 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-ASR: Towards Low-Bit Quantization of Automatic Speech Recognition Models
Jul 10, 2025Recent advances in Automatic Speech Recognition (ASR) have demonstrated remarkable accuracy and robustness in diverse audio applications, such as live transcription and voice command processing. However, deploying these models on resource constrained edge devices (e.g., IoT device, wearables) still presents substantial challenges due to strict limits on memory, compute and power. Quantization, particularly Post-Training Quantization (PTQ), offers an effective way to reduce model size and inference cost without retraining. Despite its importance, the performance implications of various advanced quantization methods and bit-width configurations on ASR models remain unclear. In this work, we present a comprehensive benchmark of eight state-of-the-art (SOTA) PTQ methods applied to two leading edge-ASR model families, Whisper and Moonshine. We systematically evaluate model performances (i.e., accuracy, memory I/O and bit operations) across seven diverse datasets from the open ASR leaderboard, analyzing the impact of quantization and various configurations on both weights and activations. Built on an extension of the LLM compression toolkit, our framework integrates edge-ASR models, diverse advanced quantization algorithms, a unified calibration and evaluation data pipeline, and detailed analysis tools. Our results characterize the trade-offs between efficiency and accuracy, demonstrating that even 3-bit quantization can succeed on high capacity models when using advanced PTQ techniques. These findings provide valuable insights for optimizing ASR models on low-power, always-on edge devices.
OmniDraft: A Cross-vocabulary, Online Adaptive Drafter for On-device Speculative Decoding
Jul 03, 2025Speculative decoding generally dictates having a small, efficient draft model that is either pretrained or distilled offline to a particular target model series, for instance, Llama or Qwen models. However, within online deployment settings, there are two major challenges: 1) usage of a target model that is incompatible with the draft model; 2) expectation of latency improvements over usage and time. In this work, we propose OmniDraft, a unified framework that enables a single draft model to operate with any target model and adapt dynamically to user data. We introduce an online n-gram cache with hybrid distillation fine-tuning to address the cross-vocabulary mismatch across draft and target models; and further improve decoding speed by leveraging adaptive drafting techniques. OmniDraft is particularly suitable for on-device LLM applications where model cost, efficiency and user customization are the major points of contention. This further highlights the need to tackle the above challenges and motivates the \textit{``one drafter for all''} paradigm. We showcase the proficiency of the OmniDraft framework by performing online learning on math reasoning, coding and text generation tasks. Notably, OmniDraft enables a single Llama-68M model to pair with various target models including Vicuna-7B, Qwen2-7B and Llama3-8B models for speculative decoding; and additionally provides up to 1.5-2x speedup.
Stepping Forward on the Last Mile
Nov 06, 2024



Continuously adapting pre-trained models to local data on resource constrained edge devices is the $\emph{last mile}$ for model deployment. However, as models increase in size and depth, backpropagation requires a large amount of memory, which becomes prohibitive for edge devices. In addition, most existing low power neural processing engines (e.g., NPUs, DSPs, MCUs, etc.) are designed as fixed-point inference accelerators, without training capabilities. Forward gradients, solely based on directional derivatives computed from two forward calls, have been recently used for model training, with substantial savings in computation and memory. However, the performance of quantized training with fixed-point forward gradients remains unclear. In this paper, we investigate the feasibility of on-device training using fixed-point forward gradients, by conducting comprehensive experiments across a variety of deep learning benchmark tasks in both vision and audio domains. We propose a series of algorithm enhancements that further reduce the memory footprint, and the accuracy gap compared to backpropagation. An empirical study on how training with forward gradients navigates in the loss landscape is further explored. Our results demonstrate that on the last mile of model customization on edge devices, training with fixed-point forward gradients is a feasible and practical approach.
