 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of Data Scaling: Sub-token Utilization and Acoustic Saturation in Multilingual ASR
Oct 26, 2025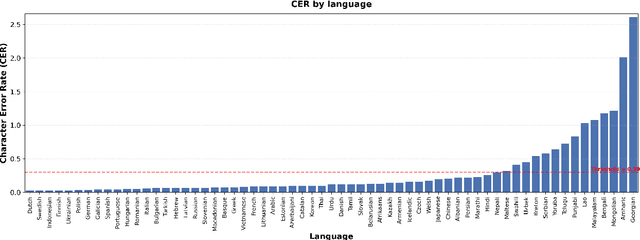
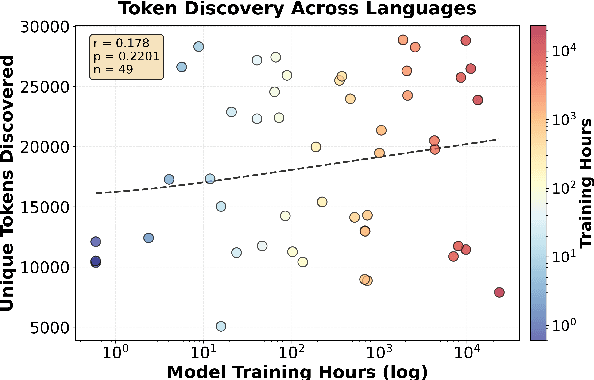
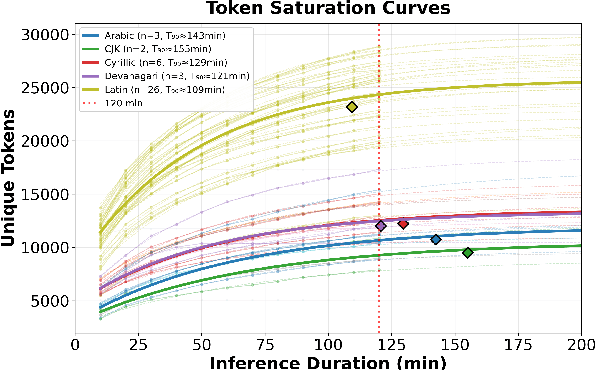
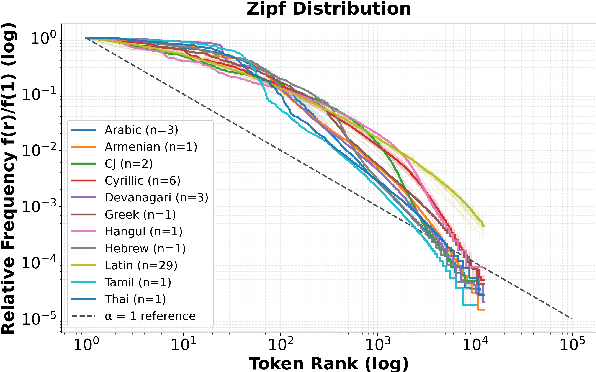
How much audio is needed to fully observe a multilingual ASR model's learned sub-token inventory across languages, and does data disparity in multilingual pre-training affect how these tokens are utilized during inference? We address this question by analyzing Whisper's decoding behavior during inference across 49 languages. By logging decoding candidate sub-tokens and tracking their cumulative discovery over time, we study the utilization pattern of the model's sub-token space. Results show that the total number of discovered tokens remains largely independent of a language's pre-training hours, indicating that data disparity does not strongly influence lexical diversity in the model's hypothesis space. Sub-token discovery rates follow a consistent exponential saturation pattern across languages, suggesting a stable time window after which additional audio yields minimal new sub-token activation. We refer to this convergence threshold as acoustic saturation time (AST). Further analyses of rank-frequency distributions reveal Zipf-like patterns better modeled by a Zipf-Mandelbrot law, and mean sub-token length shows a positive correlation with resource level. Additionally, those metrics show more favorable patterns for languages in the Latin script than those in scripts such as Cyrillic, CJK, and Semitic. Together, our study suggests that sub-token utilization during multilingual ASR inference is constrained more by the statistical, typological, and orthographic structure of the speech than by training data scale, providing an empirical basis for more equitable corpus construction and cross-lingual evaluation.
