 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-ASR: Towards Low-Bit Quantization of Automatic Speech Recognition Models
Jul 10, 2025Recent advances in Automatic Speech Recognition (ASR) have demonstrated remarkable accuracy and robustness in diverse audio applications, such as live transcription and voice command processing. However, deploying these models on resource constrained edge devices (e.g., IoT device, wearables) still presents substantial challenges due to strict limits on memory, compute and power. Quantization, particularly Post-Training Quantization (PTQ), offers an effective way to reduce model size and inference cost without retraining. Despite its importance, the performance implications of various advanced quantization methods and bit-width configurations on ASR models remain unclear. In this work, we present a comprehensive benchmark of eight state-of-the-art (SOTA) PTQ methods applied to two leading edge-ASR model families, Whisper and Moonshine. We systematically evaluate model performances (i.e., accuracy, memory I/O and bit operations) across seven diverse datasets from the open ASR leaderboard, analyzing the impact of quantization and various configurations on both weights and activations. Built on an extension of the LLM compression toolkit, our framework integrates edge-ASR models, diverse advanced quantization algorithms, a unified calibration and evaluation data pipeline, and detailed analysis tools. Our results characterize the trade-offs between efficiency and accuracy, demonstrating that even 3-bit quantization can succeed on high capacity models when using advanced PTQ techniques. These findings provide valuable insights for optimizing ASR models on low-power, always-on edge devices.
OmniDraft: A Cross-vocabulary, Online Adaptive Drafter for On-device Speculative Decoding
Jul 03, 2025Speculative decoding generally dictates having a small, efficient draft model that is either pretrained or distilled offline to a particular target model series, for instance, Llama or Qwen models. However, within online deployment settings, there are two major challenges: 1) usage of a target model that is incompatible with the draft model; 2) expectation of latency improvements over usage and time. In this work, we propose OmniDraft, a unified framework that enables a single draft model to operate with any target model and adapt dynamically to user data. We introduce an online n-gram cache with hybrid distillation fine-tuning to address the cross-vocabulary mismatch across draft and target models; and further improve decoding speed by leveraging adaptive drafting techniques. OmniDraft is particularly suitable for on-device LLM applications where model cost, efficiency and user customization are the major points of contention. This further highlights the need to tackle the above challenges and motivates the \textit{``one drafter for all''} paradigm. We showcase the proficiency of the OmniDraft framework by performing online learning on math reasoning, coding and text generation tasks. Notably, OmniDraft enables a single Llama-68M model to pair with various target models including Vicuna-7B, Qwen2-7B and Llama3-8B models for speculative decoding; and additionally provides up to 1.5-2x speedup.
Stepping Forward on the Last Mile
Nov 06, 2024



Continuously adapting pre-trained models to local data on resource constrained edge devices is the $\emph{last mile}$ for model deployment. However, as models increase in size and depth, backpropagation requires a large amount of memory, which becomes prohibitive for edge devices. In addition, most existing low power neural processing engines (e.g., NPUs, DSPs, MCUs, etc.) are designed as fixed-point inference accelerators, without training capabilities. Forward gradients, solely based on directional derivatives computed from two forward calls, have been recently used for model training, with substantial savings in computation and memory. However, the performance of quantized training with fixed-point forward gradients remains unclear. In this paper, we investigate the feasibility of on-device training using fixed-point forward gradients, by conducting comprehensive experiments across a variety of deep learning benchmark tasks in both vision and audio domains. We propose a series of algorithm enhancements that further reduce the memory footprint, and the accuracy gap compared to backpropagation. An empirical study on how training with forward gradients navigates in the loss landscape is further explored. Our results demonstrate that on the last mile of model customization on edge devices, training with fixed-point forward gradients is a feasible and practical approach.
