 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Image-Text Metrics Respect Semantic Invariances?
May 23, 2026Reference-free image-to-text evaluators are now standard for scoring image-caption alignment, yet it is unclear whether they respect semantic invariances. We present an invariance probe on five popular evaluators (CLIPScore, PAC-S, UMIC, FLEUR, and a deterministic LLM judge) under semantics-preserving perturbations along three axes -- spatial (flips, context-preserving repositioning, light rotations), object (scale, category), and socio-linguistic framing (cultural/economic adjectives with neutral and length-matched controls). Across curated slices of three detection datasets and three caption evaluation suites, we find consistent non-semantic sensitivities, where benign spatial edits and simple phrasing changes shift scores by $\approx$6--9\% on average, and for systems separated by just 0.7\%, these shifts can cause ranking flips in up to $\sim$37\% of cases, particularly under spatial changes. A small human study also supports this finding and confirms that annotators generally judge perturbed pairs as equally correct, so these shifts reflect metric behavior rather than semantic change. We further propose invariance-calibrated scoring, a post-hoc adjustment that roughly halves median absolute sensitivity while retaining correlation with learned caption evaluators.
Au-M-ol: A Unified Model for Medical Audio and Language Understanding
Apr 25, 2026In this work, we present Au-M-ol, a novel multimodal architecture that extends Large Language Models (LLMs) with audio processing. It is designed to improve performance on clinically relevant tasks such as Automatic Speech Recognition (ASR). Au-M-ol has three main components: (1) an audio encoder that extracts rich acoustic features from medical speech, (2) an adaptation layer that maps audio features into the LLM input space, and (3) a pretrained LLM that performs transcription and clinical language understanding. This design allows the model to interpret spoken medical content directly, improving both accuracy and robustness. In experiments, Au-M-ol reduces Word Error Rate (WER) by 56\% compared to state-of-the-art baselines on medical transcription tasks. The model also performs well in challenging conditions, including noisy environments, domain-specific terminology, and speaker variability. These results suggest that Au-M-ol is a strong candidate for real-world clinical applications, where reliable and context-aware audio understanding is essential.
Robust Audio-Text Retrieval via Cross-Modal Attention and Hybrid Loss
Apr 25, 2026Audio-text retrieval enables semantic alignment between audio content and natural language queries, supporting applications in multimedia search, accessibility, and surveillance. However, current state-of-the-art approaches struggle with long, noisy, and weakly labeled audio due to their reliance on contrastive learning and large-batch training. We propose a novel multimodal retrieval framework that refines audio and text embeddings using a cross-modal embedding refinement module combining transformer-based projection, linear mapping, and bidirectional attention. To further improve robustness, we introduce a hybrid loss function blending cosine similarity, $\mathcal{L}_{1}$, and contrastive objectives, enabling stable training even under small-batch constraints. Our approach efficiently handles long-form and noisy audio (SNR 5 to 15) via silence-aware chunking and attention-based pooling. Experiments on benchmark datasets demonstrate improvements over prior methods.
PAR$^2$-RAG: Planned Active Retrieval and Reasoning for Multi-Hop Question Answering
Mar 30, 2026Large language models (LLMs) remain brittle on multi-hop question answering (MHQA), where answering requires combining evidence across documents through retrieval and reasoning. Iterative retrieval systems can fail by locking onto an early low-recall trajectory and amplifying downstream errors, while planning-only approaches may produce static query sets that cannot adapt when intermediate evidence changes. We propose \textbf{Planned Active Retrieval and Reasoning RAG (PAR$^2$-RAG)}, a two-stage framework that separates \emph{coverage} from \emph{commitment}. PAR$^2$-RAG first performs breadth-first anchoring to build a high-recall evidence frontier, then applies depth-first refinement with evidence sufficiency control in an iterative loop. Across four MHQA benchmarks, PAR$^2$-RAG consistently outperforms existing state-of-the-art baselines, compared with IRCoT, PAR$^2$-RAG achieves up to \textbf{23.5\%} higher accuracy, with retrieval gains of up to \textbf{10.5\%} in NDCG.
