 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Rubik's Cube Without Tricky Sampling
Paper and Code
Nov 29, 2024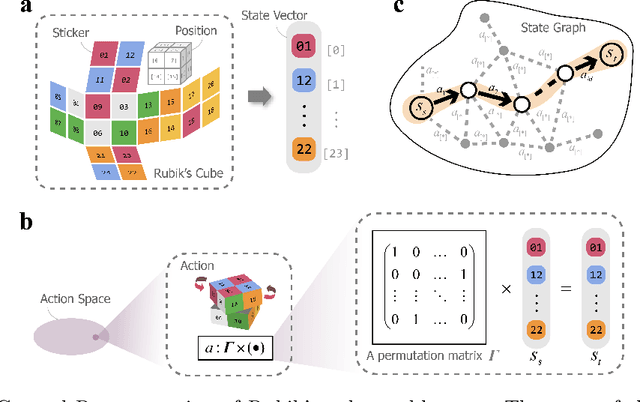
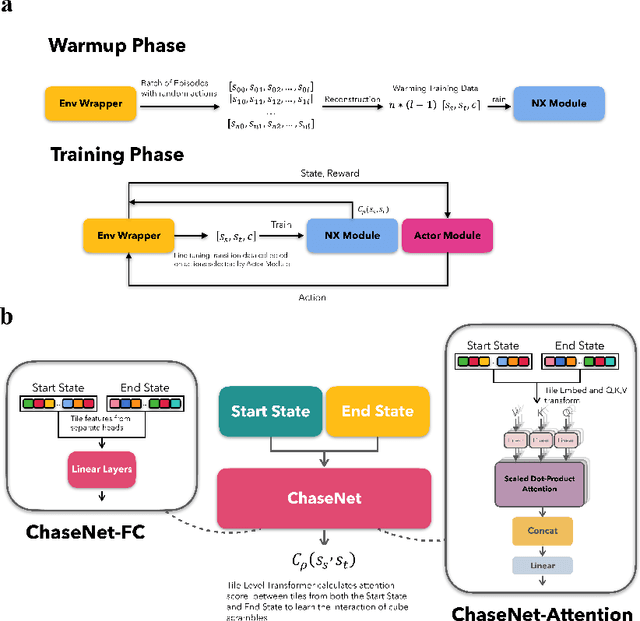
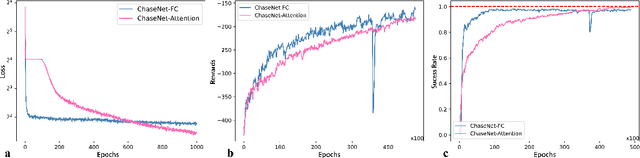
The Rubiks Cube, with its vast state space and sparse reward structure, presents a significant challenge for reinforcement learning (RL) due to the difficulty of reaching rewarded states. Previous research addressed this by propagating cost-to-go estimates from the solved state and incorporating search techniques. These approaches differ from human strategies that start from fully scrambled cubes, which can be tricky for solving a general sparse-reward problem. In this paper, we introduce a novel RL algorithm using policy gradient methods to solve the Rubiks Cube without relying on near solved-state sampling. Our approach employs a neural network to predict cost patterns between states, allowing the agent to learn directly from scrambled states. Our method was tested on the 2x2x2 Rubiks Cube, where the cube was scrambled 50,000 times, and the model successfully solved it in over 99.4% of cases. Notably, this result was achieved using only the policy network without relying on tree search as in previous methods, demonstrating its effectiveness and potential for broader applications in sparse-reward problems.