 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform a priori bounds and error analysis for the Adam stochastic gradient descent optimization method
Mar 19, 2026The adaptive moment estimation (Adam) optimizer proposed by Kingma & Ba (2014) is presumably the most popular stochastic gradient descent (SGD) optimization method for the training of deep neural networks (DNNs) in artificial intelligence (AI) systems. Despite its groundbreaking success in the training of AI systems, it still remains an open research problem to provide a complete error analysis of Adam, not only for optimizing DNNs but even when applied to strongly convex stochastic optimization problems (SOPs). Previous error analysis results for strongly convex SOPs in the literature provide conditional convergence analyses that rely on the assumption that Adam does not diverge to infinity but remains uniformly bounded. It is the key contribution of this work to establish uniform a priori bounds for Adam and, thereby, to provide -- for the first time -- an unconditional error analysis for Adam for a large class of strongly convex SOPs.
Adam symmetry theorem: characterization of the convergence of the stochastic Adam optimizer
Nov 10, 2025Beside the standard stochastic gradient descent (SGD) method, the Adam optimizer due to Kingma & Ba (2014) is currently probably the best-known optimization method for the training of deep neural networks in artificial intelligence (AI) systems. Despite the popularity and the success of Adam it remains an \emph{open research problem} to provide a rigorous convergence analysis for Adam even for the class of strongly convex SOPs. In one of the main results of this work we establish convergence rates for Adam in terms of the number of gradient steps (convergence rate \nicefrac{1}{2} w.r.t. the size of the learning rate), the size of the mini-batches (convergence rate 1 w.r.t. the size of the mini-batches), and the size of the second moment parameter of Adam (convergence rate 1 w.r.t. the distance of the second moment parameter to 1) for the class of strongly convex SOPs. In a further main result of this work, which we refer to as \emph{Adam symmetry theorem}, we illustrate the optimality of the established convergence rates by proving for a special class of simple quadratic strongly convex SOPs that Adam converges as the number of gradient steps increases to infinity to the solution of the SOP (the unique minimizer of the strongly convex objective function) if and \emph{only} if the random variables in the SOP (the data in the SOP) are \emph{symmetrically distributed}. In particular, in the standard case where the random variables in the SOP are not symmetrically distributed we \emph{disprove} that Adam converges to the minimizer of the SOP as the number of Adam steps increases to infinity. We also complement the conclusions of our convergence analysis and the Adam symmetry theorem by several numerical simulations that indicate the sharpness of the established convergence rates and that illustrate the practical appearance of the phenomena revealed in the \emph{Adam symmetry theorem}.
ODE approximation for the Adam algorithm: General and overparametrized setting
Nov 06, 2025The Adam optimizer is currently presumably the most popular optimization method in deep learning. In this article we develop an ODE based method to study the Adam optimizer in a fast-slow scaling regime. For fixed momentum parameters and vanishing step-sizes, we show that the Adam algorithm is an asymptotic pseudo-trajectory of the flow of a particular vector field, which is referred to as the Adam vector field. Leveraging properties of asymptotic pseudo-trajectories, we establish convergence results for the Adam algorithm. In particular, in a very general setting we show that if the Adam algorithm converges, then the limit must be a zero of the Adam vector field, rather than a local minimizer or critical point of the objective function. In contrast, in the overparametrized empirical risk minimization setting, the Adam algorithm is able to locally find the set of minima. Specifically, we show that in a neighborhood of the global minima, the objective function serves as a Lyapunov function for the flow induced by the Adam vector field. As a consequence, if the Adam algorithm enters a neighborhood of the global minima infinitely often, it converges to the set of global minima.
SAD Neural Networks: Divergent Gradient Flows and Asymptotic Optimality via o-minimal Structures
May 14, 2025


We study gradient flows for loss landscapes of fully connected feed forward neural networks with commonly used continuously differentiable activation functions such as the logistic, hyperbolic tangent, softplus or GELU function. We prove that the gradient flow either converges to a critical point or diverges to infinity while the loss converges to an asymptotic critical value. Moreover, we prove the existence of a threshold $\varepsilon>0$ such that the loss value of any gradient flow initialized at most $\varepsilon$ above the optimal level converges to it. For polynomial target functions and sufficiently big architecture and data set, we prove that the optimal loss value is zero and can only be realized asymptotically. From this setting, we deduce our main result that any gradient flow with sufficiently good initialization diverges to infinity. Our proof heavily relies on the geometry of o-minimal structures. We confirm these theoretical findings with numerical experiments and extend our investigation to real-world scenarios, where we observe an analogous behavior.
