 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal Large Language Models for Missing Modality Completion in Product Catalogues
Jan 28, 2026Missing-modality information on e-commerce platforms, such as absent product images or textual descriptions, often arises from annotation errors or incomplete metadata, impairing both product presentation and downstream applications such as recommendation systems. Motivated by the multimodal generative capabilities of recent Multimodal Large Language Models (MLLMs), this work investigates a fundamental yet underexplored question: can MLLMs generate missing modalities for products in e-commerce scenarios? We propose the Missing Modality Product Completion Benchmark (MMPCBench), which consists of two sub-benchmarks: a Content Quality Completion Benchmark and a Recommendation Benchmark. We further evaluate six state-of-the-art MLLMs from the Qwen2.5-VL and Gemma-3 model families across nine real-world e-commerce categories, focusing on image-to-text and text-to-image completion tasks. Experimental results show that while MLLMs can capture high-level semantics, they struggle with fine-grained word-level and pixel- or patch-level alignment. In addition, performance varies substantially across product categories and model scales, and we observe no trivial correlation between model size and performance, in contrast to trends commonly reported in mainstream benchmarks. We also explore Group Relative Policy Optimization (GRPO) to better align MLLMs with this task. GRPO improves image-to-text completion but does not yield gains for text-to-image completion. Overall, these findings expose the limitations of current MLLMs in real-world cross-modal generation and represent an early step toward more effective missing-modality product completion.
Are Multimodal Embeddings Truly Beneficial for Recommendation? A Deep Dive into Whole vs. Individual Modalities
Aug 10, 2025Multimodal recommendation (MMRec) has emerged as a mainstream paradigm, typically leveraging text and visual embeddings extracted from pre-trained models such as Sentence-BERT, Vision Transformers, and ResNet. This approach is founded on the intuitive assumption that incorporating multimodal embeddings can enhance recommendation performance. However, despite its popularity, this assumption lacks comprehensive empirical verification. This presents a critical research gap. To address it, we pose the central research question of this paper: Are multimodal embeddings truly beneficial for recommendation? To answer this question, we conduct a large-scale empirical study examining the role of text and visual embeddings in modern MMRec models, both as a whole and individually. Specifically, we pose two key research questions: (1) Do multimodal embeddings as a whole improve recommendation performance? (2) Is each individual modality - text and image - useful when used alone? To isolate the effect of individual modalities - text or visual - we employ a modality knockout strategy by setting the corresponding embeddings to either constant values or random noise. To ensure the scale and comprehensiveness of our study, we evaluate 14 widely used state-of-the-art MMRec models. Our findings reveal that: (1) multimodal embeddings generally enhance recommendation performance - particularly when integrated through more sophisticated graph-based fusion models. Surprisingly, commonly adopted baseline models with simple fusion schemes, such as VBPR and BM3, show only limited gains. (2) The text modality alone achieves performance comparable to the full multimodal setting in most cases, whereas the image modality alone does not. These results offer foundational insights and practical guidance for the MMRec community. We will release our code and datasets to facilitate future research.
Advancing Towards a Marine Digital Twin Platform: Modeling the Mar Menor Coastal Lagoon Ecosystem in the South Western Mediterranean
Sep 16, 2024



Coastal marine ecosystems face mounting pressures from anthropogenic activities and climate change, necessitating advanced monitoring and modeling approaches for effective management. This paper pioneers the development of a Marine Digital Twin Platform aimed at modeling the Mar Menor Coastal Lagoon Ecosystem in the Region of Murcia. The platform leverages Artificial Intelligence to emulate complex hydrological and ecological models, facilitating the simulation of what-if scenarios to predict ecosystem responses to various stressors. We integrate diverse datasets from public sources to construct a comprehensive digital representation of the lagoon's dynamics. The platform's modular design enables real-time stakeholder engagement and informed decision-making in marine management. Our work contributes to the ongoing discourse on advancing marine science through innovative digital twin technologies.
