 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform a priori bounds and error analysis for the Adam stochastic gradient descent optimization method
Mar 19, 2026The adaptive moment estimation (Adam) optimizer proposed by Kingma & Ba (2014) is presumably the most popular stochastic gradient descent (SGD) optimization method for the training of deep neural networks (DNNs) in artificial intelligence (AI) systems. Despite its groundbreaking success in the training of AI systems, it still remains an open research problem to provide a complete error analysis of Adam, not only for optimizing DNNs but even when applied to strongly convex stochastic optimization problems (SOPs). Previous error analysis results for strongly convex SOPs in the literature provide conditional convergence analyses that rely on the assumption that Adam does not diverge to infinity but remains uniformly bounded. It is the key contribution of this work to establish uniform a priori bounds for Adam and, thereby, to provide -- for the first time -- an unconditional error analysis for Adam for a large class of strongly convex SOPs.
Physics-informed diffusion models in spectral space
Feb 10, 2026We propose a methodology that combines generative latent diffusion models with physics-informed machine learning to generate solutions of parametric partial differential equations (PDEs) conditioned on partial observations, which includes, in particular, forward and inverse PDE problems. We learn the joint distribution of PDE parameters and solutions via a diffusion process in a latent space of scaled spectral representations, where Gaussian noise corresponds to functions with controlled regularity. This spectral formulation enables significant dimensionality reduction compared to grid-based diffusion models and ensures that the induced process in function space remains within a class of functions for which the PDE operators are well defined. Building on diffusion posterior sampling, we enforce physics-informed constraints and measurement conditions during inference, applying Adam-based updates at each diffusion step. We evaluate the proposed approach on Poisson, Helmholtz, and incompressible Navier--Stokes equations, demonstrating improved accuracy and computational efficiency compared with existing diffusion-based PDE solvers, which are state of the art for sparse observations. Code is available at https://github.com/deeplearningmethods/PISD.
Adam symmetry theorem: characterization of the convergence of the stochastic Adam optimizer
Nov 10, 2025Beside the standard stochastic gradient descent (SGD) method, the Adam optimizer due to Kingma & Ba (2014) is currently probably the best-known optimization method for the training of deep neural networks in artificial intelligence (AI) systems. Despite the popularity and the success of Adam it remains an \emph{open research problem} to provide a rigorous convergence analysis for Adam even for the class of strongly convex SOPs. In one of the main results of this work we establish convergence rates for Adam in terms of the number of gradient steps (convergence rate \nicefrac{1}{2} w.r.t. the size of the learning rate), the size of the mini-batches (convergence rate 1 w.r.t. the size of the mini-batches), and the size of the second moment parameter of Adam (convergence rate 1 w.r.t. the distance of the second moment parameter to 1) for the class of strongly convex SOPs. In a further main result of this work, which we refer to as \emph{Adam symmetry theorem}, we illustrate the optimality of the established convergence rates by proving for a special class of simple quadratic strongly convex SOPs that Adam converges as the number of gradient steps increases to infinity to the solution of the SOP (the unique minimizer of the strongly convex objective function) if and \emph{only} if the random variables in the SOP (the data in the SOP) are \emph{symmetrically distributed}. In particular, in the standard case where the random variables in the SOP are not symmetrically distributed we \emph{disprove} that Adam converges to the minimizer of the SOP as the number of Adam steps increases to infinity. We also complement the conclusions of our convergence analysis and the Adam symmetry theorem by several numerical simulations that indicate the sharpness of the established convergence rates and that illustrate the practical appearance of the phenomena revealed in the \emph{Adam symmetry theorem}.
