 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGWQ: Gradient-Aware Weight Quantization for Large Language Models
Oct 30, 2024
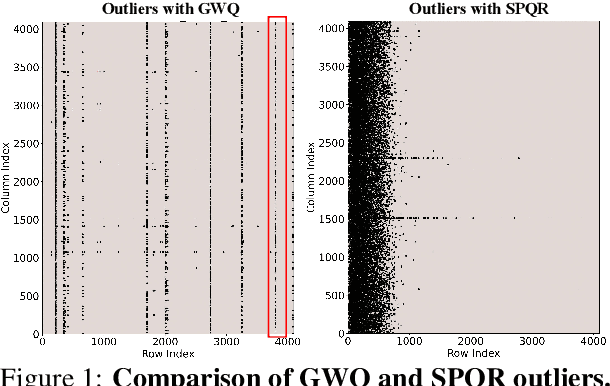
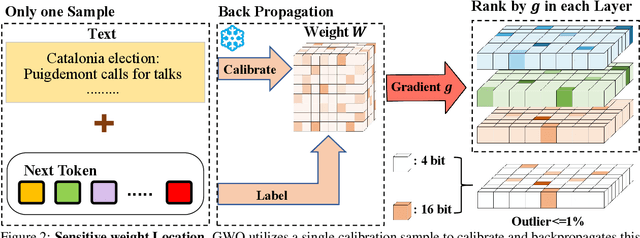
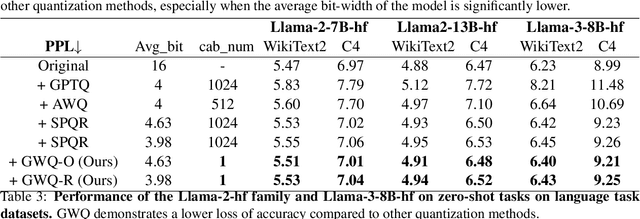
Large language models (LLMs) show impressive performance in solving complex languagetasks. However, its large number of parameterspresent significant challenges for the deployment and application of the model on edge devices. Compressing large language models to low bits can enable them to run on resource-constrained devices, often leading to performance degradation. To address this problem, we propose gradient-aware weight quantization (GWQ), the first quantization approach for low-bit weight quantization that leverages gradients to localize outliers, requiring only a minimal amount of calibration data for outlier detection. GWQ retains the weights corresponding to the top 1% outliers preferentially at FP16 precision, while the remaining non-outlier weights are stored in a low-bit format. GWQ found experimentally that utilizing the sensitive weights in the gradient localization model is more scientific compared to utilizing the sensitive weights in the Hessian matrix localization model. Compared to current quantization methods, GWQ can be applied to multiple language models and achieves lower PPL on the WikiText2 and C4 dataset. In the zero-shot task, GWQ quantized models have higher accuracy compared to other quantization methods.GWQ is also suitable for multimodal model quantization, and the quantized Qwen-VL family model is more accurate than other methods. zero-shot target detection task dataset RefCOCO outperforms the current stat-of-the-arts method SPQR. GWQ achieves 1.2x inference speedup in comparison to the original model, and effectively reduces the inference memory.