GraphER: An Efficient Graph-Based Enrichment and Reranking Method for Retrieval-Augmented Generation
Mar 26, 2026Semantic search in retrieval-augmented generation (RAG) systems is often insufficient for complex information needs, particularly when relevant evidence is scattered across multiple sources. Prior approaches to this problem include agentic retrieval strategies, which expand the semantic search space by generating additional queries. However, these methods do not fully leverage the organizational structure of the data and instead rely on iterative exploration, which can lead to inefficient retrieval. Another class of approaches employs knowledge graphs to model non-semantic relationships through graph edges. Although effective in capturing richer proximities, such methods incur significant maintenance costs and are often incompatible with the vector stores used in most production systems. To address these limitations, we propose GraphER, a graph-based enrichment and reranking method that captures multiple forms of proximity beyond semantic similarity. GraphER independently enriches data objects during offline indexing and performs graph-based reranking over candidate objects at query time. This design does not require a knowledge graph, allowing GraphER to integrate seamlessly with standard vector stores. In addition, GraphER is retriever-agnostic and introduces negligible latency overhead. Experiments on multiple retrieval benchmarks demonstrate the effectiveness of the proposed approach.
LLM NL2SQL Robustness: Surface Noise vs. Linguistic Variation in Traditional and Agentic Settings
Mar 17, 2026Robustness evaluation for Natural Language to SQL (NL2SQL) systems is essential because real-world database environments are dynamic, noisy, and continuously evolving, whereas conventional benchmark evaluations typically assume static schemas and well-formed user inputs. In this work, we introduce a robustness evaluation benchmark containing approximately ten types of perturbations and conduct evaluations under both traditional and agentic settings. We assess multiple state-of-the-art large language models (LLMs), including Grok-4.1, Gemini-3-Pro, Claude-Opus-4.6, and GPT-5.2. Our