ODE approximation for the Adam algorithm: General and overparametrized setting
Nov 06, 2025The Adam optimizer is currently presumably the most popular optimization method in deep learning. In this article we develop an ODE based method to study the Adam optimizer in a fast-slow scaling regime. For fixed momentum parameters and vanishing step-sizes, we show that the Adam algorithm is an asymptotic pseudo-trajectory of the flow of a particular vector field, which is referred to as the Adam vector field. Leveraging properties of asymptotic pseudo-trajectories, we establish convergence results for the Adam algorithm. In particular, in a very general setting we show that if the Adam algorithm converges, then the limit must be a zero of the Adam vector field, rather than a local minimizer or critical point of the objective function. In contrast, in the overparametrized empirical risk minimization setting, the Adam algorithm is able to locally find the set of minima. Specifically, we show that in a neighborhood of the global minima, the objective function serves as a Lyapunov function for the flow induced by the Adam vector field. As a consequence, if the Adam algorithm enters a neighborhood of the global minima infinitely often, it converges to the set of global minima.
Error analysis for the deep Kolmogorov method
Aug 23, 2025The deep Kolmogorov method is a simple and popular deep learning based method for approximating solutions of partial differential equations (PDEs) of the Kolmogorov type. In this work we provide an error analysis for the deep Kolmogorov method for heat PDEs. Specifically, we reveal convergence with convergence rates for the overall mean square distance between the exact solution of the heat PDE and the realization function of the approximating deep neural network (DNN) associated with a stochastic optimization algorithm in terms of the size of the architecture (the depth/number of hidden layers and the width of the hidden layers) of the approximating DNN, in terms of the number of random sample points used in the loss function (the number of input-output data pairs used in the loss function), and in terms of the size of the optimization error made by the employed stochastic optimization method.
PADAM: Parallel averaged Adam reduces the error for stochastic optimization in scientific machine learning
May 28, 2025



Averaging techniques such as Ruppert--Polyak averaging and exponential movering averaging (EMA) are powerful approaches to accelerate optimization procedures of stochastic gradient descent (SGD) optimization methods such as the popular ADAM optimizer. However, depending on the specific optimization problem under consideration, the type and the parameters for the averaging need to be adjusted to achieve the smallest optimization error. In this work we propose an averaging approach, which we refer to as parallel averaged ADAM (PADAM), in which we compute parallely different averaged variants of ADAM and during the training process dynamically select the variant with the smallest optimization error. A central feature of this approach is that this procedure requires no more gradient evaluations than the usual ADAM optimizer as each of the averaged trajectories relies on the same underlying ADAM trajectory and thus on the same underlying gradients. We test the proposed PADAM optimizer in 13 stochastic optimization and deep neural network (DNN) learning problems and compare its performance with known optimizers from the literature such as standard SGD, momentum SGD, Adam with and without EMA, and ADAMW. In particular, we apply the compared optimizers to physics-informed neural network, deep Galerkin, deep backward stochastic differential equation and deep Kolmogorov approximations for boundary value partial differential equation problems from scientific machine learning, as well as to DNN approximations for optimal control and optimal stopping problems. In nearly all of the considered examples PADAM achieves, sometimes among others and sometimes exclusively, essentially the smallest optimization error. This work thus strongly suggest to consider PADAM for scientific machine learning problems and also motivates further research for adaptive averaging procedures within the training of DNNs.
SAD Neural Networks: Divergent Gradient Flows and Asymptotic Optimality via o-minimal Structures
May 14, 2025


We study gradient flows for loss landscapes of fully connected feed forward neural networks with commonly used continuously differentiable activation functions such as the logistic, hyperbolic tangent, softplus or GELU function. We prove that the gradient flow either converges to a critical point or diverges to infinity while the loss converges to an asymptotic critical value. Moreover, we prove the existence of a threshold $\varepsilon>0$ such that the loss value of any gradient flow initialized at most $\varepsilon$ above the optimal level converges to it. For polynomial target functions and sufficiently big architecture and data set, we prove that the optimal loss value is zero and can only be realized asymptotically. From this setting, we deduce our main result that any gradient flow with sufficiently good initialization diverges to infinity. Our proof heavily relies on the geometry of o-minimal structures. We confirm these theoretical findings with numerical experiments and extend our investigation to real-world scenarios, where we observe an analogous behavior.
