 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADAM: Parallel averaged Adam reduces the error for stochastic optimization in scientific machine learning
May 28, 2025Averaging techniques such as Ruppert--Polyak averaging and exponential movering averaging (EMA) are powerful approaches to accelerate optimization procedures of stochastic gradient descent (SGD) optimization methods such as the popular ADAM optimizer. However, depending on the specific optimization problem under consideration, the type and the parameters for the averaging need to be adjusted to achieve the smallest optimization error. In this work we propose an averaging approach, which we refer to as parallel averaged ADAM (PADAM), in which we compute parallely different averaged variants of ADAM and during the training process dynamically select the variant with the smallest optimization error. A central feature of this approach is that this procedure requires no more gradient evaluations than the usual ADAM optimizer as each of the averaged trajectories relies on the same underlying ADAM trajectory and thus on the same underlying gradients. We test the proposed PADAM optimizer in 13 stochastic optimization and deep neural network (DNN) learning problems and compare its performance with known optimizers from the literature such as standard SGD, momentum SGD, Adam with and without EMA, and ADAMW. In particular, we apply the compared optimizers to physics-informed neural network, deep Galerkin, deep backward stochastic differential equation and deep Kolmogorov approximations for boundary value partial differential equation problems from scientific machine learning, as well as to DNN approximations for optimal control and optimal stopping problems. In nearly all of the considered examples PADAM achieves, sometimes among others and sometimes exclusively, essentially the smallest optimization error. This work thus strongly suggest to consider PADAM for scientific machine learning problems and also motivates further research for adaptive averaging procedures within the training of DNNs.
Sharp higher order convergence rates for the Adam optimizer
Apr 28, 2025Gradient descent based optimization methods are the methods of choice to train deep neural networks in machine learning. Beyond the standard gradient descent method, also suitable modified variants of standard gradient descent involving acceleration techniques such as the momentum method and/or adaptivity techniques such as the RMSprop method are frequently considered optimization methods. These days the most popular of such sophisticated optimization schemes is presumably the Adam optimizer that has been proposed in 2014 by Kingma and Ba. A highly relevant topic of research is to investigate the speed of convergence of such optimization methods. In particular, in 1964 Polyak showed that the standard gradient descent method converges in a neighborhood of a strict local minimizer with rate (x - 1)(x + 1)^{-1} while momentum achieves the (optimal) strictly faster convergence rate (\sqrt{x} - 1)(\sqrt{x} + 1)^{-1} where x \in (1,\infty) is the condition number (the ratio of the largest and the smallest eigenvalue) of the Hessian of the objective function at the local minimizer. It is the key contribution of this work to reveal that Adam also converges with the strictly faster convergence rate (\sqrt{x} - 1)(\sqrt{x} + 1)^{-1} while RMSprop only converges with the convergence rate (x - 1)(x + 1)^{-1}.
Non-convergence to the optimal risk for Adam and stochastic gradient descent optimization in the training of deep neural networks
Mar 03, 2025Despite the omnipresent use of stochastic gradient descent (SGD) optimization methods in the training of deep neural networks (DNNs), it remains, in basically all practically relevant scenarios, a fundamental open problem to provide a rigorous theoretical explanation for the success (and the limitations) of SGD optimization methods in deep learning. In particular, it remains an open question to prove or disprove convergence of the true risk of SGD optimization methods to the optimal true risk value in the training of DNNs. In one of the main results of this work we reveal for a general class of activations, loss functions, random initializations, and SGD optimization methods (including, for example, standard SGD, momentum SGD, Nesterov accelerated SGD, Adagrad, RMSprop, Adadelta, Adam, Adamax, Nadam, Nadamax, and AMSGrad) that in the training of any arbitrary fully-connected feedforward DNN it does not hold that the true risk of the considered optimizer converges in probability to the optimal true risk value. Nonetheless, the true risk of the considered SGD optimization method may very well converge to a strictly suboptimal true risk value.