results show that these models generally maintain strong performance under several perturbations; however, notable performance degradation is observed for surface-level noise (e.g., character-level corruption) and linguistic variation that preserves semantics while altering lexical or syntactic forms. Furthermore, we observe that surface-level noise causes larger performance drops in traditional pipelines, whereas linguistic variation presents greater challenges in agentic settings. These findings highlight the remaining challenges in achieving robust NL2SQL systems, particularly in handling linguistic variability.
LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding
Oct 08, 2025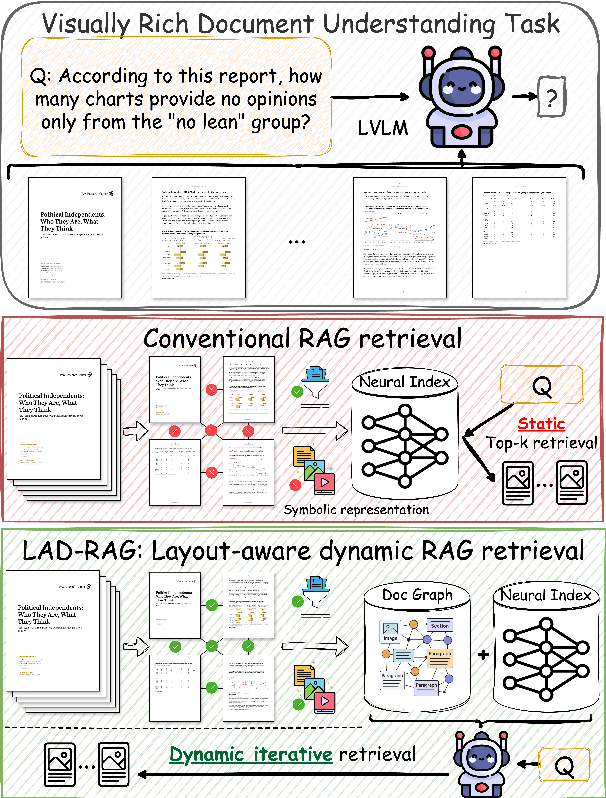
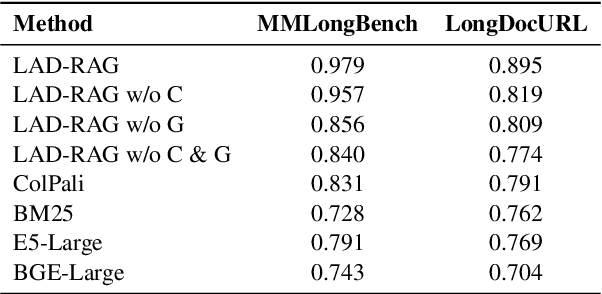
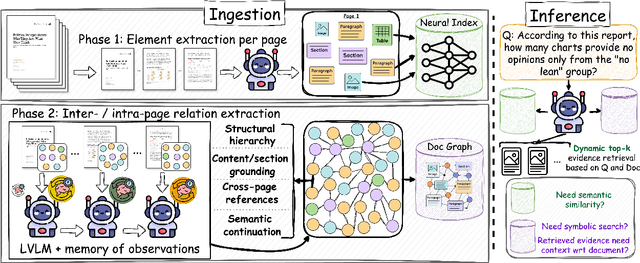
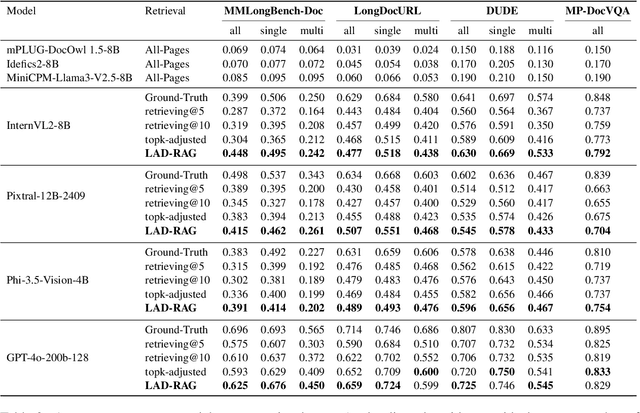
Question answering over visually rich documents (VRDs) requires reasoning not only over isolated content but also over documents' structural organization and cross-page dependencies. However, conventional retrieval-augmented generation (RAG) methods encode content in isolated chunks during ingestion, losing structural and cross-page dependencies, and retrieve a fixed number of pages at inference, regardless of the specific demands of the question or context. This often results in incomplete evidence retrieval and degraded answer quality for multi-page reasoning tasks. To address these limitations, we propose LAD-RAG, a novel Layout-Aware Dynamic RAG framework. During ingestion, LAD-RAG constructs a symbolic document graph that captures layout structure and cross-page dependencies, adding it alongside standard neural embeddings to yield a more holistic representation of the document. During inference, an LLM agent dynamically interacts with the neural and symbolic indices to adaptively retrieve the necessary evidence based on the query. Experiments on MMLongBench-Doc, LongDocURL, DUDE, and MP-DocVQA demonstrate that LAD-RAG improves retrieval, achieving over 90% perfect recall on average without any top-k tuning, and outperforming baseline retrievers by up to 20% in recall at comparable noise levels, yielding higher QA accuracy with minimal latency.