Sharp higher order convergence rates for the Adam optimizer
Apr 28, 2025Gradient descent based optimization methods are the methods of choice to train deep neural networks in machine learning. Beyond the standard gradient descent method, also suitable modified variants of standard gradient descent involving acceleration techniques such as the momentum method and/or adaptivity techniques such as the RMSprop method are frequently considered optimization methods. These days the most popular of such sophisticated optimization schemes is presumably the Adam optimizer that has been proposed in 2014 by Kingma and Ba. A highly relevant topic of research is to investigate the speed of convergence of such optimization methods. In particular, in 1964 Polyak showed that the standard gradient descent method converges in a neighborhood of a strict local minimizer with rate (x - 1)(x + 1)^{-1} while momentum achieves the (optimal) strictly faster convergence rate (\sqrt{x} - 1)(\sqrt{x} + 1)^{-1} where x \in (1,\infty) is the condition number (the ratio of the largest and the smallest eigenvalue) of the Hessian of the objective function at the local minimizer. It is the key contribution of this work to reveal that Adam also converges with the strictly faster convergence rate (\sqrt{x} - 1)(\sqrt{x} + 1)^{-1} while RMSprop only converges with the convergence rate (x - 1)(x + 1)^{-1}.
Non-convergence to the optimal risk for Adam and stochastic gradient descent optimization in the training of deep neural networks
Mar 03, 2025Despite the omnipresent use of stochastic gradient descent (SGD) optimization methods in the training of deep neural networks (DNNs), it remains, in basically all practically relevant scenarios, a fundamental open problem to provide a rigorous theoretical explanation for the success (and the limitations) of SGD optimization methods in deep learning. In particular, it remains an open question to prove or disprove convergence of the true