An Empirical Study of Low Precision Quantization for TinyML
Mar 10, 2022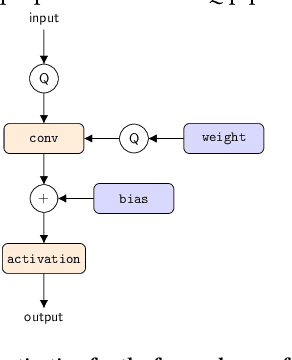

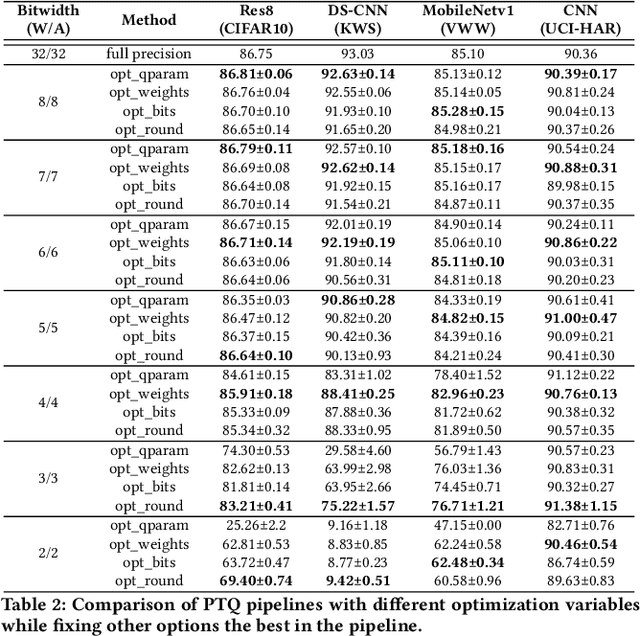
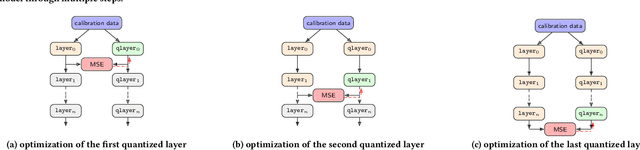
Tiny machine learning (tinyML) has emerged during the past few years aiming to deploy machine learning models to embedded AI processors with highly constrained memory and computation capacity. Low precision quantization is an important model compression technique that can greatly reduce both memory consumption and computation cost of model inference. In this study, we focus on post-training quantization (PTQ) algorithms that quantize a model to low-bit (less than 8-bit) precision with only a small set of calibration data and benchmark them on different tinyML use cases. To achieve a fair comparison, we build a simulated quantization framework to investigate recent PTQ algorithms. Furthermore, we break down those algorithms into essential components and re-assembled a generic PTQ pipeline. With ablation study on different alternatives of components in the pipeline, we reveal key design choices when performing low precision quantization. We hope this work could provide useful data points and shed lights on the future research of low precision quantization.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019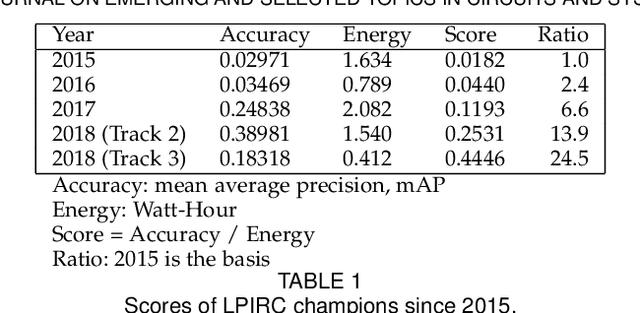
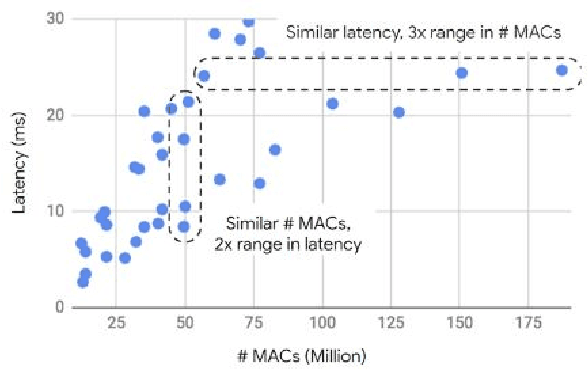
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
Low Power Inference for On-Device Visual Recognition with a Quantization-Friendly Solution
Mar 12, 2019
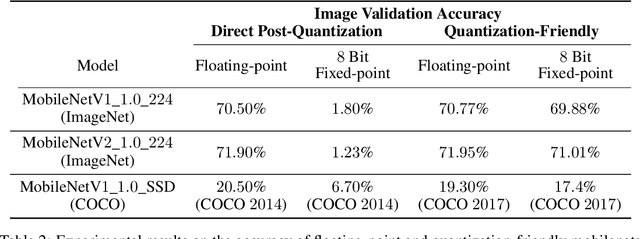
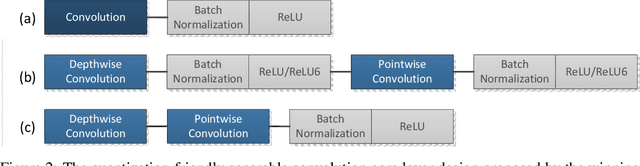
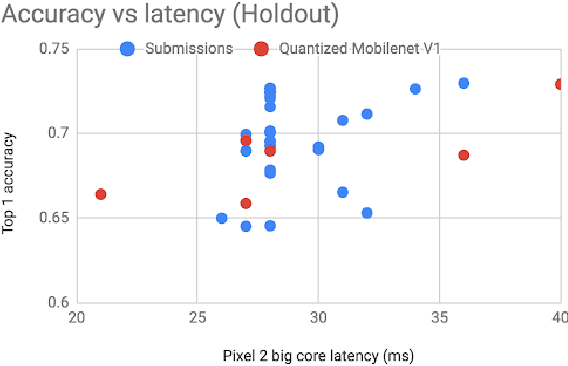