A Sociophonetic Analysis of Racial Bias in Commercial ASR Systems Using the Pacific Northwest English Corpus
Oct 26, 2025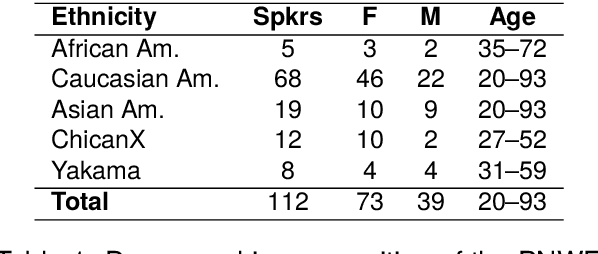
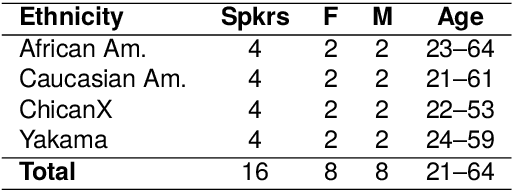
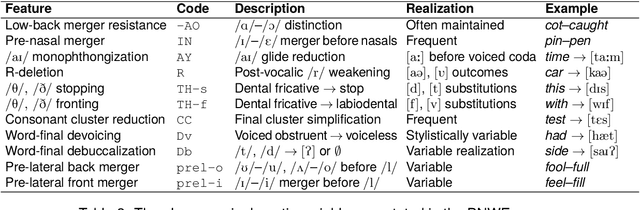

This paper presents a systematic evaluation of racial bias in four major commercial automatic speech recognition (ASR) systems using the Pacific Northwest English (PNWE) corpus. We analyze transcription accuracy across speakers from four ethnic backgrounds (African American, Caucasian American, ChicanX, and Yakama) and examine how sociophonetic variation contributes to differential system performance. We introduce a heuristically-determined Phonetic Error Rate (PER) metric that links recognition errors to specific linguistically motivated variables derived from sociophonetic annotation. Our analysis of eleven sociophonetic features reveals that vowel quality variation, particularly resistance to the low-back merger and pre-nasal merger patterns, is systematically associated with differential error rates across ethnic groups, with the most pronounced effects for African American speakers across all evaluated systems. These findings demonstrate that acoustic modeling of dialectal phonetic variation, rather than lexical or syntactic factors, remains a primary source of bias in commercial ASR systems. The study establishes the PNWE corpus as a valuable resource for bias evaluation in speech technologies and provides actionable guidance for improving ASR performance through targeted representation of sociophonetic diversity in training data.
The Tonogenesis Continuum in Tibetan: A Computational Investigation
Oct 26, 2025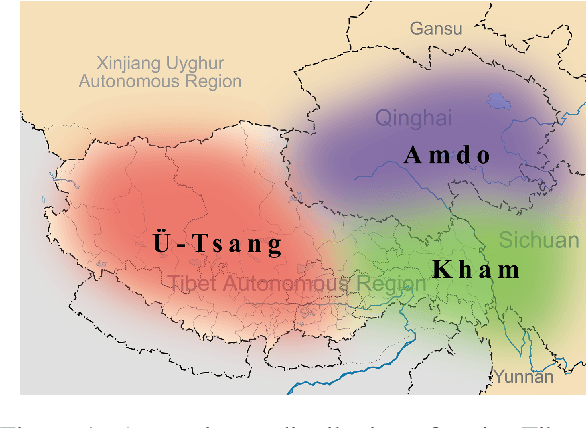



Tonogenesis-the historical process by which segmental contrasts evolve into lexical tone-has traditionally been studied through comparative reconstruction and acoustic phonetics. We introduce a computational approach that quantifies the functional role of pitch at different stages of this sound change by measuring how pitch manipulation affects automatic speech recognition (ASR) performance. Through analysis on the sensitivity to pitch-flattening from a set of closely related Tibetan languages, we find evidence of a tonogenesis continuum: atonal Amdo dialects tolerate pitch removal the most, while fully tonal U-Tsang varieties show severe degradation, and intermediate Kham dialects fall measurably between these extremes. These gradient effects demonstrate how ASR models implicitly learn the shifting functional load of pitch as languages transition from consonant-based to tone-based lexical contrasts. Our findings show that computational methods can capture fine-grained stages of sound change and suggest that traditional functional load metrics, based solely on minimal pairs, may overestimate pitch dependence in transitional systems where segmental and suprasegmental cues remain phonetically intertwined.
