 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Spikes in Stochastic Gradient Descent: A Large-Deviations View
Mar 10, 2026We analyse SGD training of a shallow, fully connected network in the NTK scaling and provide a quantitative theory of the catapult phase. We identify an explicit criterion separating two behaviours: When an explicit function $G$, depending only on the kernel, learning rate $η$ and data, is positive, SGD produces large NTK-flattening spikes with high probability; when $G<0$, their probability decays like $(n/η)^{-\vartheta/2}$, for an explicitly characterised $\vartheta\in (0,\infty)$. This yields a concrete parameter-dependent explanation for why such spikes may still be observed at practical widths.
Stochastic Modified Flows for Riemannian Stochastic Gradient Descent
Feb 02, 2024We give quantitative estimates for the rate of convergence of Riemannian stochastic gradient descent (RSGD) to Riemannian gradient flow and to a diffusion process, the so-called Riemannian stochastic modified flow (RSMF). Using tools from stochastic differential geometry we show that, in the small learning rate regime, RSGD can be approximated by the solution to the RSMF driven by an infinite-dimensional Wiener process. The RSMF accounts for the random fluctuations of RSGD and, thereby, increases the order of approximation compared to the deterministic Riemannian gradient flow. The RSGD is build using the concept of a retraction map, that is, a cost efficient approximation of the exponential map, and we prove quantitative bounds for the weak error of the diffusion approximation under assumptions on the retraction map, the geometry of the manifold, and the random estimators of the gradient.
Stochastic Modified Flows, Mean-Field Limits and Dynamics of Stochastic Gradient Descent
Feb 14, 2023We propose new limiting dynamics for stochastic gradient descent in the small learning rate regime called stochastic modified flows. These SDEs are driven by a cylindrical Brownian motion and improve the so-called stochastic modified equations by having regular diffusion coefficients and by matching the multi-point statistics. As a second contribution, we introduce distribution dependent stochastic modified flows which we prove to describe the fluctuating limiting dynamics of stochastic gradient descent in the small learning rate - infinite width scaling regime.
Convergence rates for momentum stochastic gradient descent with noise of machine learning type
Feb 07, 2023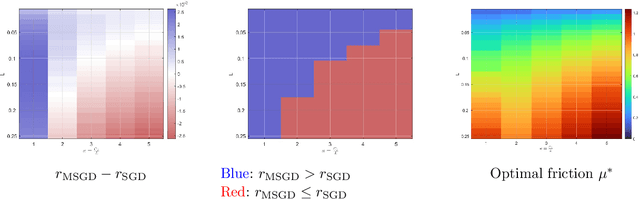
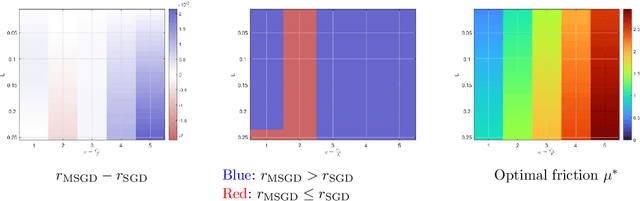
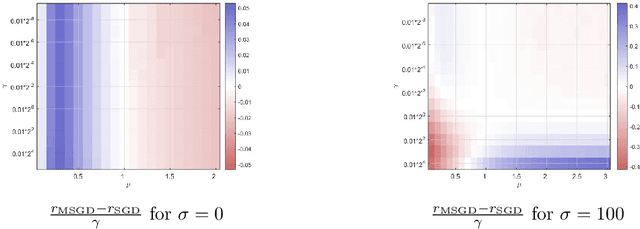
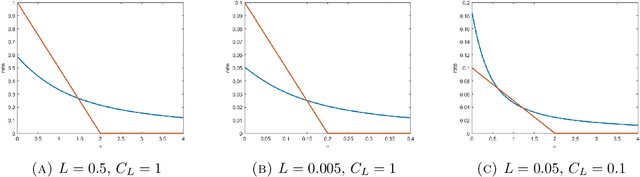
We consider the momentum stochastic gradient descent scheme (MSGD) and its continuous-in-time counterpart in the context of non-convex optimization. We show almost sure exponential convergence of the objective function value for target functions that are Lipschitz continuous and satisfy the Polyak-Lojasiewicz inequality on the relevant domain, and under assumptions on the stochastic noise that are motivated by overparameterized supervised learning applications. Moreover, we optimize the convergence rate over the set of friction parameters and show that the MSGD process almost surely converges.
Conservative SPDEs as fluctuating mean field limits of stochastic gradient descent
Jul 12, 2022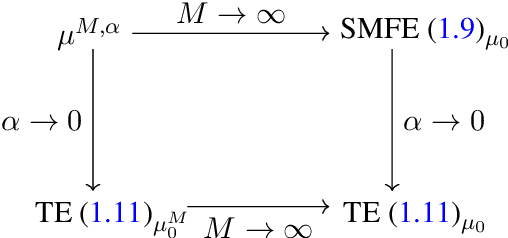
The convergence of stochastic interacting particle systems in the mean-field limit to solutions to conservative stochastic partial differential equations is shown, with optimal rate of convergence. As a second main result, a quantitative central limit theorem for such SPDEs is derived, again with optimal rate of convergence. The results apply in particular to the convergence in the mean-field scaling of stochastic gradient descent dynamics in overparametrized, shallow neural networks to solutions to SPDEs. It is shown that the inclusion of fluctuations in the limiting SPDE improves the rate of convergence, and retains information about the fluctuations of stochastic gradient descent in the continuum limit.
Convergence rates for the stochastic gradient descent method for non-convex objective functions
Apr 02, 2019We prove the local convergence to minima and estimates on the rate of convergence for the stochastic gradient descent method in the case of not necessarily globally convex nor contracting objective functions. In particular, the results are applicable to simple objective functions arising in machine learning.