ReCo: A Dataset for Residential Community Layout Planning
Jun 08, 2022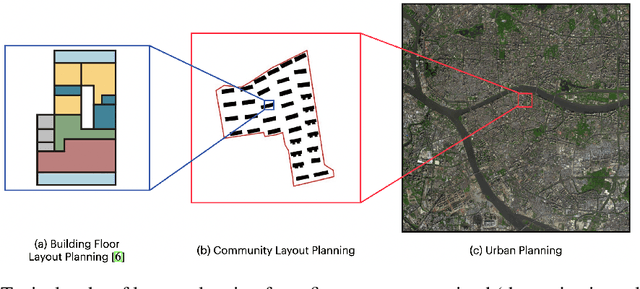
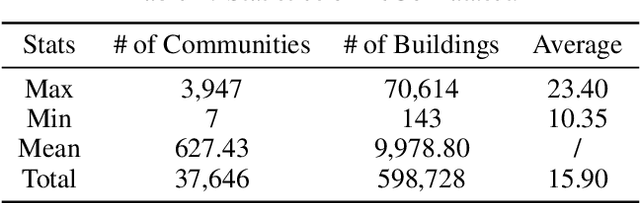
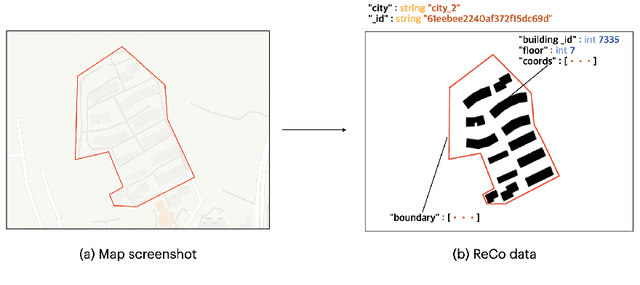
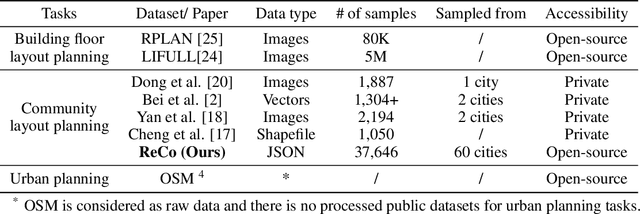
Layout planning is centrally important in the field of architecture and urban design. Among the various basic units carrying urban functions, residential community plays a vital part for supporting human life. Therefore, the layout planning of residential community has always been of concern, and has attracted particular attention since the advent of deep learning that facilitates the automated layout generation and spatial pattern recognition. However, the research circles generally suffer from the insufficiency of residential community layout benchmark or high-quality datasets, which hampers the future exploration of data-driven methods for residential community layout planning. The lack of datasets is largely due to the difficulties of large-scale real-world residential data acquisition and long-term expert screening. In order to address the issues and advance a benchmark dataset for various intelligent spatial design and analysis applications in the development of smart city, we introduce Residential Community Layout Planning (ReCo) Dataset, which is the first and largest open-source vector dataset related to real-world community to date. ReCo Dataset is presented in multiple data formats with 37,646 residential community layout plans, covering 598,728 residential buildings with height information. ReCo can be conveniently adapted for residential community layout related urban design tasks, e.g., generative layout design, morphological pattern recognition and spatial evaluation. To validate the utility of ReCo in automated residential community layout planning, a Generative Adversarial Network (GAN) based generative model is further applied to the dataset. We expect ReCo Dataset to inspire more creative and practical work in intelligent design and beyond. The ReCo Dataset is published at: https://www.kaggle.com/fdudsde/reco-dataset.
Asynchronous Parallel Incremental Block-Coordinate Descent for Decentralized Machine Learning
Feb 07, 2022Machine learning (ML) is a key technique for big-data-driven modelling and analysis of massive Internet of Things (IoT) based intelligent and ubiquitous computing. For fast-increasing applications and data amounts, distributed learning is a promising emerging paradigm since it is often impractical or inefficient to share/aggregate data to a centralized location from distinct ones. This paper studies the problem of training an ML model over decentralized systems, where data are distributed over many user devices and the learning algorithm run on-device, with the aim of relaxing the burden at a central entity/server. Although gossip-based approaches have been used for this purpose in different use cases, they suffer from high communication costs, especially when the number of devices is large. To mitigate this, incremental-based methods are proposed. We first introduce incremental block-coordinate descent (I-BCD) for the decentralized ML, which can reduce communication costs at the expense of running time. To accelerate the convergence speed, an asynchronous parallel incremental BCD (API-BCD) method is proposed, where multiple devices/agents are active in an asynchronous fashion. We derive convergence properties for the proposed methods. Simulation results also show that our API-BCD method outperforms state of the art in terms of running time and communication costs.