Averaged Adam accelerates stochastic optimization in the training of deep neural network approximations for partial differential equation and optimal control problems
Jan 10, 2025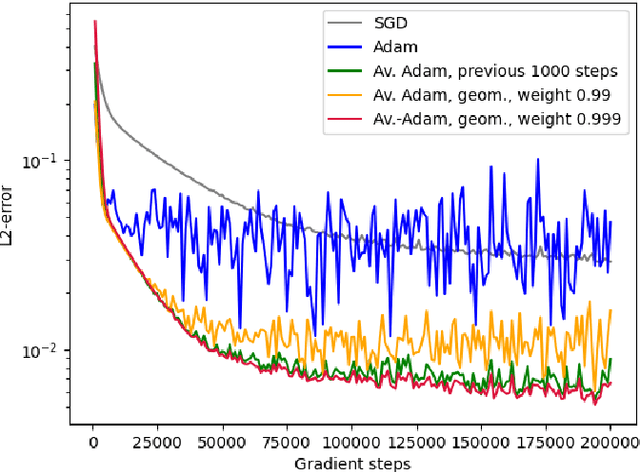
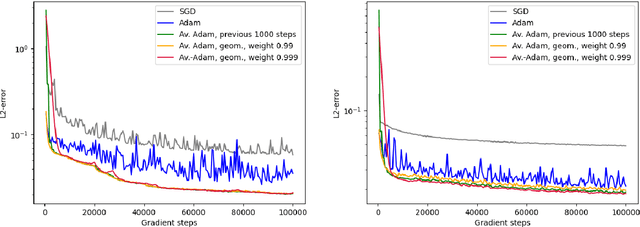
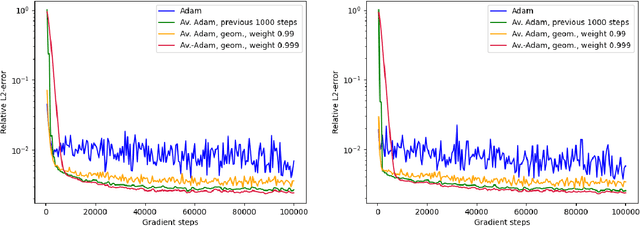
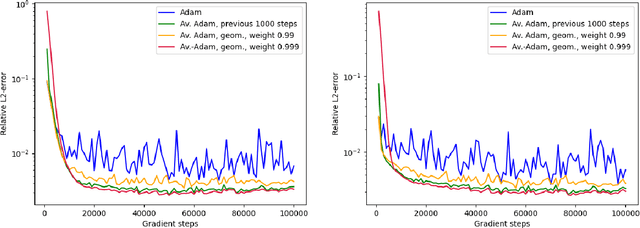
Deep learning methods - usually consisting of a class of deep neural networks (DNNs) trained by a stochastic gradient descent (SGD) optimization method - are nowadays omnipresent in data-driven learning problems as well as in scientific computing tasks such as optimal control (OC) and partial differential equation (PDE) problems. In practically relevant learning tasks, often not the plain-vanilla standard SGD optimization method is employed to train the considered class of DNNs but instead more sophisticated adaptive and accelerated variants of the standard SGD method such as the popular Adam optimizer are used. Inspired by the classical Polyak-Ruppert averaging approach, in this work we apply averaged variants of the Adam optimizer to train DNNs to approximately solve exemplary scientific computing problems in the form of PDEs and OC problems. We test the averaged variants of Adam in a series of learning problems including physics-informed neural network (PINN), deep backward stochastic differential equation (deep BSDE), and deep Kolmogorov approximations for PDEs (such as heat, Black-Scholes, Burgers, and Allen-Cahn PDEs), including DNN approximations for OC problems, and including DNN approximations for image classification problems (ResNet for CIFAR-10). In each of the numerical examples the employed averaged variants of Adam outperform the standard Adam and the standard SGD optimizers, particularly, in the situation of the scientific machine learning problems. The Python source codes for the numerical experiments associated to this work can be found on GitHub at https://github.com/deeplearningmethods/averaged-adam.
An Overview on Machine Learning Methods for Partial Differential Equations: from Physics Informed Neural Networks to Deep Operator Learning
Aug 23, 2024



The approximation of solutions of partial differential equations (PDEs) with numerical algorithms is a central topic in applied mathematics. For many decades, various types of methods for this purpose have been developed and extensively studied. One class of methods which has received a lot of attention in recent years are machine learning-based methods, which typically involve the training of artificial neural networks (ANNs) by means of stochastic gradient descent type optimization methods. While approximation methods for PDEs using ANNs have first been proposed in the 1990s they have only gained wide popularity in the last decade with the rise of deep learning. This article aims to provide an introduction to some of these methods and the mathematical theory on which they are based. We discuss methods such as physics-informed neural networks (PINNs) and deep BSDE methods and consider several operator learning approaches.
Learning rate adaptive stochastic gradient descent optimization methods: numerical simulations for deep learning methods for partial differential equations and convergence analyses
Jun 20, 2024



It is known that the standard stochastic gradient descent (SGD) optimization method, as well as accelerated and adaptive SGD optimization methods such as the Adam optimizer fail to converge if the learning rates do not converge to zero (as, for example, in the situation of constant learning rates). Numerical simulations often use human-tuned deterministic learning rate schedules or small constant learning rates. The default learning rate schedules for SGD optimization methods in machine learning implementation frameworks such as TensorFlow and Pytorch are constant learning rates. In this work we propose and study a learning-rate-adaptive approach for SGD optimization methods in which the learning rate is adjusted based on empirical estimates for the values of the objective function of the considered optimization problem (the function that one intends to minimize). In particular, we propose a learning-rate-adaptive variant of the Adam optimizer and implement it in case of several neural network learning problems, particularly, in the context of deep learning approximation methods for partial differential equations such as deep Kolmogorov methods, physics-informed neural networks, and deep Ritz methods. In each of the presented learning problems the proposed learning-rate-adaptive variant of the Adam optimizer faster reduces the value of the objective function than the Adam optimizer with the default learning rate. For a simple class of quadratic minimization problems we also rigorously prove that a learning-rate-adaptive variant of the SGD optimization method converges to the minimizer of the considered minimization problem. Our convergence proof is based on an analysis of the laws of invariant measures of the SGD method as well as on a more general convergence analysis for SGD with random but predictable learning rates which we develop in this work.