Sharp higher order convergence rates for the Adam optimizer
Apr 28, 2025Gradient descent based optimization methods are the methods of choice to train deep neural networks in machine learning. Beyond the standard gradient descent method, also suitable modified variants of standard gradient descent involving acceleration techniques such as the momentum method and/or adaptivity techniques such as the RMSprop method are frequently considered optimization methods. These days the most popular of such sophisticated optimization schemes is presumably the Adam optimizer that has been proposed in 2014 by Kingma and Ba. A highly relevant topic of research is to investigate the speed of convergence of such optimization methods. In particular, in 1964 Polyak showed that the standard gradient descent method converges in a neighborhood of a strict local minimizer with rate (x - 1)(x + 1)^{-1} while momentum achieves the (optimal) strictly faster convergence rate (\sqrt{x} - 1)(\sqrt{x} + 1)^{-1} where x \in (1,\infty) is the condition number (the ratio of the largest and the smallest eigenvalue) of the Hessian of the objective function at the local minimizer. It is the key contribution of this work to reveal that Adam also converges with the strictly faster convergence rate (\sqrt{x} - 1)(\sqrt{x} + 1)^{-1} while RMSprop only converges with the convergence rate (x - 1)(x + 1)^{-1}.
In almost all shallow analytic neural network optimization landscapes, efficient minimizers have strongly convex neighborhoods
Apr 11, 2025Whether or not a local minimum of a cost function has a strongly convex neighborhood greatly influences the asymptotic convergence rate of optimizers. In this article, we rigorously analyze the prevalence of this property for the mean squared error induced by shallow, 1-hidden layer neural networks with analytic activation functions when applied to regression problems. The parameter space is divided into two domains: the 'efficient domain' (all parameters for which the respective realization function cannot be generated by a network having a smaller number of neurons) and the 'redundant domain' (the remaining parameters). In almost all regression problems on the efficient domain the optimization landscape only features local minima that are strongly convex. Formally, we will show that for certain randomly picked regression problems the optimization landscape is almost surely a Morse function on the efficient domain. The redundant domain has significantly smaller dimension than the efficient domain and on this domain, potential local minima are never isolated.
Mathematical analysis of the gradients in deep learning
Jan 26, 2025Deep learning algorithms -- typically consisting of a class of deep artificial neural networks (ANNs) trained by a stochastic gradient descent (SGD) optimization method -- are nowadays an integral part in many areas of science, industry, and also our day to day life. Roughly speaking, in their most basic form, ANNs can be regarded as functions that consist of a series of compositions of affine-linear functions with multidimensional versions of so-called activation functions. One of the most popular of such activation functions is the rectified linear unit (ReLU) function $\mathbb{R} \ni x \mapsto \max\{ x, 0 \} \in \mathbb{R}$. The ReLU function is, however, not differentiable and, typically, this lack of regularity transfers to the cost function of the supervised learning problem under consideration. Regardless of this lack of differentiability issue, deep learning practioners apply SGD methods based on suitably generalized gradients in standard deep learning libraries like {\sc TensorFlow} or {\sc Pytorch}. In this work we reveal an accurate and concise mathematical description of such generalized gradients in the training of deep fully-connected feedforward ANNs and we also study the resulting generalized gradient function analytically. Specifically, we provide an appropriate approximation procedure that uniquely describes the generalized gradient function, we prove that the generalized gradients are limiting Fr\'echet subgradients of the cost functional, and we conclude that the generalized gradients must coincide with the standard gradient of the cost functional on every open sets on which the cost functional is continuously differentiable.
Averaged Adam accelerates stochastic optimization in the training of deep neural network approximations for partial differential equation and optimal control problems
Jan 10, 2025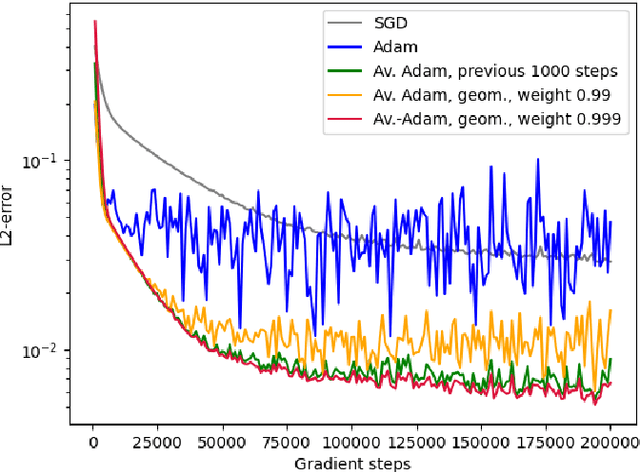
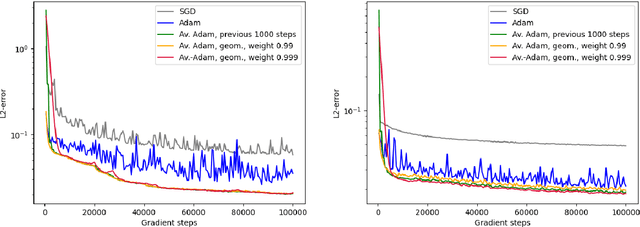
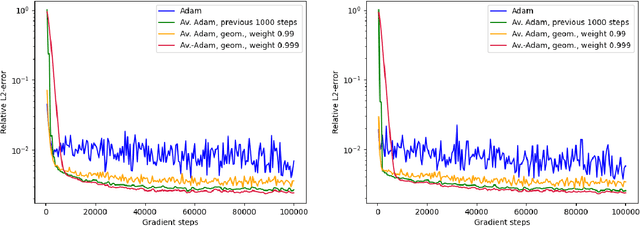
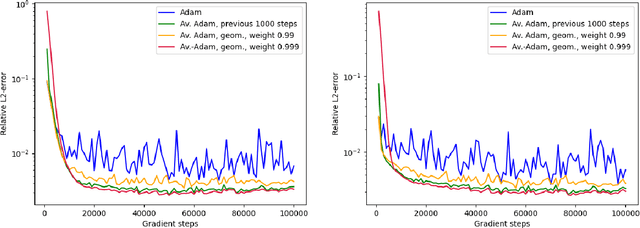
