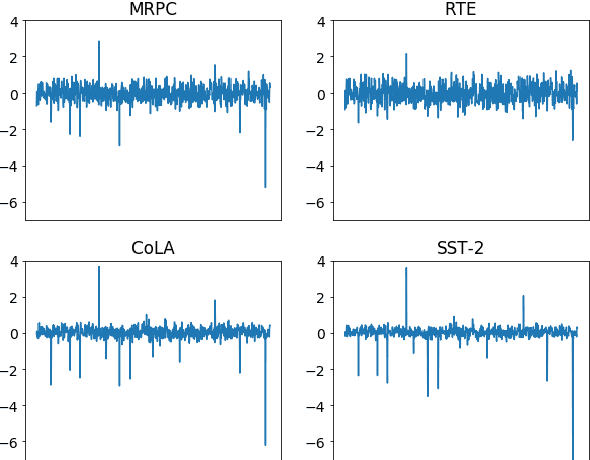
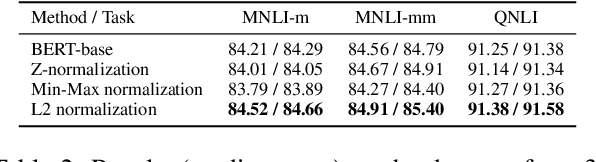
Large pre-trained sentence encoders like BERT start a new chapter in natural language processing. A common practice to apply pre-trained BERT to sequence classification tasks (e.g., classification of sentences or sentence pairs) is by feeding the embedding of [CLS] token (in the last layer) to a task-specific classification layer, and then fine tune the model parameters of BERT and classifier jointly. In this paper, we conduct systematic analysis over several sequence classification datasets to examine the embedding values of [CLS] token before the fine tuning phase, and present the biased embedding distribution issue---i.e., embedding values of [CLS] concentrate on a few dimensions and are non-zero centered. Such biased embedding brings challenge to the optimization process during fine-tuning as gradients of [CLS] embedding may explode and result in degraded model performance. We further propose several simple yet effective normalization methods to modify the [CLS] embedding during the fine-tuning. Compared with the previous practice, neural classification model with the normalized embedding shows improvements on several text classification tasks, demonstrates the effectiveness of our method.
Towards Hierarchical Importance Attribution: Explaining Compositional Semantics for Neural Sequence Models
Nov 08, 2019
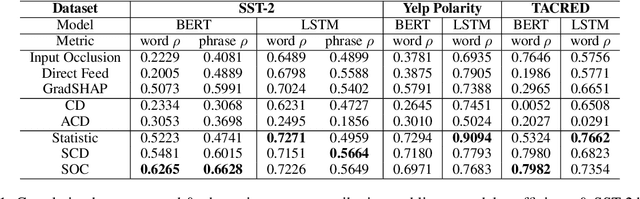
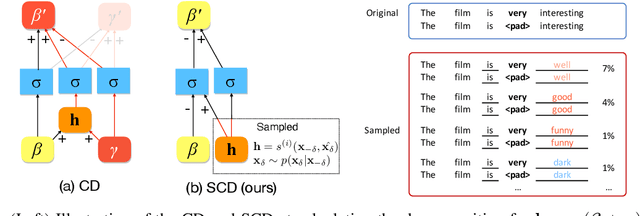

The impressive performance of neural networks on natural language processing tasks attributes to their ability to model complicated word and phrase interactions. Existing flat, word level explanations of predictions hardly unveil how neural networks handle compositional semantics to reach predictions. To tackle the challenge, we study hierarchical explanation of neural network predictions. We identify non-additivity and independent importance attributions within hierarchies as two desirable properties for highlighting word and phrase interactions. We show prior efforts on hierarchical explanations, e.g. contextual decomposition, however, do not satisfy the desired properties mathematically. In this paper, we propose a formal way to quantify the importance of each word or phrase for hierarchical explanations. Following the formulation, we propose Sampling and Contextual Decomposition (SCD) algorithm and Sampling and Occlusion (SOC) algorithm. Human and metrics evaluation on both LSTM models and BERT Transformer models on multiple datasets show that our algorithms outperform prior hierarchical explanation algorithms. Our algorithms apply to hierarchical visualization of compositional semantics, extraction of classification rules and improving human trust of models.
Eliciting Knowledge from Experts:Automatic Transcript Parsing for Cognitive Task Analysis
Jun 26, 2019
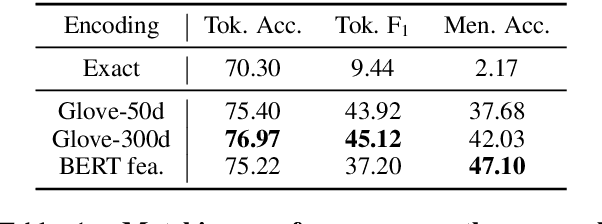

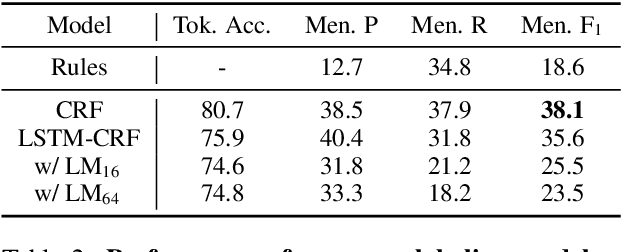
Cognitive task analysis (CTA) is a type of analysis in applied psychology aimed at eliciting and representing the knowledge and thought processes of domain experts. In CTA, often heavy human labor is involved to parse the interview transcript into structured knowledge (e.g., flowchart for different actions). To reduce human efforts and scale the process, automated CTA transcript parsing is desirable. However, this task has unique challenges as (1) it requires the understanding of long-range context information in conversational text; and (2) the amount of labeled data is limited and indirect---i.e., context-aware, noisy, and low-resource. In this paper, we propose a weakly-supervised information extraction framework for automated CTA transcript parsing. We partition the parsing process into a sequence labeling task and a text span-pair relation extraction task, with distant supervision from human-curated protocol files. To model long-range context information for extracting sentence relations, neighbor sentences are involved as a part of input. Different types of models for capturing context dependency are then applied. We manually annotate real-world CTA transcripts to facilitate the evaluation of the parsing tasks