 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Knowledge from Experts:Automatic Transcript Parsing for Cognitive Task Analysis
Paper and Code

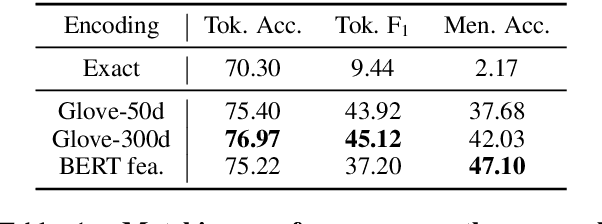

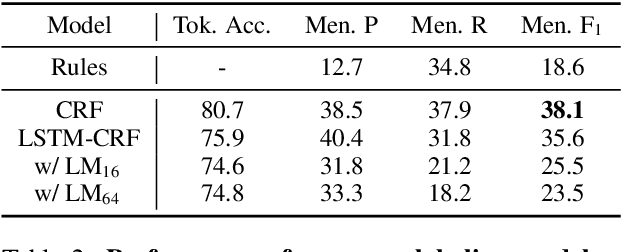
Cognitive task analysis (CTA) is a type of analysis in applied psychology aimed at eliciting and representing the knowledge and thought processes of domain experts. In CTA, often heavy human labor is involved to parse the interview transcript into structured knowledge (e.g., flowchart for different actions). To reduce human efforts and scale the process, automated CTA transcript parsing is desirable. However, this task has unique challenges as (1) it requires the understanding of long-range context information in conversational text; and (2) the amount of labeled data is limited and indirect---i.e., context-aware, noisy, and low-resource. In this paper, we propose a weakly-supervised information extraction framework for automated CTA transcript parsing. We partition the parsing process into a sequence labeling task and a text span-pair relation extraction task, with distant supervision from human-curated protocol files. To model long-range context information for extracting sentence relations, neighbor sentences are involved as a part of input. Different types of models for capturing context dependency are then applied. We manually annotate real-world CTA transcripts to facilitate the evaluation of the parsing tasks