Deep learning methods - usually consisting of a class of deep neural networks (DNNs) trained by a stochastic gradient descent (SGD) optimization method - are nowadays omnipresent in data-driven learning problems as well as in scientific computing tasks such as optimal control (OC) and partial differential equation (PDE) problems. In practically relevant learning tasks, often not the plain-vanilla standard SGD optimization method is employed to train the considered class of DNNs but instead more sophisticated adaptive and accelerated variants of the standard SGD method such as the popular Adam optimizer are used. Inspired by the classical Polyak-Ruppert averaging approach, in this work we apply averaged variants of the Adam optimizer to train DNNs to approximately solve exemplary scientific computing problems in the form of PDEs and OC problems. We test the averaged variants of Adam in a series of learning problems including physics-informed neural network (PINN), deep backward stochastic differential equation (deep BSDE), and deep Kolmogorov approximations for PDEs (such as heat, Black-Scholes, Burgers, and Allen-Cahn PDEs), including DNN approximations for OC problems, and including DNN approximations for image classification problems (ResNet for CIFAR-10). In each of the numerical examples the employed averaged variants of Adam outperform the standard Adam and the standard SGD optimizers, particularly, in the situation of the scientific machine learning problems. The Python source codes for the numerical experiments associated to this work can be found on GitHub at https://github.com/deeplearningmethods/averaged-adam.
Convergence rates for the Adam optimizer
Jul 29, 2024Stochastic gradient descent (SGD) optimization methods are nowadays the method of choice for the training of deep neural networks (DNNs) in artificial intelligence systems. In practically relevant training problems, usually not the plain vanilla standard SGD method is the employed optimization scheme but instead suitably accelerated and adaptive SGD optimization methods are applied. As of today, maybe the most popular variant of such accelerated and adaptive SGD optimization methods is the famous Adam optimizer proposed by Kingma & Ba in 2014. Despite the popularity of the Adam optimizer in implementations, it remained an open problem of research to provide a convergence analysis for the Adam optimizer even in the situation of simple quadratic stochastic optimization problems where the objective function (the function one intends to minimize) is strongly convex. In this work we solve this problem by establishing optimal convergence rates for the Adam optimizer for a large class of stochastic optimization problems, in particular, covering simple quadratic stochastic optimization problems. The key ingredient of our convergence analysis is a new vector field function which we propose to refer to as the Adam vector field. This Adam vector field accurately describes the macroscopic behaviour of the Adam optimization process but differs from the negative gradient of the objective function (the function we intend to minimize) of the considered stochastic optimization problem. In particular, our convergence analysis reveals that the Adam optimizer does typically not converge to critical points of the objective function (zeros of the gradient of the objective function) of the considered optimization problem but converges with rates to zeros of this Adam vector field.
Non-convergence of Adam and other adaptive stochastic gradient descent optimization methods for non-vanishing learning rates
Jul 11, 2024Deep learning algorithms - typically consisting of a class of deep neural networks trained by a stochastic gradient descent (SGD) optimization method - are nowadays the key ingredients in many artificial intelligence (AI) systems and have revolutionized our ways of working and living in modern societies. For example, SGD methods are used to train powerful large language models (LLMs) such as versions of ChatGPT and Gemini, SGD methods are employed to create successful generative AI based text-to-image creation models such as Midjourney, DALL-E, and Stable Diffusion, but SGD methods are also used to train DNNs to approximately solve scientific models such as partial differential equation (PDE) models from physics and biology and optimal control and stopping problems from engineering. It is known that the plain vanilla standard SGD method fails to converge even in the situation of several convex optimization problems if the learning rates are bounded away from zero. However, in many practical relevant training scenarios, often not the plain vanilla standard SGD method but instead adaptive SGD methods such as the RMSprop and the Adam optimizers, in which the learning rates are modified adaptively during the training process, are employed. This naturally rises the question whether such adaptive optimizers, in which the learning rates are modified adaptively during the training process, do converge in the situation of non-vanishing learning rates. In this work we answer this question negatively by proving that adaptive SGD methods such as the popular Adam optimizer fail to converge to any possible random limit point if the learning rates are asymptotically bounded away from zero. In our proof of this non-convergence result we establish suitable pathwise a priori bounds for a class of accelerated and adaptive SGD methods, which are also of independent interest.