 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
PPD: A New Valet Parking Pedestrian Fisheye Dataset for Autonomous Driving
Sep 25, 2023



Pedestrian detection under valet parking scenarios is fundamental for autonomous driving. However, the presence of pedestrians can be manifested in a variety of ways and postures under imperfect ambient conditions, which can adversely affect detection performance. Furthermore, models trained on publicdatasets that include pedestrians generally provide suboptimal outcomes for these valet parking scenarios. In this paper, wepresent the Parking Pedestrian Dataset (PPD), a large-scale fisheye dataset to support research dealing with real-world pedestrians, especially with occlusions and diverse postures. PPD consists of several distinctive types of pedestrians captured with fisheye cameras. Additionally, we present a pedestrian detection baseline on PPD dataset, and introduce two data augmentation techniques to improve the baseline by enhancing the diversity ofthe original dataset. Extensive experiments validate the effectiveness of our novel data augmentation approaches over baselinesand the dataset's exceptional generalizability.
ADD: An Automatic Desensitization Fisheye Dataset for Autonomous Driving
Aug 15, 2023Autonomous driving systems require many images for analyzing the surrounding environment. However, there is fewer data protection for private information among these captured images, such as pedestrian faces or vehicle license plates, which has become a significant issue. In this paper, in response to the call for data security laws and regulations and based on the advantages of large Field of View(FoV) of the fisheye camera, we build the first Autopilot Desensitization Dataset, called ADD, and formulate the first deep-learning-based image desensitization framework, to promote the study of image desensitization in autonomous driving scenarios. The compiled dataset consists of 650K images, including different face and vehicle license plate information captured by the surround-view fisheye camera. It covers various autonomous driving scenarios, including diverse facial characteristics and license plate colors. Then, we propose an efficient multitask desensitization network called DesCenterNet as a benchmark on the ADD dataset, which can perform face and vehicle license plate detection and desensitization tasks. Based on ADD, we further provide an evaluation criterion for desensitization performance, and extensive comparison experiments have verified the effectiveness and superiority of our method on image desensitization.
Traffic Context Aware Data Augmentation for Rare Object Detection in Autonomous Driving
May 01, 2022
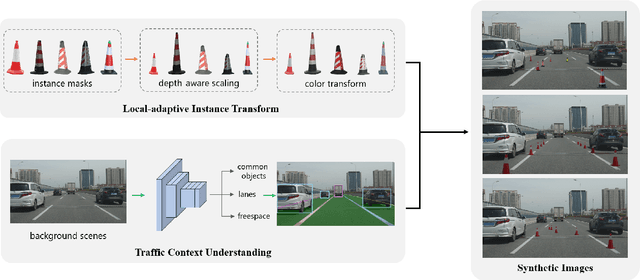


Detection of rare objects (e.g., traffic cones, traffic barrels and traffic warning triangles) is an important perception task to improve the safety of autonomous driving. Training of such models typically requires a large number of annotated data which is expensive and time consuming to obtain. To address the above problem, an emerging approach is to apply data augmentation to automatically generate cost-free training samples. In this work, we propose a systematic study on simple Copy-Paste data augmentation for rare object detection in autonomous driving. Specifically, local adaptive instance-level image transformation is introduced to generate realistic rare object masks from source domain to the target domain. Moreover, traffic scene context is utilized to guide the placement of masks of rare objects. To this end, our data augmentation generates training data with high quality and realistic characteristics by leveraging both local and global consistency. In addition, we build a new dataset named NM10k consisting 10k training images, 4k validation images and the corresponding labels with a diverse range of scenarios in autonomous driving. Experiments on NM10k show that our method achieves promising results on rare object detection. We also present a thorough study to illustrate the effectiveness of our local-adaptive and global constraints based Copy-Paste data augmentation for rare object detection. The data, development kit and more information of NM10k dataset are available online at: \url{https://nullmax-vision.github.io}.
