 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-SceGen: A Multi-level Scenario Generation Framework
Jan 18, 2025



Current scientific research witnesses various attempts at applying Large Language Models for scenario generation but is inclined only to comprehensive or dangerous scenarios. In this paper, we seek to build a three-stage framework that not only lets users regain controllability over the generated scenarios but also generates comprehensive scenarios containing danger factors in uncontrolled intersection settings. In the first stage, LLM agents will contribute to translating the key components of the description of the expected scenarios into Functional Scenarios. For the second stage, we use Answer Set Programming (ASP) solver Clingo to help us generate comprehensive logical traffic within intersections. During the last stage, we use LLM to update relevant parameters to increase the critical level of the concrete scenario.
MSHT: Multi-stage Hybrid Transformer for the ROSE Image Analysis of Pancreatic Cancer
Dec 27, 2021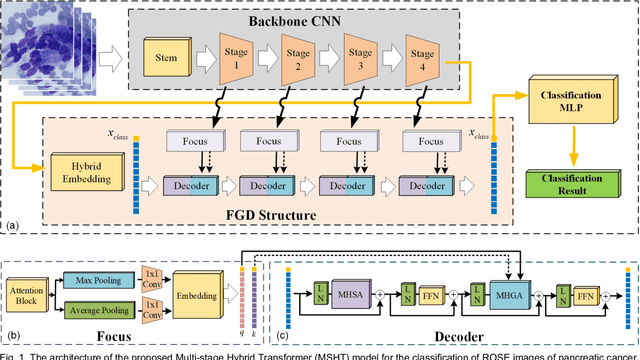
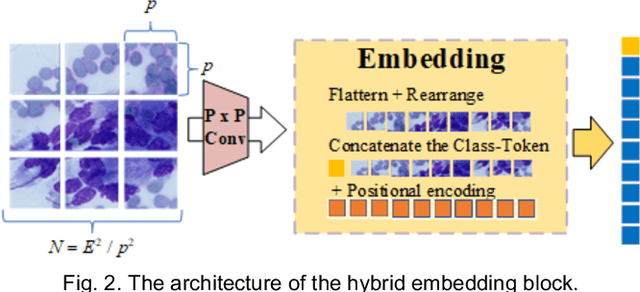


Pancreatic cancer is one of the most malignant cancers in the world, which deteriorates rapidly with very high mortality. The rapid on-site evaluation (ROSE) technique innovates the workflow by immediately analyzing the fast stained cytopathological images with on-site pathologists, which enables faster diagnosis in this time-pressured process. However, the wider expansion of ROSE diagnosis has been hindered by the lack of experienced pathologists. To overcome this problem, we propose a hybrid high-performance deep learning model to enable the automated workflow, thus freeing the occupation of the valuable time of pathologists. By firstly introducing the Transformer block into this field with our particular multi-stage hybrid design, the spatial features generated by the convolutional neural network (CNN) significantly enhance the Transformer global modeling. Turning multi-stage spatial features as global attention guidance, this design combines the robustness from the inductive bias of CNN with the sophisticated global modeling power of Transformer. A dataset of 4240 ROSE images is collected to evaluate the method in this unexplored field. The proposed multi-stage hybrid Transformer (MSHT) achieves 95.68% in classification accuracy, which is distinctively higher than the state-of-the-art models. Facing the need for interpretability, MSHT outperforms its counterparts with more accurate attention regions. The results demonstrate that the MSHT can distinguish cancer samples accurately at an unprecedented image scale, laying the foundation for deploying automatic decision systems and enabling the expansion of ROSE in clinical practice. The code and records are available at: https://github.com/sagizty/Multi-Stage-Hybrid-Transformer.