Generative Sign-description Prompts with Multi-positive Contrastive Learning for Sign Language Recognition
May 05, 2025Sign language recognition (SLR) faces fundamental challenges in creating accurate annotations due to the inherent complexity of simultaneous manual and non-manual signals. To the best of our knowledge, this is the first work to integrate generative large language models (LLMs) into SLR tasks. We propose a novel Generative Sign-description Prompts Multi-positive Contrastive learning (GSP-MC) method that leverages retrieval-augmented generation (RAG) with domain-specific LLMs, incorporating multi-step prompt engineering and expert-validated sign language corpora to produce precise multipart descriptions. The GSP-MC method also employs a dual-encoder architecture to bidirectionally align hierarchical skeleton features with multiple text descriptions (global, synonym, and part level) through probabilistic matching. Our approach combines global and part-level losses, optimizing KL divergence to ensure robust alignment across all relevant text-skeleton pairs while capturing both sign-level semantics and detailed part dynamics. Experiments demonstrate state-of-the-art performance against existing methods on the Chinese SLR500 (reaching 97.1%) and Turkish AUTSL datasets (97.07% accuracy). The method's cross-lingual effectiveness highlight its potential for developing inclusive communication technologies.
Solving Rubik's Cube Without Tricky Sampling
Nov 29, 2024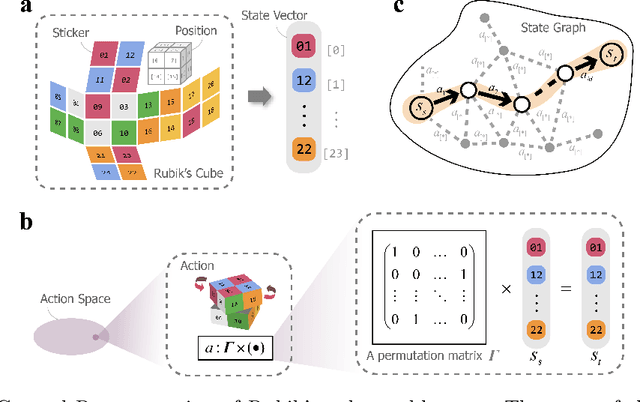
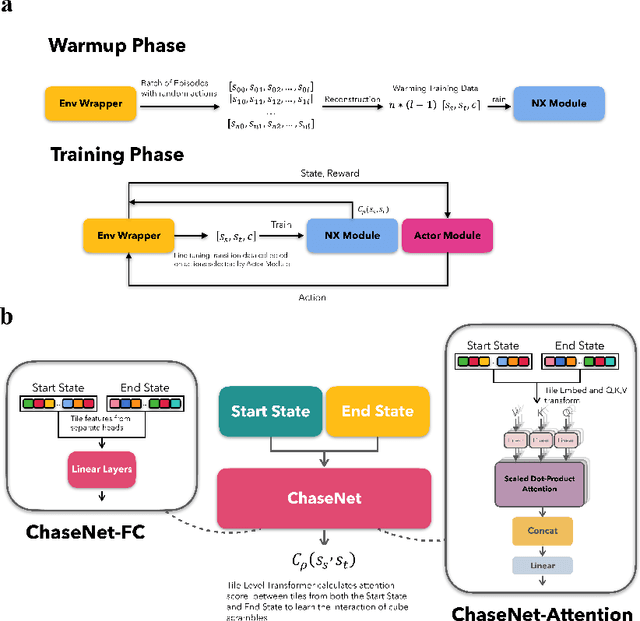
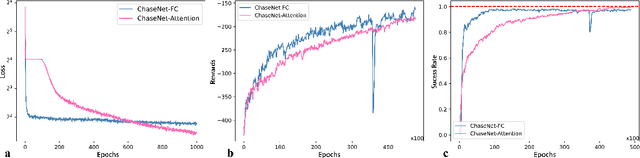
The Rubiks Cube, with its vast state space and sparse reward structure, presents a significant challenge for reinforcement learning (RL) due to the difficulty of reaching rewarded states. Previous research addressed this by propagating cost-to-go estimates from the solved state and incorporating search techniques. These approaches differ from human strategies that start from fully scrambled cubes, which can be tricky for solving a general sparse-reward problem. In this paper, we introduce a novel RL algorithm using policy gradient methods to solve the Rubiks Cube without relying on near solved-state sampling. Our approach employs a neural network to predict cost patterns between states, allowing the agent to learn directly from scrambled states. Our method was tested on the 2x2x2 Rubiks Cube, where the cube was scrambled 50,000 times, and the model successfully solved it in over 99.4% of cases. Notably, this result was achieved using only the policy network without relying on tree search as in previous methods, demonstrating its effectiveness and potential for broader applications in sparse-reward problems.