risk of SGD optimization methods to the optimal true risk value in the training of DNNs. In one of the main results of this work we reveal for a general class of activations, loss functions, random initializations, and SGD optimization methods (including, for example, standard SGD, momentum SGD, Nesterov accelerated SGD, Adagrad, RMSprop, Adadelta, Adam, Adamax, Nadam, Nadamax, and AMSGrad) that in the training of any arbitrary fully-connected feedforward DNN it does not hold that the true risk of the considered optimizer converges in probability to the optimal true risk value. Nonetheless, the true risk of the considered SGD optimization method may very well converge to a strictly suboptimal true risk value.
On the logical skills of large language models: evaluations using arbitrarily complex first-order logic problems
Feb 20, 2025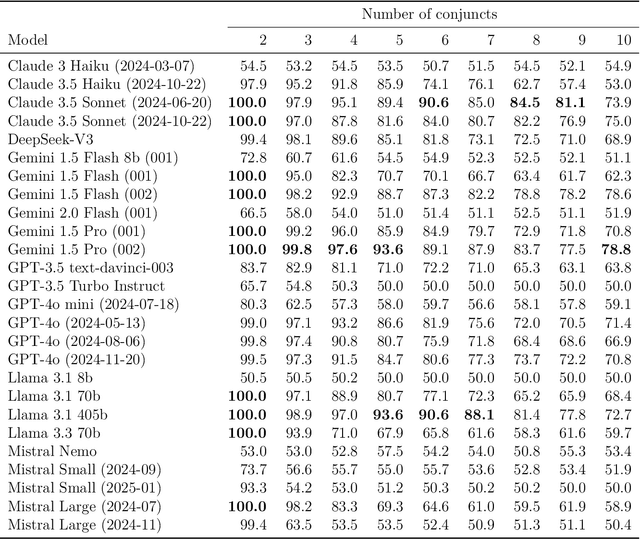
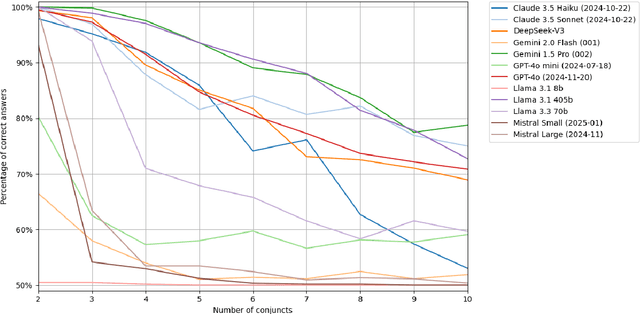
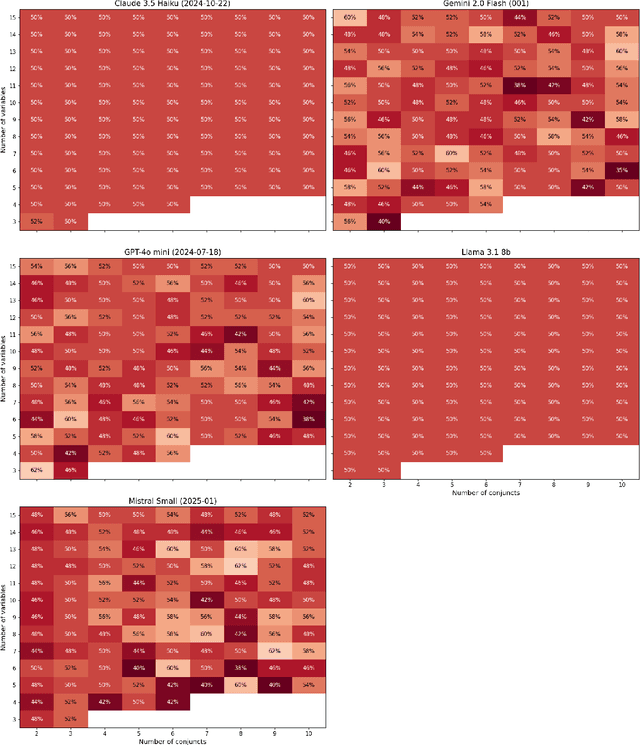
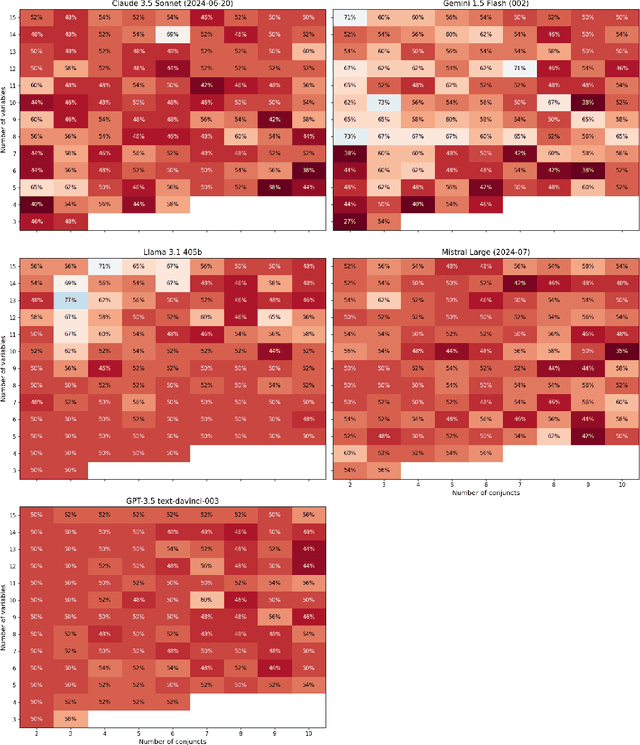
We present a method of generating first-order logic statements whose complexity can be controlled along multiple dimensions. We use this method to automatically create several datasets consisting of questions asking for the truth or falsity of first-order logic statements in Zermelo-Fraenkel set theory. While the resolution of these questions does not require any knowledge beyond basic notation of first-order logic and set theory, it does require a degree of planning and logical reasoning, which can be controlled up to arbitrarily high difficulty by the complexity of the generated statements. Furthermore, we do extensive evaluations of the performance of various large language models, including recent models such as DeepSeek-R1 and OpenAI's o3-mini, on these datasets. All of the datasets along with the code used for generating them, as well as all data from the evaluations is publicly available at https://github.com/bkuckuck/logical-skills-of-llms.