Prior Attention Network for Multi-Lesion Segmentation in Medical Images
Oct 10, 2021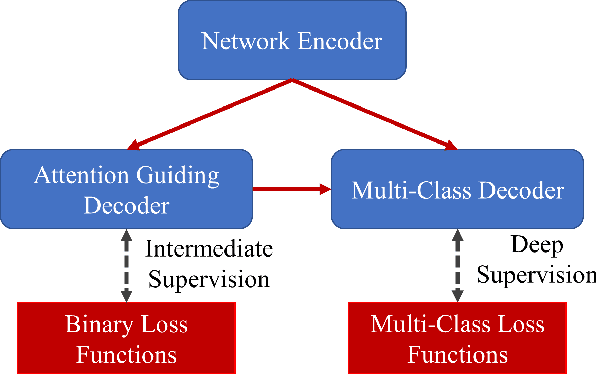
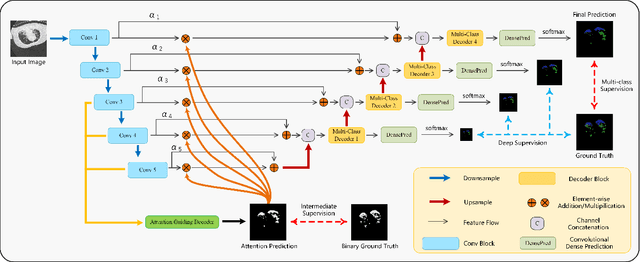
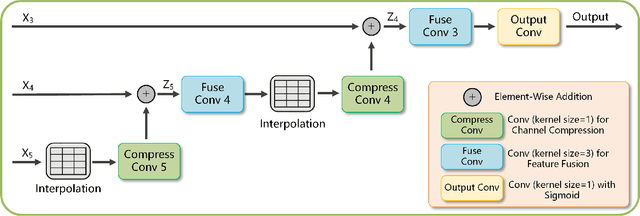
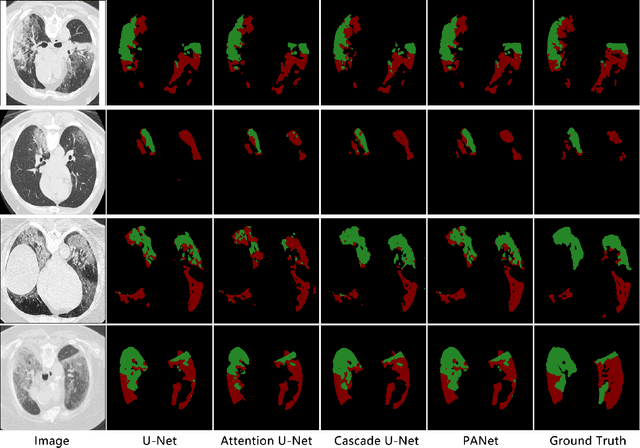
The accurate segmentation of multiple types of lesions from adjacent tissues in medical images is significant in clinical practice. Convolutional neural networks (CNNs) based on the coarse-to-fine strategy have been widely used in this field. However, multi-lesion segmentation remains to be challenging due to the uncertainty in size, contrast, and high interclass similarity of tissues. In addition, the commonly adopted cascaded strategy is rather demanding in terms of hardware, which limits the potential of clinical deployment. To address the problems above,we propose a novel Prior Attention Network (PANet) that follows the coarse-to-fine strategy to perform multi-lesion segmentation in medical images. The proposed network achieves the two steps of segmentation in a single network by inserting lesion-related spatial attention mechanism in the network. Further, we also propose the intermediate supervision strategy for generating lesion-related attention to acquire the regions of interest (ROIs), which accelerates the convergence and obviously improves the segmentation performance. We have investigated the proposed segmentation framework in two applications: 2D segmentation of multiple lung infections in lung CT slices and 3D segmentation of multiple lesions in brain MRIs. Experimental results show that in both 2D and 3D segmentation tasks our proposed network achieves better performance with less computational cost compared with cascaded networks. The proposed network can be regarded as a universal solution to multi-lesion segmentation in both 2D and 3D tasks. The source code is available at: https://github.com/hsiangyuzhao/PANet.
D2A U-Net: Automatic Segmentation of COVID-19 Lesions from CT Slices with Dilated Convolution and Dual Attention Mechanism
Feb 10, 2021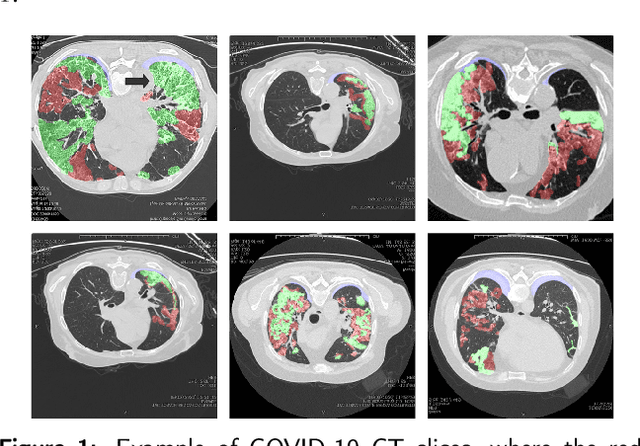
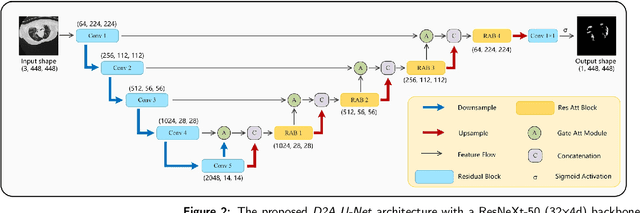

Coronavirus Disease 2019 (COVID-19) has caused great casualties and becomes almost the most urgent public health events worldwide. Computed tomography (CT) is a significant screening tool for COVID-19 infection, and automated segmentation of lung infection in COVID-19 CT images will greatly assist diagnosis and health care of patients. However, accurate and automatic segmentation of COVID-19 lung infections remains to be challenging. In this paper we propose a dilated dual attention U-Net (D2A U-Net) for COVID-19 lesion segmentation in CT slices based on dilated convolution and a novel dual attention mechanism to address the issues above. We introduce a dilated convolution module in model decoder to achieve large receptive field, which refines decoding process and contributes to segmentation accuracy. Also, we present a dual attention mechanism composed of two attention modules which are inserted to skip connection and model decoder respectively. The dual attention mechanism is utilized to refine feature maps and reduce semantic gap between different levels of the model. The proposed method has been evaluated on open-source dataset and outperforms cutting edges methods in semantic segmentation. Our proposed D2A U-Net with pretrained encoder achieves a Dice score of 0.7298 and recall score of 0.7071. Besides, we also build a simplified D2A U-Net without pretrained encoder to provide a fair comparison with other models trained from scratch, which still outperforms popular U-Net family models with a Dice score of 0.7047 and recall score of 0.6626. Our experiment results have shown that by introducing dilated convolution and dual attention mechanism, the number of false positives is significantly reduced, which improves sensitivity to COVID-19 lesions and subsequently brings significant increase to Dice score.