Adaptive Stochastic ADMM for Decentralized Reinforcement Learning in Edge Industrial IoT
Jun 30, 2021
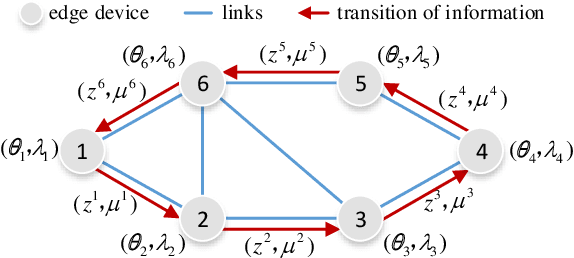
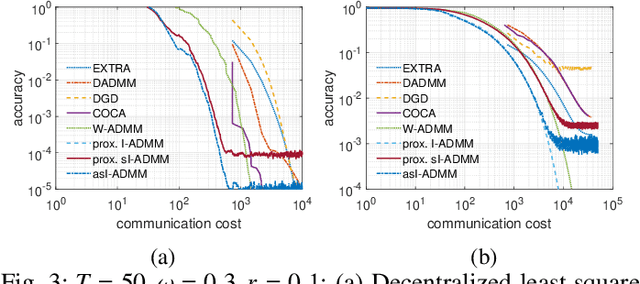
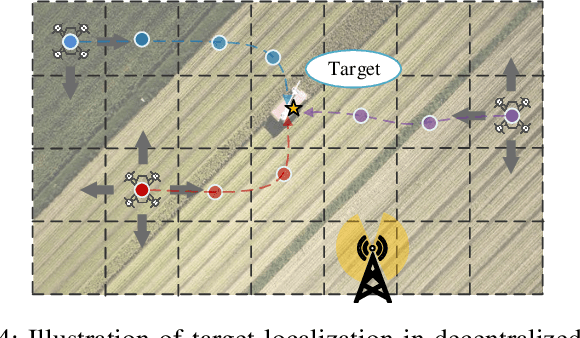
Edge computing provides a promising paradigm to support the implementation of Industrial Internet of Things (IIoT) by offloading tasks to nearby edge nodes. Meanwhile, the increasing network size makes it impractical for centralized data processing due to limited bandwidth, and consequently a decentralized learning scheme is preferable. Reinforcement learning (RL) has been widely investigated and shown to be a promising solution for decision-making and optimal control processes. For RL in a decentralized setup, edge nodes (agents) connected through a communication network aim to work collaboratively to find a policy to optimize the global reward as the sum of local rewards. However, communication costs, scalability and adaptation in complex environments with heterogeneous agents may significantly limit the performance of decentralized RL. Alternating direction method of multipliers (ADMM) has a structure that allows for decentralized implementation, and has shown faster convergence than gradient descent based methods. Therefore, we propose an adaptive stochastic incremental ADMM (asI-ADMM) algorithm and apply the asI-ADMM to decentralized RL with edge-computing-empowered IIoT networks. We provide convergence properties for proposed algorithms by designing a Lyapunov function and prove that the asI-ADMM has $O(\frac{1}{k}) +O(\frac{1}{M})$ convergence rate where $k$ and $ M$ are the number of iterations and batch samples, respectively. Then, we test our algorithm with two supervised learning problems. For performance evaluation, we simulate two applications in decentralized RL settings with homogeneous and heterogeneous agents. The experiment results show that our proposed algorithms outperform the state of the art in terms of communication costs and scalability, and can well adapt to complex IoT environments.
Coded Stochastic ADMM for Decentralized Consensus Optimization with Edge Computing
Oct 02, 2020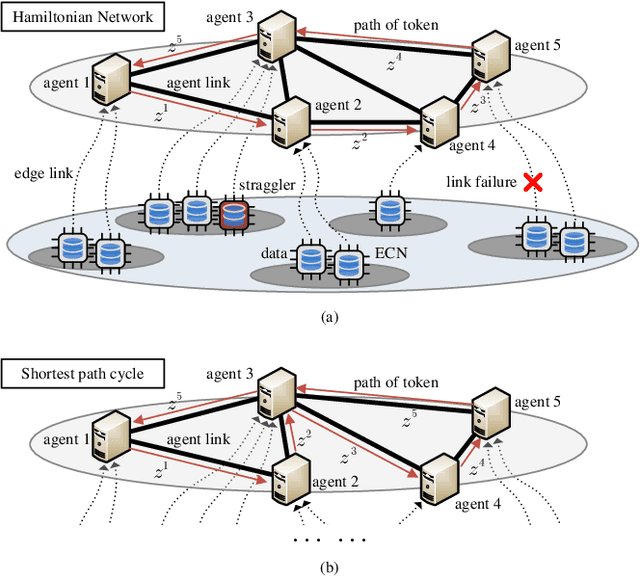
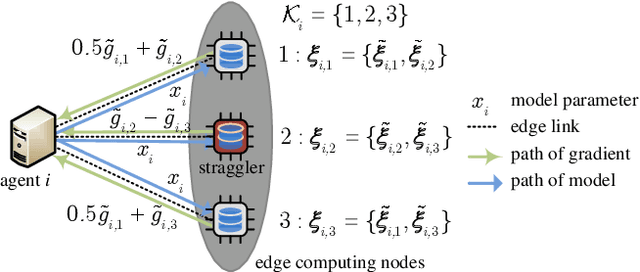


Big data, including applications with high security requirements, are often collected and stored on multiple heterogeneous devices, such as mobile devices, drones and vehicles. Due to the limitations of communication costs and security requirements, it is of paramount importance to extract information in a decentralized manner instead of aggregating data to a fusion center. To train large-scale machine learning models, edge/fog computing is often leveraged as an alternative to centralized learning. We consider the problem of learning model parameters in a multi-agent system with data locally processed via distributed edge nodes. A class of mini-batch stochastic alternating direction method of multipliers (ADMM) algorithms is explored to develop the distributed learning model. To address two main critical challenges in distributed networks, i.e., communication bottleneck and straggler nodes (nodes with slow responses), error-control-coding based stochastic incremental ADMM is investigated. Given an appropriate mini-batch size, we show that the mini-batch stochastic ADMM based method converges in a rate of $O(\frac{1}{\sqrt{k}})$, where $k$ denotes the number of iterations. Through numerical experiments, it is revealed that the proposed algorithm is communication-efficient, rapidly responding and robust in the presence of straggler nodes compared with state of the art algorithms.