Weakly-Supervised Detection of Bone Lesions in CT
Jan 31, 2024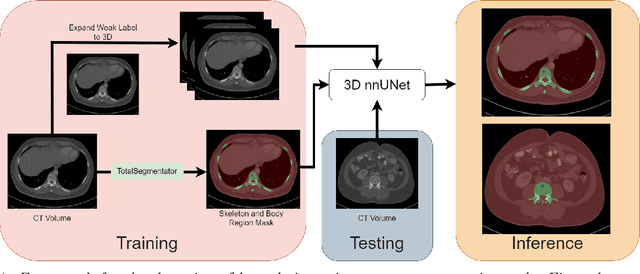

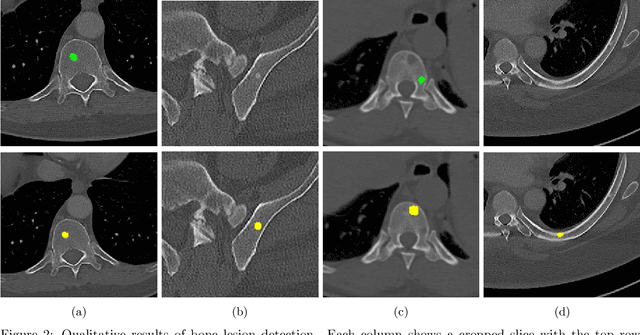
The skeletal region is one of the common sites of metastatic spread of cancer in the breast and prostate. CT is routinely used to measure the size of lesions in the bones. However, they can be difficult to spot due to the wide variations in their sizes, shapes, and appearances. Precise localization of such lesions would enable reliable tracking of interval changes (growth, shrinkage, or unchanged status). To that end, an automated technique to detect bone lesions is highly desirable. In this pilot work, we developed a pipeline to detect bone lesions (lytic, blastic, and mixed) in CT volumes via a proxy segmentation task. First, we used the bone lesions that were prospectively marked by radiologists in a few 2D slices of CT volumes and converted them into weak 3D segmentation masks. Then, we trained a 3D full-resolution nnUNet model using these weak 3D annotations to segment the lesions and thereby detected them. Our automated method detected bone lesions in CT with a precision of 96.7% and recall of 47.3% despite the use of incomplete and partial training data. To the best of our knowledge, we are the first to attempt the direct detection of bone lesions in CT via a proxy segmentation task.
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
Apr 04, 2023Large language models (LLMs) have demonstrated their significant potential to be applied for addressing various application tasks. However, traditional recommender systems continue to face great challenges such as poor interactivity and explainability, which actually also hinder their broad deployment in real-world systems. To address these limitations, this paper proposes a novel paradigm called Chat-Rec (ChatGPT Augmented Recommender System) that innovatively augments LLMs for building conversational recommender systems by converting user profiles and historical interactions into prompts. Chat-Rec is demonstrated to be effective in learning user preferences and establishing connections between users and products through in-context learning, which also makes the recommendation process more interactive and explainable. What's more, within the Chat-Rec framework, user's preferences can transfer to different products for cross-domain recommendations, and prompt-based injection of information into LLMs can also handle the cold-start scenarios with new items. In our experiments, Chat-Rec effectively improve the results of top-k recommendations and performs better in zero-shot rating prediction task. Chat-Rec offers a novel approach to improving recommender systems and presents new practical scenarios for the implementation of AIGC (AI generated content) in recommender system studies.
Modeling Global Distribution for Federated Learning with Label Distribution Skew
Dec 17, 2022Federated learning achieves joint training of deep models by connecting decentralized data sources, which can significantly mitigate the risk of privacy leakage. However, in a more general case, the distributions of labels among clients are different, called ``label distribution skew''. Directly applying conventional federated learning without consideration of label distribution skew issue significantly hurts the performance of the global model. To this end, we propose a novel federated learning method, named FedMGD, to alleviate the performance degradation caused by the label distribution skew issue. It introduces a global Generative Adversarial Network to model the global data distribution without access to local datasets, so the global model can be trained using the global information of data distribution without privacy leakage. The experimental results demonstrate that our proposed method significantly outperforms the state-of-the-art on several public benchmarks. Code is available at \url{https://github.com/Sheng-T/FedMGD}.