 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Low Precision Quantization for TinyML
Paper and Code
Mar 10, 2022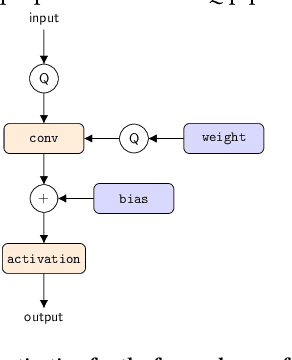

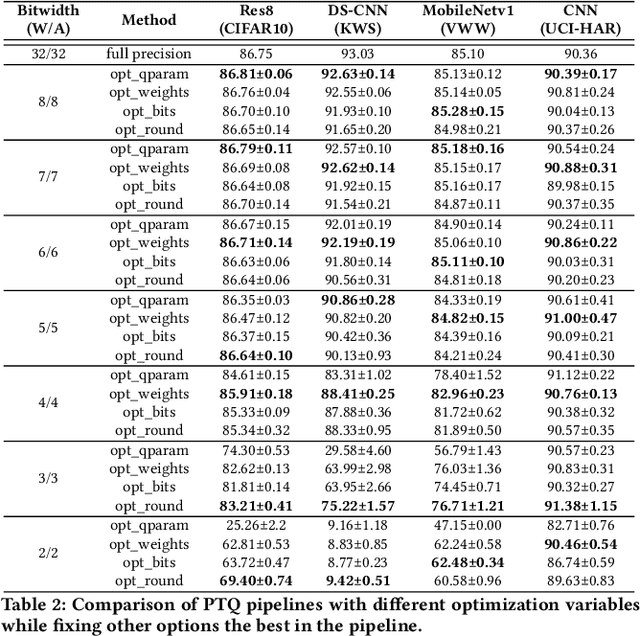
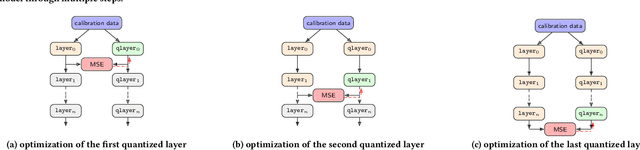
Tiny machine learning (tinyML) has emerged during the past few years aiming to deploy machine learning models to embedded AI processors with highly constrained memory and computation capacity. Low precision quantization is an important model compression technique that can greatly reduce both memory consumption and computation cost of model inference. In this study, we focus on post-training quantization (PTQ) algorithms that quantize a model to low-bit (less than 8-bit) precision with only a small set of calibration data and benchmark them on different tinyML use cases. To achieve a fair comparison, we build a simulated quantization framework to investigate recent PTQ algorithms. Furthermore, we break down those algorithms into essential components and re-assembled a generic PTQ pipeline. With ablation study on different alternatives of components in the pipeline, we reveal key design choices when performing low precision quantization. We hope this work could provide useful data points and shed lights on the future research of low precision quantization.