GWQ: Gradient-Aware Weight Quantization for Large Language Models
Oct 30, 2024
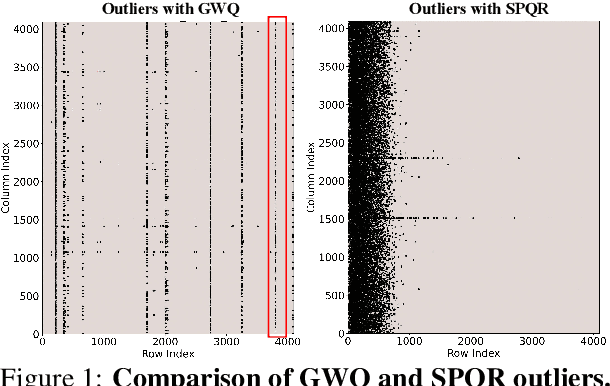
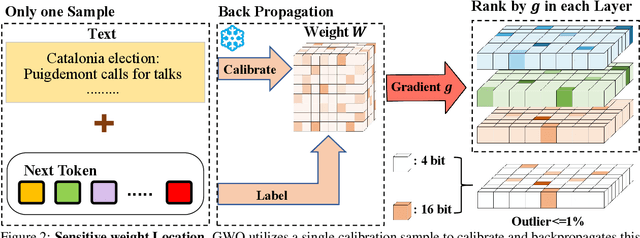
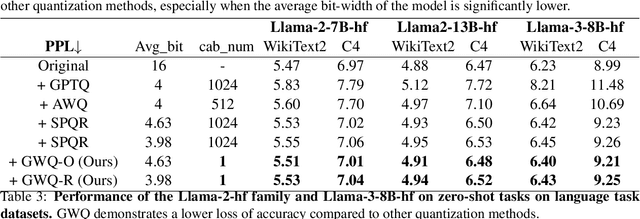
Large language models (LLMs) show impressive performance in solving complex languagetasks. However, its large number of parameterspresent significant challenges for the deployment and application of the model on edge devices. Compressing large language models to low bits can enable them to run on resource-constrained devices, often leading to performance degradation. To address this problem, we propose gradient-aware weight quantization (GWQ), the first quantization approach for low-bit weight quantization that leverages gradients to localize outliers, requiring only a minimal amount of calibration data for outlier detection. GWQ retains the weights corresponding to the top 1% outliers preferentially at FP16 precision, while the remaining non-outlier weights are stored in a low-bit format. GWQ found experimentally that utilizing the sensitive weights in the gradient localization model is more scientific compared to utilizing the sensitive weights in the Hessian matrix localization model. Compared to current quantization methods, GWQ can be applied to multiple language models and achieves lower PPL on the WikiText2 and C4 dataset. In the zero-shot task, GWQ quantized models have higher accuracy compared to other quantization methods.GWQ is also suitable for multimodal model quantization, and the quantized Qwen-VL family model is more accurate than other methods. zero-shot target detection task dataset RefCOCO outperforms the current stat-of-the-arts method SPQR. GWQ achieves 1.2x inference speedup in comparison to the original model, and effectively reduces the inference memory.
An Overview on Machine Learning Methods for Partial Differential Equations: from Physics Informed Neural Networks to Deep Operator Learning
Aug 23, 2024



The approximation of solutions of partial differential equations (PDEs) with numerical algorithms is a central topic in applied mathematics. For many decades, various types of methods for this purpose have been developed and extensively studied. One class of methods which has received a lot of attention in recent years are machine learning-based methods, which typically involve the training of artificial neural networks (ANNs) by means of stochastic gradient descent type optimization methods. While approximation methods for PDEs using ANNs have first been proposed in the 1990s they have only gained wide popularity in the last decade with the rise of deep learning. This article aims to provide an introduction to some of these methods and the mathematical theory on which they are based. We discuss methods such as physics-informed neural networks (PINNs) and deep BSDE methods and consider several operator learning approaches.