Signal retrieval with measurement system knowledge using variational generative model
Sep 09, 2019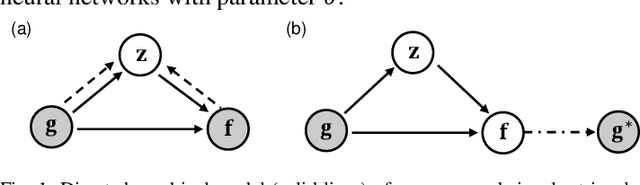
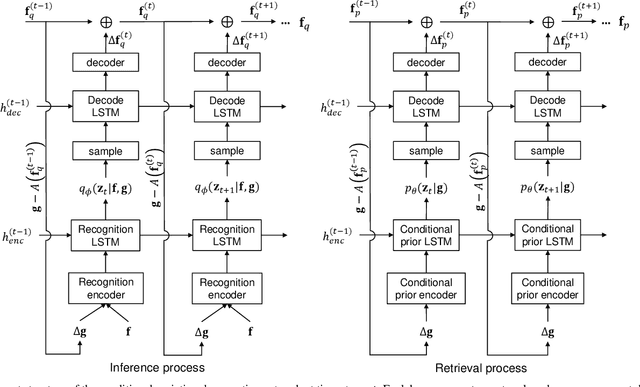
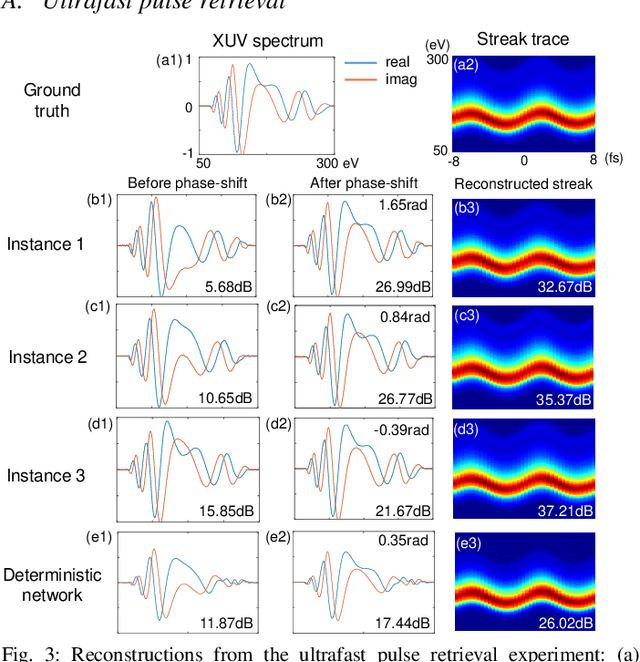

Signal retrieval from a series of indirect measurements is a common task in many imaging, metrology and characterization platforms in science and engineering. Because most of the indirect measurement processes are well-described by physical models, signal retrieval can be solved with an iterative optimization that enforces measurement consistency and prior knowledge on the signal. These iterative processes are time-consuming and only accommodate a linear measurement process and convex signal constraints. Recently, neural networks have been widely adopted to supersede iterative signal retrieval methods by approximating the inverse mapping of the measurement model. However, networks with deterministic processes have failed to distinguish signal ambiguities in an ill-posed measurement system, and retrieved signals often lack consistency with the measurement. In this work we introduce a variational generative model to capture the distribution of all possible signals, given a particular measurement. By exploiting the known measurement model in the variational generative framework, our signal retrieval process resolves the ambiguity in the forward process, and learns to retrieve signals that satisfy the measurement with high fidelity in a variety of linear and nonlinear ill-posed systems, including ultrafast pulse retrieval, coded aperture compressive video sensing and image retrieval from Fresnel hologram.