 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-ASR: Towards Low-Bit Quantization of Automatic Speech Recognition Models
Jul 10, 2025Recent advances in Automatic Speech Recognition (ASR) have demonstrated remarkable accuracy and robustness in diverse audio applications, such as live transcription and voice command processing. However, deploying these models on resource constrained edge devices (e.g., IoT device, wearables) still presents substantial challenges due to strict limits on memory, compute and power. Quantization, particularly Post-Training Quantization (PTQ), offers an effective way to reduce model size and inference cost without retraining. Despite its importance, the performance implications of various advanced quantization methods and bit-width configurations on ASR models remain unclear. In this work, we present a comprehensive benchmark of eight state-of-the-art (SOTA) PTQ methods applied to two leading edge-ASR model families, Whisper and Moonshine. We systematically evaluate model performances (i.e., accuracy, memory I/O and bit operations) across seven diverse datasets from the open ASR leaderboard, analyzing the impact of quantization and various configurations on both weights and activations. Built on an extension of the LLM compression toolkit, our framework integrates edge-ASR models, diverse advanced quantization algorithms, a unified calibration and evaluation data pipeline, and detailed analysis tools. Our results characterize the trade-offs between efficiency and accuracy, demonstrating that even 3-bit quantization can succeed on high capacity models when using advanced PTQ techniques. These findings provide valuable insights for optimizing ASR models on low-power, always-on edge devices.
OmniDraft: A Cross-vocabulary, Online Adaptive Drafter for On-device Speculative Decoding
Jul 03, 2025Speculative decoding generally dictates having a small, efficient draft model that is either pretrained or distilled offline to a particular target model series, for instance, Llama or Qwen models. However, within online deployment settings, there are two major challenges: 1) usage of a target model that is incompatible with the draft model; 2) expectation of latency improvements over usage and time. In this work, we propose OmniDraft, a unified framework that enables a single draft model to operate with any target model and adapt dynamically to user data. We introduce an online n-gram cache with hybrid distillation fine-tuning to address the cross-vocabulary mismatch across draft and target models; and further improve decoding speed by leveraging adaptive drafting techniques. OmniDraft is particularly suitable for on-device LLM applications where model cost, efficiency and user customization are the major points of contention. This further highlights the need to tackle the above challenges and motivates the \textit{``one drafter for all''} paradigm. We showcase the proficiency of the OmniDraft framework by performing online learning on math reasoning, coding and text generation tasks. Notably, OmniDraft enables a single Llama-68M model to pair with various target models including Vicuna-7B, Qwen2-7B and Llama3-8B models for speculative decoding; and additionally provides up to 1.5-2x speedup.
Why Not Replace? Sustaining Long-Term Visual Localization via Handcrafted-Learned Feature Collaboration on CPU
May 24, 2025Robust long-term visual localization in complex industrial environments is critical for mobile robotic systems. Existing approaches face limitations: handcrafted features are illumination-sensitive, learned features are computationally intensive, and semantic- or marker-based methods are environmentally constrained. Handcrafted and learned features share similar representations but differ functionally. Handcrafted features are optimized for continuous tracking, while learned features excel in wide-baseline matching. Their complementarity calls for integration rather than replacement. Building on this, we propose a hierarchical localization framework. It leverages real-time handcrafted feature extraction for relative pose estimation. In parallel, it employs selective learned keypoint detection on optimized keyframes for absolute positioning. This design enables CPU-efficient, long-term visual localization. Experiments systematically progress through three validation phases: Initially establishing feature complementarity through comparative analysis, followed by computational latency profiling across algorithm stages on CPU platforms. Final evaluation under photometric variations (including seasonal transitions and diurnal cycles) demonstrates 47% average error reduction with significantly improved localization consistency. The code implementation is publicly available at https://github.com/linyicheng1/ORB_SLAM3_localization.
ML-SceGen: A Multi-level Scenario Generation Framework
Jan 18, 2025



Current scientific research witnesses various attempts at applying Large Language Models for scenario generation but is inclined only to comprehensive or dangerous scenarios. In this paper, we seek to build a three-stage framework that not only lets users regain controllability over the generated scenarios but also generates comprehensive scenarios containing danger factors in uncontrolled intersection settings. In the first stage, LLM agents will contribute to translating the key components of the description of the expected scenarios into Functional Scenarios. For the second stage, we use Answer Set Programming (ASP) solver Clingo to help us generate comprehensive logical traffic within intersections. During the last stage, we use LLM to update relevant parameters to increase the critical level of the concrete scenario.
