 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-convergence of Adam and other adaptive stochastic gradient descent optimization methods for non-vanishing learning rates
Jul 11, 2024Deep learning algorithms - typically consisting of a class of deep neural networks trained by a stochastic gradient descent (SGD) optimization method - are nowadays the key ingredients in many artificial intelligence (AI) systems and have revolutionized our ways of working and living in modern societies. For example, SGD methods are used to train powerful large language models (LLMs) such as versions of ChatGPT and Gemini, SGD methods are employed to create successful generative AI based text-to-image creation models such as Midjourney, DALL-E, and Stable Diffusion, but SGD methods are also used to train DNNs to approximately solve scientific models such as partial differential equation (PDE) models from physics and biology and optimal control and stopping problems from engineering. It is known that the plain vanilla standard SGD method fails to converge even in the situation of several convex optimization problems if the learning rates are bounded away from zero. However, in many practical relevant training scenarios, often not the plain vanilla standard SGD method but instead adaptive SGD methods such as the RMSprop and the Adam optimizers, in which the learning rates are modified adaptively during the training process, are employed. This naturally rises the question whether such adaptive optimizers, in which the learning rates are modified adaptively during the training process, do converge in the situation of non-vanishing learning rates. In this work we answer this question negatively by proving that adaptive SGD methods such as the popular Adam optimizer fail to converge to any possible random limit point if the learning rates are asymptotically bounded away from zero. In our proof of this non-convergence result we establish suitable pathwise a priori bounds for a class of accelerated and adaptive SGD methods, which are also of independent interest.
The necessity of depth for artificial neural networks to approximate certain classes of smooth and bounded functions without the curse of dimensionality
Jan 19, 2023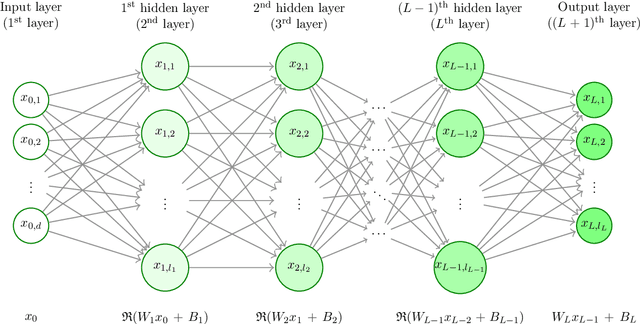
In this article we study high-dimensional approximation capacities of shallow and deep artificial neural networks (ANNs) with the rectified linear unit (ReLU) activation. In particular, it is a key contribution of this work to reveal that for all $a,b\in\mathbb{R}$ with $b-a\geq 7$ we have that the functions $[a,b]^d\ni x=(x_1,\dots,x_d)\mapsto\prod_{i=1}^d x_i\in\mathbb{R}$ for $d\in\mathbb{N}$ as well as the functions $[a,b]^d\ni x =(x_1,\dots, x_d)\mapsto\sin(\prod_{i=1}^d x_i) \in \mathbb{R} $ for $ d \in \mathbb{N} $ can neither be approximated without the curse of dimensionality by means of shallow ANNs nor insufficiently deep ANNs with ReLU activation but can be approximated without the curse of dimensionality by sufficiently deep ANNs with ReLU activation. We show that the product functions and the sine of the product functions are polynomially tractable approximation problems among the approximating class of deep ReLU ANNs with the number of hidden layers being allowed to grow in the dimension $ d \in \mathbb{N} $. We establish the above outlined statements not only for the product functions and the sine of the product functions but also for other classes of target functions, in particular, for classes of uniformly globally bounded $ C^{ \infty } $-functions with compact support on any $[a,b]^d$ with $a\in\mathbb{R}$, $b\in(a,\infty)$. Roughly speaking, in this work we lay open that simple approximation problems such as approximating the sine or cosine of products cannot be solved in standard implementation frameworks by shallow or insufficiently deep ANNs with ReLU activation in polynomial time, but can be approximated by sufficiently deep ReLU ANNs with the number of parameters growing at most polynomially.