 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Target Update Frequencies in Q-Learning
Feb 03, 2026The target network update frequency (TUF) is a central stabilization mechanism in (deep) Q-learning. However, their selection remains poorly understood and is often treated merely as another tunable hyperparameter rather than as a principled design decision. This work provides a theoretical analysis of target fixing in tabular Q-learning through the lens of approximate dynamic programming. We formulate periodic target updates as a nested optimization scheme in which each outer iteration applies an inexact Bellman optimality operator, approximated by a generic inner loop optimizer. Rigorous theory yields a finite-time convergence analysis for the asynchronous sampling setting, specializing to stochastic gradient descent in the inner loop. Our results deliver an explicit characterization of the bias-variance trade-off induced by the target update period, showing how to optimally set this critical hyperparameter. We prove that constant target update schedules are suboptimal, incurring a logarithmic overhead in sample complexity that is entirely avoidable with adaptive schedules. Our analysis shows that the optimal target update frequency increases geometrically over the course of the learning process.
An Approximate Ascent Approach To Prove Convergence of PPO
Feb 03, 2026Proximal Policy Optimization (PPO) is among the most widely used deep reinforcement learning algorithms, yet its theoretical foundations remain incomplete. Most importantly, convergence and understanding of fundamental PPO advantages remain widely open. Under standard theory assumptions we show how PPO's policy update scheme (performing multiple epochs of minibatch updates on multi-use rollouts with a surrogate gradient) can be interpreted as approximated policy gradient ascent. We show how to control the bias accumulated by the surrogate gradients and use techniques from random reshuffling to prove a convergence theorem for PPO that sheds light on PPO's success. Additionally, we identify a previously overlooked issue in truncated Generalized Advantage Estimation commonly used in PPO. The geometric weighting scheme induces infinite mass collapse onto the longest $k$-step advantage estimator at episode boundaries. Empirical evaluations show that a simple weight correction can yield substantial improvements in environments with strong terminal signal, such as Lunar Lander.
ODE approximation for the Adam algorithm: General and overparametrized setting
Nov 06, 2025The Adam optimizer is currently presumably the most popular optimization method in deep learning. In this article we develop an ODE based method to study the Adam optimizer in a fast-slow scaling regime. For fixed momentum parameters and vanishing step-sizes, we show that the Adam algorithm is an asymptotic pseudo-trajectory of the flow of a particular vector field, which is referred to as the Adam vector field. Leveraging properties of asymptotic pseudo-trajectories, we establish convergence results for the Adam algorithm. In particular, in a very general setting we show that if the Adam algorithm converges, then the limit must be a zero of the Adam vector field, rather than a local minimizer or critical point of the objective function. In contrast, in the overparametrized empirical risk minimization setting, the Adam algorithm is able to locally find the set of minima. Specifically, we show that in a neighborhood of the global minima, the objective function serves as a Lyapunov function for the flow induced by the Adam vector field. As a consequence, if the Adam algorithm enters a neighborhood of the global minima infinitely often, it converges to the set of global minima.
Controlling the Flow: Stability and Convergence for Stochastic Gradient Descent with Decaying Regularization
May 16, 2025The present article studies the minimization of convex, L-smooth functions defined on a separable real Hilbert space. We analyze regularized stochastic gradient descent (reg-SGD), a variant of stochastic gradient descent that uses a Tikhonov regularization with time-dependent, vanishing regularization parameter. We prove strong convergence of reg-SGD to the minimum-norm solution of the original problem without additional boundedness assumptions. Moreover, we quantify the rate of convergence and optimize the interplay between step-sizes and regularization decay. Our analysis reveals how vanishing Tikhonov regularization controls the flow of SGD and yields stable learning dynamics, offering new insights into the design of iterative algorithms for convex problems, including those that arise in ill-posed inverse problems. We validate our theoretical findings through numerical experiments on image reconstruction and ODE-based inverse problems.
Polyak's Heavy Ball Method Achieves Accelerated Local Rate of Convergence under Polyak-Lojasiewicz Inequality
Oct 22, 2024In this work, we consider the convergence of Polyak's heavy ball method, both in continuous and discrete time, on a non-convex objective function. We recover the convergence rates derived in [Polyak, U.S.S.R. Comput. Math. and Math. Phys., 1964] for strongly convex objective functions, assuming only validity of the Polyak-Lojasiewicz inequality. In continuous time our result holds for all initializations, whereas in the discrete time setting we conduct a local analysis around the global minima. Our results demonstrate that the heavy ball method does, in fact, accelerate on the class of objective functions satisfying the Polyak-Lojasiewicz inequality. This holds even in the discrete time setting, provided the method reaches a neighborhood of the global minima. Instead of the usually employed Lyapunov-type arguments, our approach leverages a new differential geometric perspective of the Polyak-Lojasiewicz inequality proposed in [Rebjock and Boumal, Math. Program., 2024].