Solving Rubik's Cube Without Tricky Sampling
Nov 29, 2024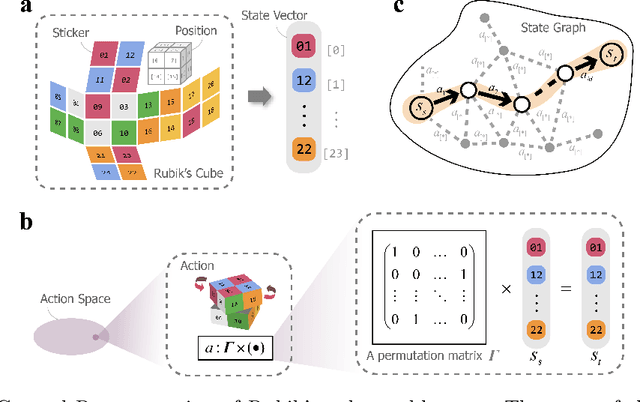
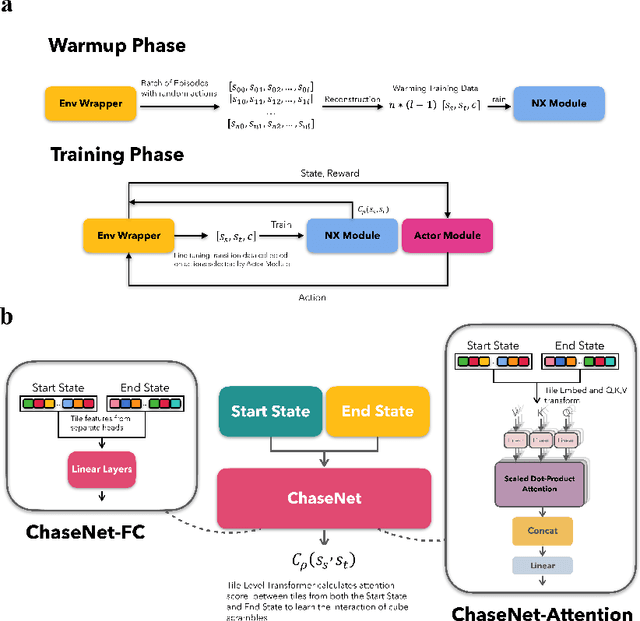
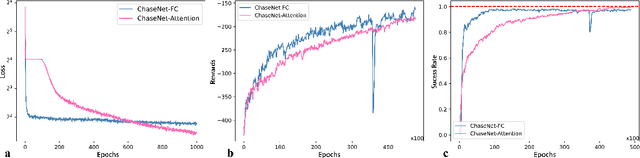
The Rubiks Cube, with its vast state space and sparse reward structure, presents a significant challenge for reinforcement learning (RL) due to the difficulty of reaching rewarded states. Previous research addressed this by propagating cost-to-go estimates from the solved state and incorporating search techniques. These approaches differ from human strategies that start from fully scrambled cubes, which can be tricky for solving a general sparse-reward problem. In this paper, we introduce a novel RL algorithm using policy gradient methods to solve the Rubiks Cube without relying on near solved-state sampling. Our approach employs a neural network to predict cost patterns between states, allowing the agent to learn directly from scrambled states. Our method was tested on the 2x2x2 Rubiks Cube, where the cube was scrambled 50,000 times, and the model successfully solved it in over 99.4% of cases. Notably, this result was achieved using only the policy network without relying on tree search as in previous methods, demonstrating its effectiveness and potential for broader applications in sparse-reward problems.
TCR-GPT: Integrating Autoregressive Model and Reinforcement Learning for T-Cell Receptor Repertoires Generation
Aug 02, 2024



T-cell receptors (TCRs) play a crucial role in the immune system by recognizing and binding to specific antigens presented by infected or cancerous cells. Understanding the sequence patterns of TCRs is essential for developing targeted immune therapies and designing effective vaccines. Language models, such as auto-regressive transformers, offer a powerful solution to this problem by learning the probability distributions of TCR repertoires, enabling the generation of new TCR sequences that inherit the underlying patterns of the repertoire. We introduce TCR-GPT, a probabilistic model built on a decoder-only transformer architecture, designed to uncover and replicate sequence patterns in TCR repertoires. TCR-GPT demonstrates an accuracy of 0.953 in inferring sequence probability distributions measured by Pearson correlation coefficient. Furthermore, by leveraging Reinforcement Learning(RL), we adapted the distribution of TCR sequences to generate TCRs capable of recognizing specific peptides, offering significant potential for advancing targeted immune therapies and vaccine development. With the efficacy of RL, fine-tuned pretrained TCR-GPT models demonstrated the ability to produce TCR repertoires likely to bind specific peptides, illustrating RL's efficiency in enhancing the model's adaptability to the probability distributions of biologically relevant TCR sequences.