Learning Based Hybrid Beamforming for Millimeter Wave Multi-User MIMO Systems
Apr 27, 2020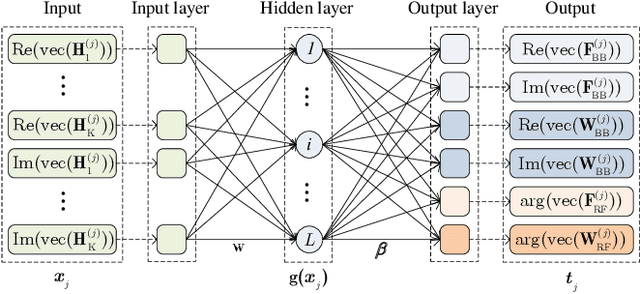


Hybrid beamforming (HBF) design is a crucial stage in millimeter wave (mmWave) multi-user multi-input multi-output (MU-MIMO) systems. However, conventional HBF methods are still with high complexity and strongly rely on the quality of channel state information. We propose an extreme learning machine (ELM) framework to jointly optimize transmitting and receiving beamformers. Specifically, to provide accurate labels for training, we first propose an factional-programming and majorization-minimization based HBF method (FP-MM-HBF). Then, an ELM based HBF (ELM-HBF) framework is proposed to increase the robustness of beamformers. Both FP-MM-HBF and ELM-HBF can provide higher system sum-rate compared with existing methods. Moreover, ELM-HBF cannot only provide robust HBF performance, but also consume very short computation time.
Learning Based Hybrid Beamforming Design for Full-Duplex Millimeter Wave Systems
Apr 16, 2020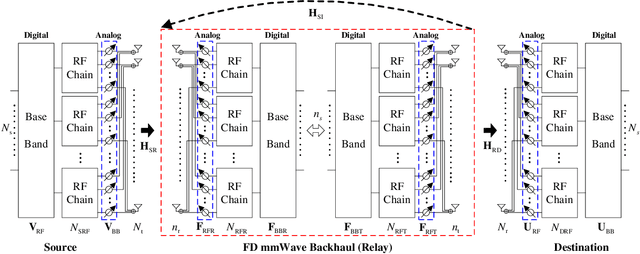
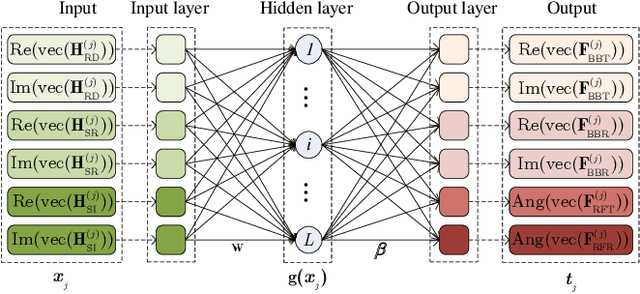
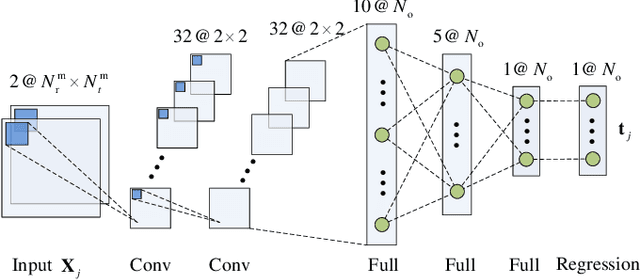

Millimeter Wave (mmWave) communications with full-duplex (FD) have the potential of increasing the spectral efficiency, relative to those with half-duplex. However, the residual self-interference (SI) from FD and high pathloss inherent to mmWave signals may degrade the system performance. Meanwhile, hybrid beamforming (HBF) is an efficient technology to enhance the channel gain and mitigate interference with reasonable complexity. However, conventional HBF approaches for FD mmWave systems are based on optimization processes, which are either too complex or strongly rely on the quality of channel state information (CSI). We propose two learning schemes to design HBF for FD mmWave systems, i.e., extreme learning machine based HBF (ELM-HBF) and convolutional neural networks based HBF (CNN-HBF). Specifically, we first propose an alternating direction method of multipliers (ADMM) based algorithm to achieve SI cancellation beamforming, and then use a majorization-minimization (MM) based algorithm for joint transmitting and receiving HBF optimization. To train