Non-convergence to global minimizers for Adam and stochastic gradient descent optimization and constructions of local minimizers in the training of artificial neural networks
Feb 07, 2024Stochastic gradient descent (SGD) optimization methods such as the plain vanilla SGD method and the popular Adam optimizer are nowadays the method of choice in the training of artificial neural networks (ANNs). Despite the remarkable success of SGD methods in the ANN training in numerical simulations, it remains in essentially all practical relevant scenarios an open problem to rigorously explain why SGD methods seem to succeed to train ANNs. In particular, in most practically relevant supervised learning problems, it seems that SGD methods do with high probability not converge to global minimizers in the optimization landscape of the ANN training problem. Nevertheless, it remains an open problem of research to disprove the convergence of SGD methods to global minimizers. In this work we solve this research problem in the situation of shallow ANNs with the rectified linear unit (ReLU) and related activations with the standard mean square error loss by disproving in the training of such ANNs that SGD methods (such as the plain vanilla SGD, the momentum SGD, the AdaGrad, the RMSprop, and the Adam optimizers) can find a global minimizer with high probability. Even stronger, we reveal in the training of such ANNs that SGD methods do with high probability fail to converge to global minimizers in the optimization landscape. The findings of this work do, however, not disprove that SGD methods succeed to train ANNs since they do not exclude the possibility that SGD methods find good local minimizers whose risk values are close to the risk values of the global minimizers. In this context, another key contribution of this work is to establish the existence of a hierarchical structure of local minimizers with distinct risk values in the optimization landscape of ANN training problems with ReLU and related activations.
Deep neural network approximation of composite functions without the curse of dimensionality
Apr 12, 2023In this article we identify a general class of high-dimensional continuous functions that can be approximated by deep neural networks (DNNs) with the rectified linear unit (ReLU) activation without the curse of dimensionality. In other words, the number of DNN parameters grows at most polynomially in the input dimension and the approximation error. The functions in our class can be expressed as a potentially unbounded number of compositions of special functions which include products, maxima, and certain parallelized Lipschitz continuous functions.
Algorithmically Designed Artificial Neural Networks (ADANNs): Higher order deep operator learning for parametric partial differential equations
Feb 07, 2023In this article we propose a new deep learning approach to solve parametric partial differential equations (PDEs) approximately. In particular, we introduce a new strategy to design specific artificial neural network (ANN) architectures in conjunction with specific ANN initialization schemes which are tailor-made for the particular scientific computing approximation problem under consideration. In the proposed approach we combine efficient classical numerical approximation techniques such as higher-order Runge-Kutta schemes with sophisticated deep (operator) learning methodologies such as the recently introduced Fourier neural operators (FNOs). Specifically, we introduce customized adaptions of existing standard ANN architectures together with specialized initializations for these ANN architectures so that at initialization we have that the ANNs closely mimic a chosen efficient classical numerical algorithm for the considered approximation problem. The obtained ANN architectures and their initialization schemes are thus strongly inspired by numerical algorithms as well as by popular deep learning methodologies from the literature and in that sense we refer to the introduced ANNs in conjunction with their tailor-made initialization schemes as Algorithmically Designed Artificial Neural Networks (ADANNs). We numerically test the proposed ADANN approach in the case of some parametric PDEs. In the tested numerical examples the ADANN approach significantly outperforms existing traditional approximation algorithms as well as existing deep learning methodologies from the literature.
Normalized gradient flow optimization in the training of ReLU artificial neural networks
Jul 13, 2022
The training of artificial neural networks (ANNs) is nowadays a highly relevant algorithmic procedure with many applications in science and industry. Roughly speaking, ANNs can be regarded as iterated compositions between affine linear functions and certain fixed nonlinear functions, which are usually multidimensional versions of a one-dimensional so-called activation function. The most popular choice of such a one-dimensional activation function is the rectified linear unit (ReLU) activation function which maps a real number to its positive part $ \mathbb{R} \ni x \mapsto \max\{ x, 0 \} \in \mathbb{R} $. In this article we propose and analyze a modified variant of the standard training procedure of such ReLU ANNs in the sense that we propose to restrict the negative gradient flow dynamics to a large submanifold of the ANN parameter space, which is a strict $ C^{ \infty } $-submanifold of the entire ANN parameter space that seems to enjoy better regularity properties than the entire ANN parameter space but which is also sufficiently large and sufficiently high dimensional so that it can represent all ANN realization functions that can be represented through the entire ANN parameter space. In the special situation of shallow ANNs with just one-dimensional ANN layers we also prove for every Lipschitz continuous target function that every gradient flow trajectory on this large submanifold of the ANN parameter space is globally bounded. For the standard gradient flow on the entire ANN parameter space with Lipschitz continuous target functions it remains an open problem of research to prove or disprove the global boundedness of gradient flow trajectories even in the situation of shallow ANNs with just one-dimensional ANN layers.