Stochastic Modified Flows for Riemannian Stochastic Gradient Descent
Feb 02, 2024We give quantitative estimates for the rate of convergence of Riemannian stochastic gradient descent (RSGD) to Riemannian gradient flow and to a diffusion process, the so-called Riemannian stochastic modified flow (RSMF). Using tools from stochastic differential geometry we show that, in the small learning rate regime, RSGD can be approximated by the solution to the RSMF driven by an infinite-dimensional Wiener process. The RSMF accounts for the random fluctuations of RSGD and, thereby, increases the order of approximation compared to the deterministic Riemannian gradient flow. The RSGD is build using the concept of a retraction map, that is, a cost efficient approximation of the exponential map, and we prove quantitative bounds for the weak error of the diffusion approximation under assumptions on the retraction map, the geometry of the manifold, and the random estimators of the gradient.
On the existence of optimal shallow feedforward networks with ReLU activation
Mar 06, 2023We prove existence of global minima in the loss landscape for the approximation of continuous target functions using shallow feedforward artificial neural networks with ReLU activation. This property is one of the fundamental artifacts separating ReLU from other commonly used activation functions. We propose a kind of closure of the search space so that in the extended space minimizers exist. In a second step, we show under mild assumptions that the newly added functions in the extension perform worse than appropriate representable ReLU networks. This then implies that the optimal response in the extended target space is indeed the response of a ReLU network.
On the existence of minimizers in shallow residual ReLU neural network optimization landscapes
Feb 28, 2023Many mathematical convergence results for gradient descent (GD) based algorithms employ the assumption that the GD process is (almost surely) bounded and, also in concrete numerical simulations, divergence of the GD process may slow down, or even completely rule out, convergence of the error function. In practical relevant learning problems, it thus seems to be advisable to design the ANN architectures in a way so that GD optimization processes remain bounded. The property of the boundedness of GD processes for a given learning problem seems, however, to be closely related to the existence of minimizers in the optimization landscape and, in particular, GD trajectories may escape to infinity if the infimum of the error function (objective function) is not attained in the optimization landscape. This naturally raises the question of the existence of minimizers in the optimization landscape and, in the situation of shallow residual ANNs with multi-dimensional input layers and multi-dimensional hidden layers with the ReLU activation, the main result of this work answers this question affirmatively for a general class of loss functions and all continuous target functions. In our proof of this statement, we propose a kind of closure of the search space, where the limits are called generalized responses, and, thereafter, we provide sufficient criteria for the loss function and the underlying probability distribution which ensure that all additional artificial generalized responses are suboptimal which finally allows us to conclude the existence of minimizers in the optimization landscape.
Stochastic Modified Flows, Mean-Field Limits and Dynamics of Stochastic Gradient Descent
Feb 14, 2023We propose new limiting dynamics for stochastic gradient descent in the small learning rate regime called stochastic modified flows. These SDEs are driven by a cylindrical Brownian motion and improve the so-called stochastic modified equations by having regular diffusion coefficients and by matching the multi-point statistics. As a second contribution, we introduce distribution dependent stochastic modified flows which we prove to describe the fluctuating limiting dynamics of stochastic gradient descent in the small learning rate - infinite width scaling regime.
Convergence rates for momentum stochastic gradient descent with noise of machine learning type
Feb 07, 2023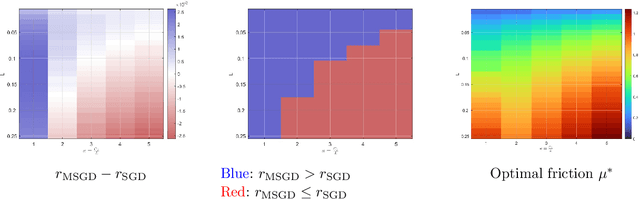
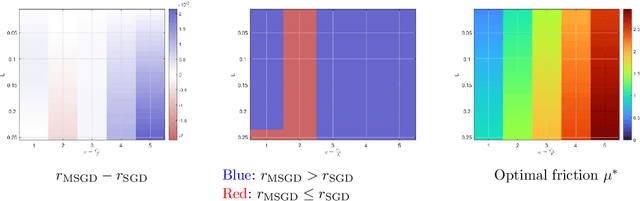
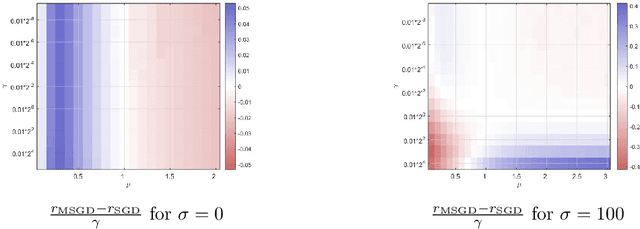
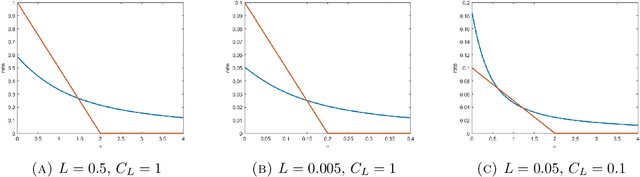
We consider the momentum stochastic gradient descent scheme (MSGD) and its continuous-in-time counterpart in the context of non-convex optimization. We show almost sure exponential convergence of the objective function value for target functions that are Lipschitz continuous and satisfy the Polyak-Lojasiewicz inequality on the relevant domain, and under assumptions on the stochastic noise that are motivated by overparameterized supervised learning applications. Moreover, we optimize the convergence rate over the set of friction parameters and show that the MSGD process almost surely converges.