MSHT: Multi-stage Hybrid Transformer for the ROSE Image Analysis of Pancreatic Cancer
Dec 27, 2021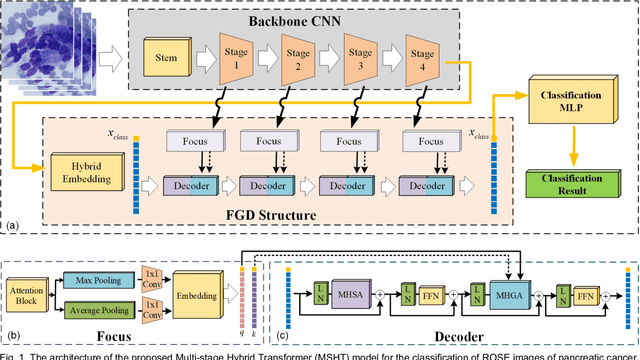
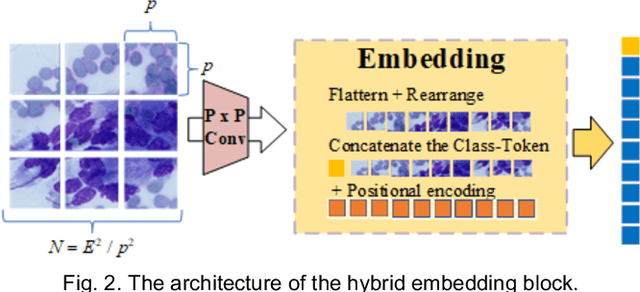


Pancreatic cancer is one of the most malignant cancers in the world, which deteriorates rapidly with very high mortality. The rapid on-site evaluation (ROSE) technique innovates the workflow by immediately analyzing the fast stained cytopathological images with on-site pathologists, which enables faster diagnosis in this time-pressured process. However, the wider expansion of ROSE diagnosis has been hindered by the lack of experienced pathologists. To overcome this problem, we propose a hybrid high-performance deep learning model to enable the automated workflow, thus freeing the occupation of the valuable time of pathologists. By firstly introducing the Transformer block into this field with our particular multi-stage hybrid design, the spatial features generated by the convolutional neural network (CNN) significantly enhance the Transformer global modeling. Turning multi-stage spatial features as global attention guidance, this design combines the robustness from the inductive bias of CNN with the sophisticated global modeling power of Transformer. A dataset of 4240 ROSE images is collected to evaluate the method in this unexplored field. The proposed multi-stage hybrid Transformer (MSHT) achieves 95.68% in classification accuracy, which is distinctively higher than the state-of-the-art models. Facing the need for interpretability, MSHT outperforms its counterparts with more accurate attention regions. The results demonstrate that the MSHT can distinguish cancer samples accurately at an unprecedented image scale, laying the foundation for deploying automatic decision systems and enabling the expansion of ROSE in clinical practice. The code and records are available at: https://github.com/sagizty/Multi-Stage-Hybrid-Transformer.
Prior Attention Network for Multi-Lesion Segmentation in Medical Images
Oct 10, 2021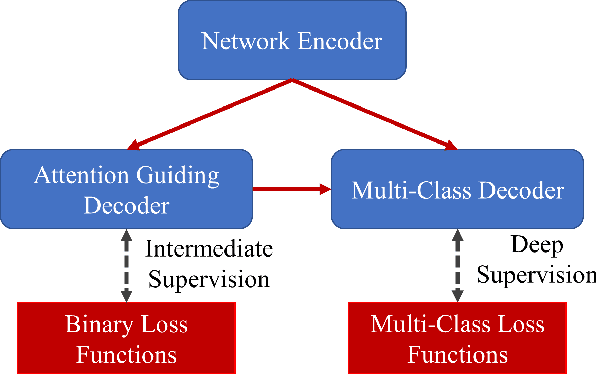
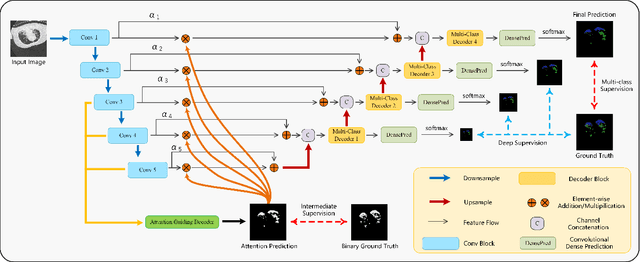
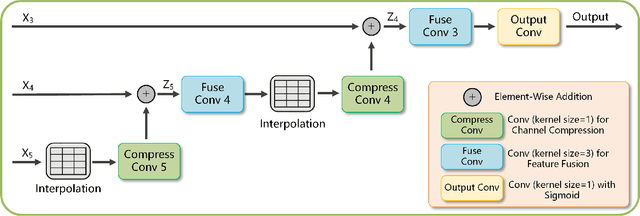
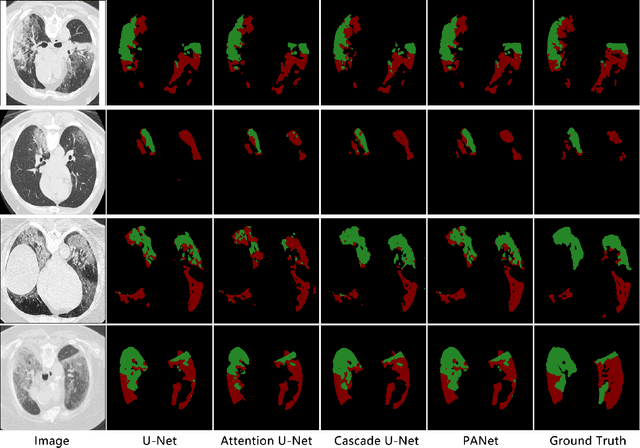
The accurate segmentation of multiple types of lesions from adjacent tissues in medical images is significant in clinical practice. Convolutional neural networks (CNNs) based on the coarse-to-fine strategy have been widely used in this field. However, multi-lesion segmentation remains to be challenging due to the uncertainty in size, contrast, and high interclass similarity of tissues. In addition, the commonly adopted cascaded strategy is rather demanding in terms of hardware, which limits the potential of clinical deployment. To address the problems above,we propose a novel Prior Attention Network (PANet) that follows the coarse-to-fine strategy to perform multi-lesion segmentation in medical images. The proposed network achieves the two steps of segmentation in a single network by inserting lesion-related spatial attention mechanism in the network. Further, we also propose the intermediate supervision strategy for generating lesion-related attention to acquire the regions of interest (ROIs), which accelerates the convergence and obviously improves the segmentation performance. We have investigated the proposed segmentation framework in two applications: 2D segmentation of multiple lung infections in lung CT slices and 3D segmentation of multiple lesions in brain MRIs. Experimental results show that in both 2D and 3D segmentation tasks our proposed network achieves better performance with less computational cost compared with cascaded networks. The proposed network can be regarded as a universal solution to multi-lesion segmentation in both 2D and 3D tasks. The source code is available at: https://github.com/hsiangyuzhao/PANet.