Breaking of brightness consistency in optical flow with a lightweight CNN network
Oct 24, 2023
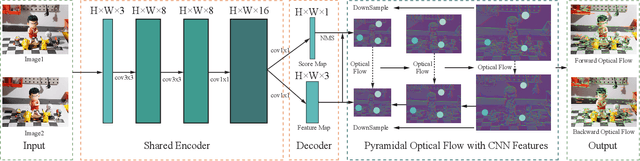
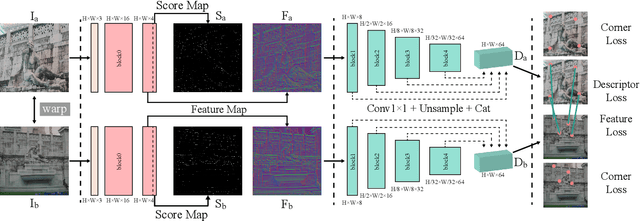

Sparse optical flow is widely used in various computer vision tasks, however assuming brightness consistency limits its performance in High Dynamic Range (HDR) environments. In this work, a lightweight network is used to extract illumination robust convolutional features and corners with strong invariance. Modifying the typical brightness consistency of the optical flow method to the convolutional feature consistency yields the light-robust hybrid optical flow method. The proposed network runs at 190 FPS on a commercial CPU because it uses only four convolutional layers to extract feature maps and score maps simultaneously. Since the shallow network is difficult to train directly, a deep network is designed to compute the reliability map that helps it. An end-to-end unsupervised training mode is used for both networks. To validate the proposed method, we compare corner repeatability and matching performance with origin optical flow under dynamic illumination. In addition, a more accurate visual inertial system is constructed by replacing the optical flow method in VINS-Mono. In a public HDR dataset, it reduces translation errors by 93\%. The code is publicly available at https://github.com/linyicheng1/LET-NET.
An Empirical Study of Low Precision Quantization for TinyML
Mar 10, 2022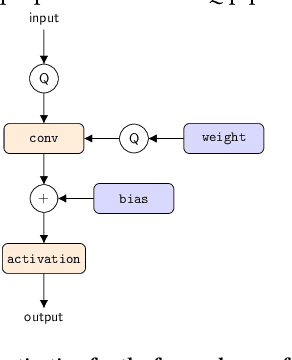

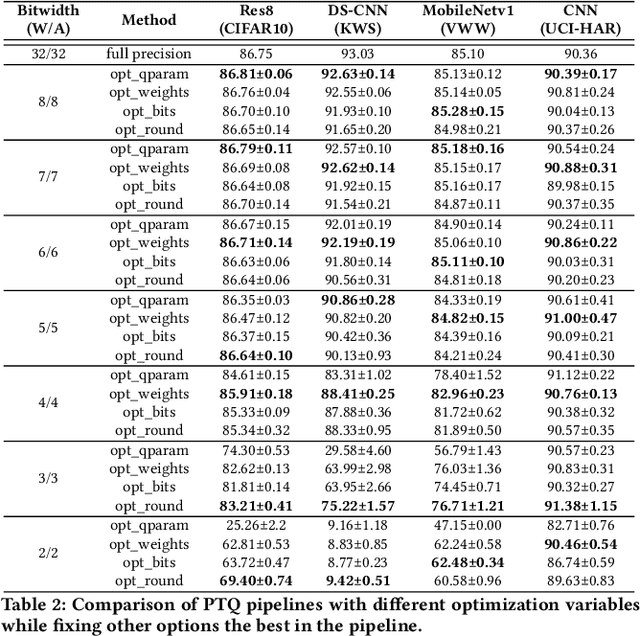
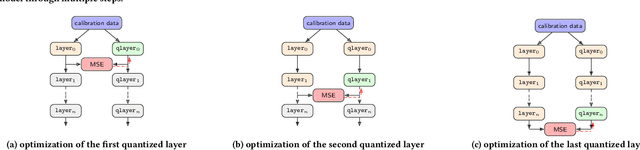
Tiny machine learning (tinyML) has emerged during the past few years aiming to deploy machine learning models to embedded AI processors with highly constrained memory and computation capacity. Low precision quantization is an important model compression technique that can greatly reduce both memory consumption and computation cost of model inference. In this study, we focus on post-training quantization (PTQ) algorithms that quantize a model to low-bit (less than 8-bit) precision with only a small set of calibration data and benchmark them on different tinyML use cases. To achieve a fair comparison, we build a simulated quantization framework to investigate recent PTQ algorithms. Furthermore, we break down those algorithms into essential components and re-assembled a generic PTQ pipeline. With ablation study on different alternatives of components in the pipeline, we reveal key design choices when performing low precision quantization. We hope this work could provide useful data points and shed lights on the future research of low precision quantization.