 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Learning of Few-shot Learners across NLP Tasks
Paper and Code
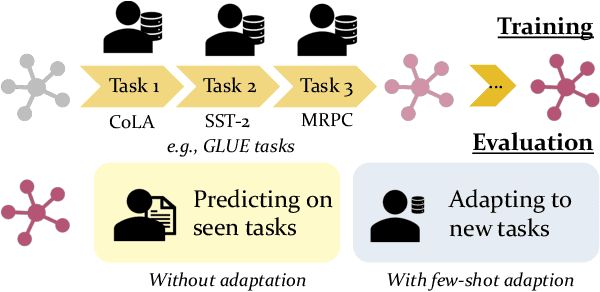
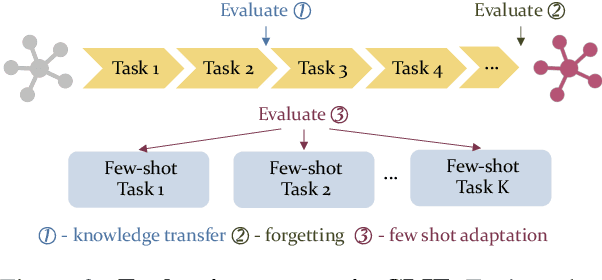
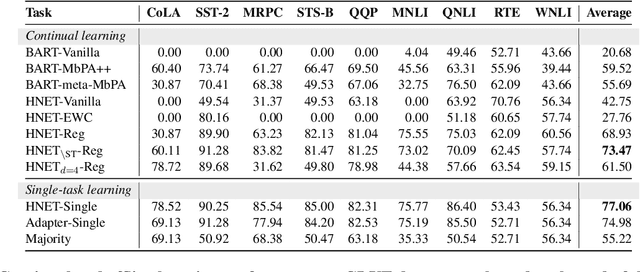
Recent advances in large pre-trained language models have greatly improved the performance on a broad set of NLP tasks. However, adapting an existing model to new tasks often requires (repeated) re-training over enormous labeled data that is prohibitively expensive to obtain. Moreover, models learned on new tasks may gradually "forget" about the knowledge learned from earlier tasks (i.e., catastrophic forgetting). In this paper, we study the challenge of lifelong learning to few-shot learn over a sequence of diverse NLP tasks, through continuously fine-tuning a language model. We investigate the model's ability of few-shot generalization to new tasks while retaining its performance on the previously learned tasks. We explore existing continual learning methods in solving this problem and propose a continual meta-learning approach which learns to generate adapter weights from a few examples while regularizing changes of the weights to mitigate catastrophic forgetting. We demonstrate our approach preserves model performance over training tasks and leads to positive knowledge transfer when the future tasks are learned.