The IEEE Low-Power Image Recognition Challenge (LPIRC) is an annual competition started in 2015 that encourages joint hardware and software solutions for computer vision systems with low latency and power. Track 1 of the competition in 2018 focused on the innovation of software solutions with fixed inference engine and hardware. This decision allows participants to submit models online and not worry about building and bringing custom hardware on-site, which attracted a historically large number of submissions. Among the diverse solutions, the winning solution proposed a quantization-friendly framework for MobileNets that achieves an accuracy of 72.67% on the holdout dataset with an average latency of 27ms on a single CPU core of Google Pixel2 phone, which is superior to the best real-time MobileNet models at the time.
2018 Low-Power Image Recognition Challenge
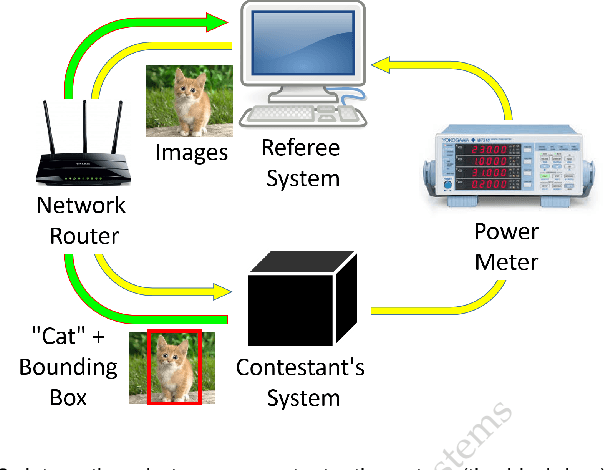
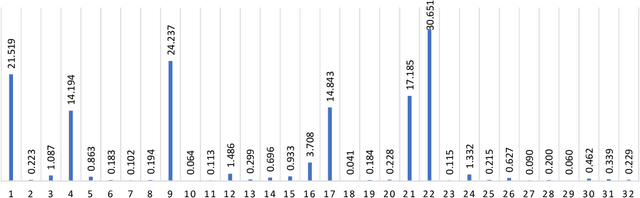
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.
A Quantization-Friendly Separable Convolution for MobileNets
Mar 22, 2018



As deep learning (DL) is being rapidly pushed to edge computing, researchers invented various ways to make inference computation more efficient on mobile/IoT devices, such as network pruning, parameter compression, and etc. Quantization, as one of the key approaches, can effectively offload GPU, and make it possible to deploy DL on fixed-point pipeline. Unfortunately, not all existing networks design are friendly to quantization. For example, the popular lightweight MobileNetV1, while it successfully reduces parameter size and computation latency with separable convolution, our experiment shows its quantized models have large accuracy gap against its float point models. To resolve this, we analyzed the root cause of quantization loss and proposed a quantization-friendly separable convolution architecture. By evaluating the image classification task on ImageNet2012 dataset, our modified MobileNetV1 model can archive 8-bit inference top-1 accuracy in 68.03%, almost closed the gap to the float pipeline.