Characterising the Robustness of Reinforcement Learning for Continuous Control using Disturbance Injection
Oct 27, 2022In this study, we leverage the deliberate and systematic fault-injection capabilities of an open-source benchmark suite to perform a series of experiments on state-of-the-art deep and robust reinforcement learning algorithms. We aim to benchmark robustness in the context of continuous action spaces -- crucial for deployment in robot control. We find that robustness is more prominent for action disturbances than it is for disturbances to observations and dynamics. We also observe that state-of-the-art approaches that are not explicitly designed to improve robustness perform at a level comparable to that achieved by those that are. Our study and results are intended to provide insight into the current state of safe and robust reinforcement learning and a foundation for the advancement of the field, in particular, for deployment in robotic systems.
safe-control-gym: a Unified Benchmark Suite for Safe Learning-based Control and Reinforcement Learning
Sep 18, 2021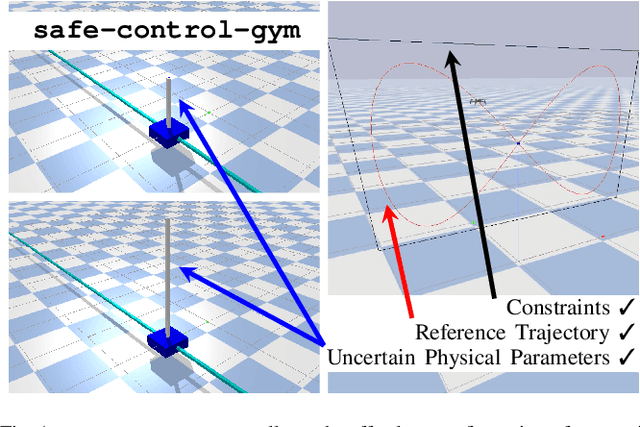
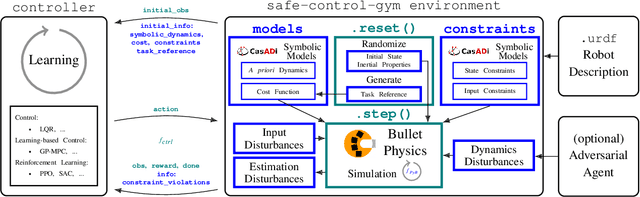
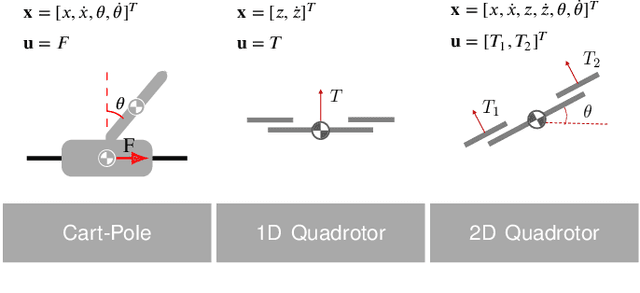
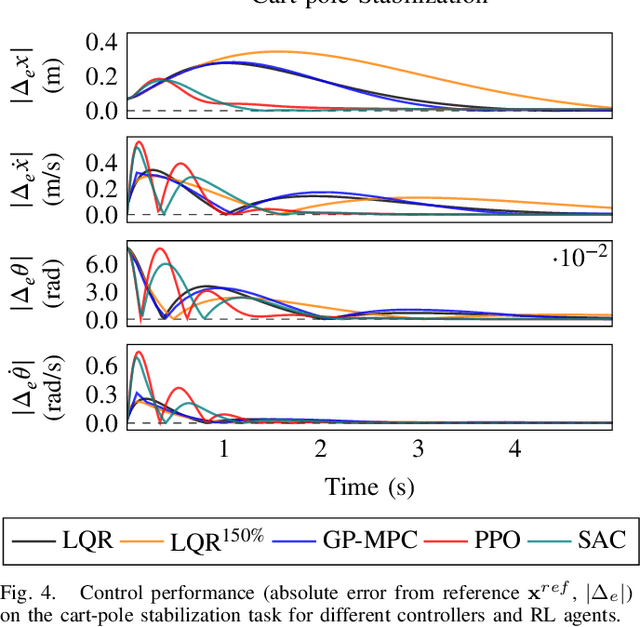
In recent years, reinforcement learning and learning-based control -- as well as the study of their safety, crucial for deployment in real-world robots -- have gained significant traction. However, to adequately gauge the progress and applicability of new results, we need the tools to equitably compare the approaches proposed by the controls and reinforcement learning communities. Here, we propose a new open-source benchmark suite, called safe-control-gym. Our starting point is OpenAI's Gym API, which is one of the de facto standard in reinforcement learning research. Yet, we highlight the reasons for its limited appeal to control theory researchers -- and safe control, in particular. E.g., the lack of analytical models and constraint specifications. Thus, we propose to extend this API with (i) the ability to specify (and query) symbolic models and constraints and (ii) introduce simulated disturbances in the control inputs, measurements, and inertial properties. We provide implementations for three dynamic systems -- the cart-pole, 1D, and 2D quadrotor -- and two control tasks -- stabilization and trajectory tracking. To demonstrate our proposal -- and in an attempt to bring research communities closer together -- we show how to use safe-control-gym to quantitatively compare the control performance, data efficiency, and safety of multiple approaches from the areas of traditional control, learning-based control, and reinforcement learning.
Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning
Aug 13, 2021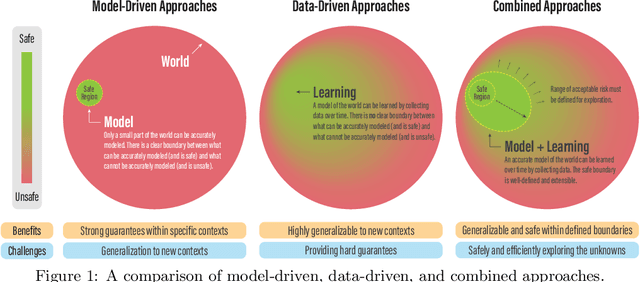
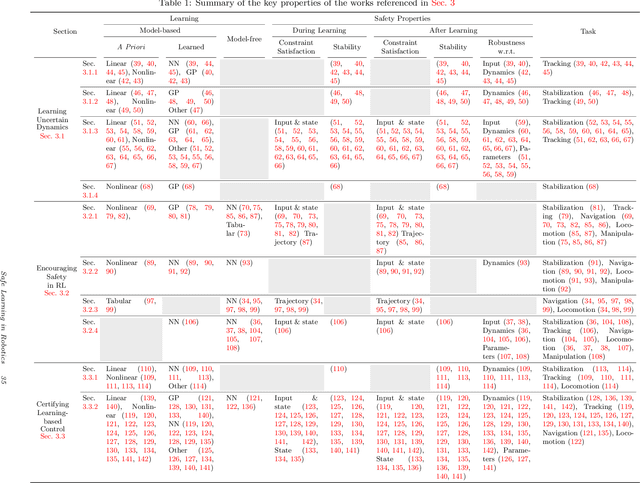
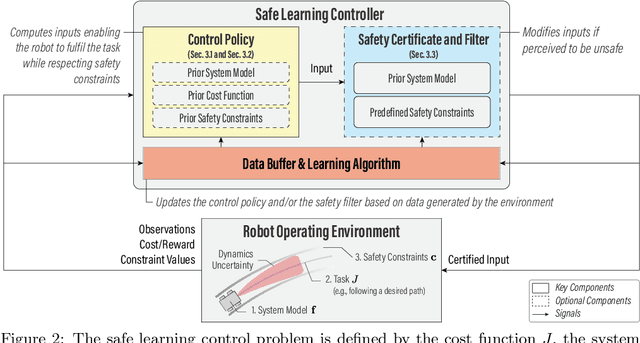
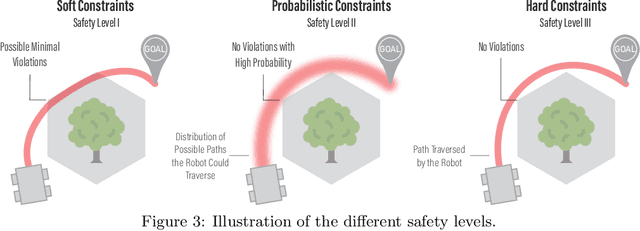
The last half-decade has seen a steep rise in the number of contributions on safe learning methods for real-world robotic deployments from both the control and reinforcement learning communities. This article provides a concise but holistic review of the recent advances made in using machine learning to achieve safe decision making under uncertainties, with a focus on unifying the language and frameworks used in control theory and reinforcement learning research. Our review includes: learning-based control approaches that safely improve performance by learning the uncertain dynamics, reinforcement learning approaches that encourage safety or robustness, and methods that can formally certify the safety of a learned control policy. As data- and learning-based robot control methods continue to gain traction, researchers must understand when and how to best leverage them in real-world scenarios where safety is imperative, such as when operating in close proximity to humans. We highlight some of the open challenges that will drive the field of robot learning in the coming years, and emphasize the need for realistic physics-based benchmarks to facilitate fair comparisons between control and reinforcement learning approaches.