D2A U-Net: Automatic Segmentation of COVID-19 Lesions from CT Slices with Dilated Convolution and Dual Attention Mechanism
Feb 10, 2021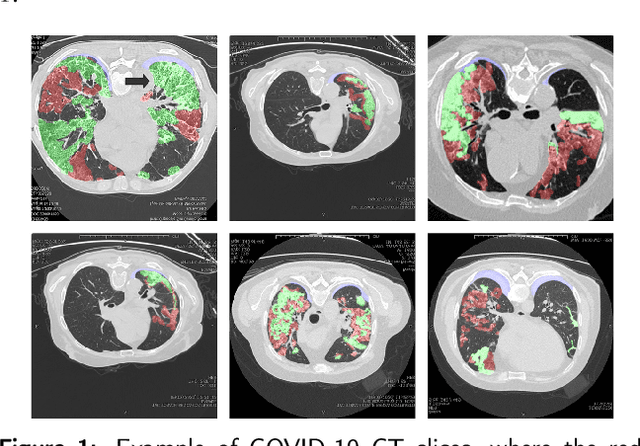
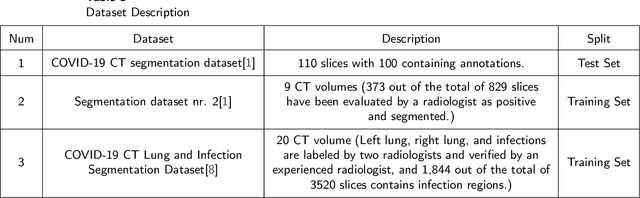
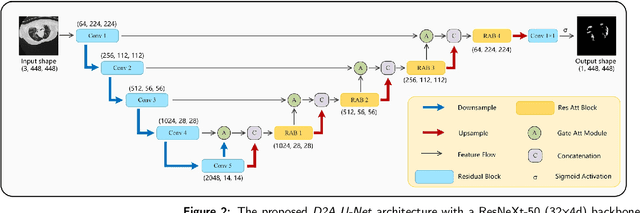

Coronavirus Disease 2019 (COVID-19) has caused great casualties and becomes almost the most urgent public health events worldwide. Computed tomography (CT) is a significant screening tool for COVID-19 infection, and automated segmentation of lung infection in COVID-19 CT images will greatly assist diagnosis and health care of patients. However, accurate and automatic segmentation of COVID-19 lung infections remains to be challenging. In this paper we propose a dilated dual attention U-Net (D2A U-Net) for COVID-19 lesion segmentation in CT slices based on dilated convolution and a novel dual attention mechanism to address the issues above. We introduce a dilated convolution module in model decoder to achieve large receptive field, which refines decoding process and contributes to segmentation accuracy. Also, we present a dual attention mechanism composed of two attention modules which are inserted to skip connection and model decoder respectively. The dual attention mechanism is utilized to refine feature maps and reduce semantic gap between different levels of the model. The proposed method has been evaluated on open-source dataset and outperforms cutting edges methods in semantic segmentation. Our proposed D2A U-Net with pretrained encoder achieves a Dice score of 0.7298 and recall score of 0.7071. Besides, we also build a simplified D2A U-Net without pretrained encoder to provide a fair comparison with other models trained from scratch, which still outperforms popular U-Net family models with a Dice score of 0.7047 and recall score of 0.6626. Our experiment results have shown that by introducing dilated convolution and dual attention mechanism, the number of false positives is significantly reduced, which improves sensitivity to COVID-19 lesions and subsequently brings significant increase to Dice score.