the learning networks, we simulate noisy channels as input, and select the hybrid beamformers calculated by proposed algorithms as targets. Results show that both learning based schemes can provide more robust HBF performance and achieve at least 22.1% higher spectral efficiency compared to orthogonal matching pursuit (OMP) algorithms. Besides, the online prediction time of proposed learning based schemes is almost 20 times faster than the OMP scheme. Furthermore, the training time of ELM-HBF is about 600 times faster than that of CNN-HBF with 64 transmitting and receiving antennas.
Mobility-aware Content Preference Learning in Decentralized Caching Networks
Aug 22, 2019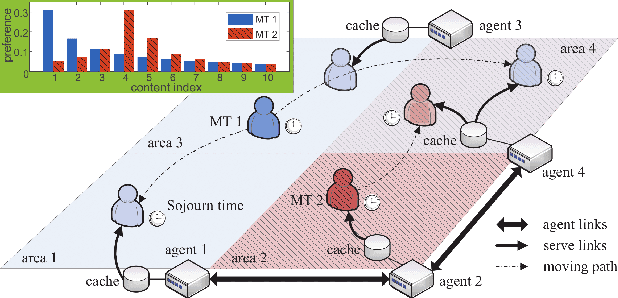


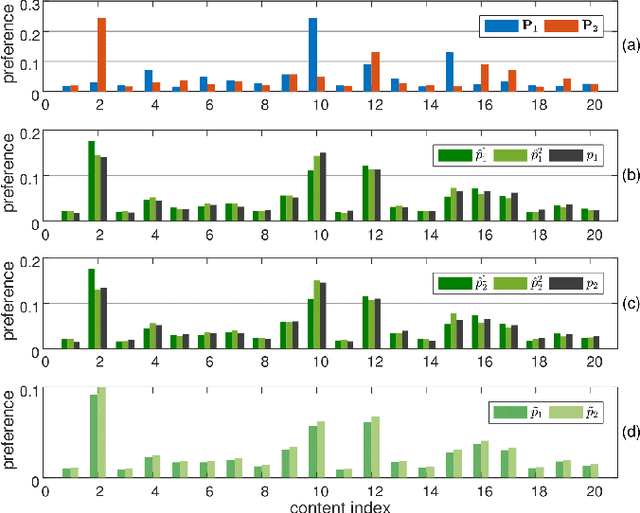
Due to the drastic increase of mobile traffic, wireless caching is proposed to serve repeated requests for content download. To determine the caching scheme for decentralized caching networks, the content preference learning problem based on mobility prediction is studied. We first formulate preference prediction as a decentralized regularized multi-task learning (DRMTL) problem without considering the mobility of mobile terminals (MTs). The problem is solved by a hybrid Jacobian and Gauss-Seidel proximal multi-block alternating direction method (ADMM) based algorithm, which is proven to conditionally converge to the optimal solution with a rate $O(1/k)$. Then we use the tool of \textit{Markov renewal process} to predict the moving path and sojourn time for MTs, and integrate the mobility pattern with the DRMTL model by reweighting the training samples and introducing a transfer penalty in the objective. We solve the problem and prove that the developed algorithm has the same convergence property but with different conditions. Through simulation we show the convergence analysis on proposed algorithms. Our real trace driven experiments illustrate that the mobility-aware DRMTL model can provide a more accurate prediction on geography preference than DRMTL model. Besides, the hit ratio achieved by most popular proactive caching (MPC) policy with preference predicted by mobility-aware DRMTL outperforms the MPC with preference from DRMTL and random caching (RC) schemes.