 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Pyramid Based Graph Reasoning for Semantic Segmentation
Mar 23, 2020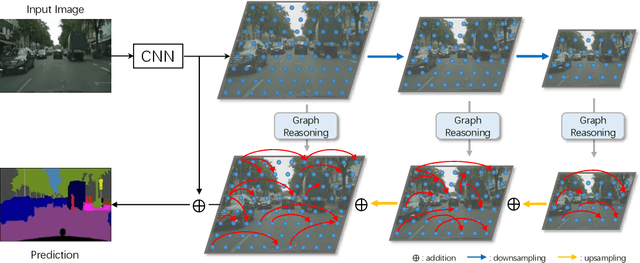
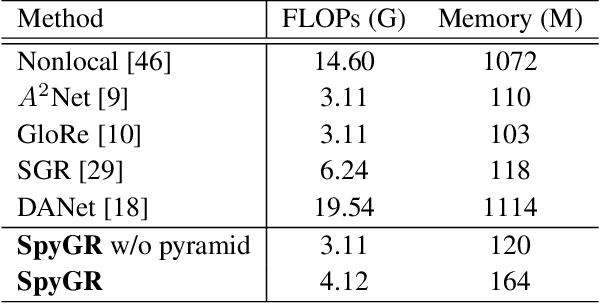
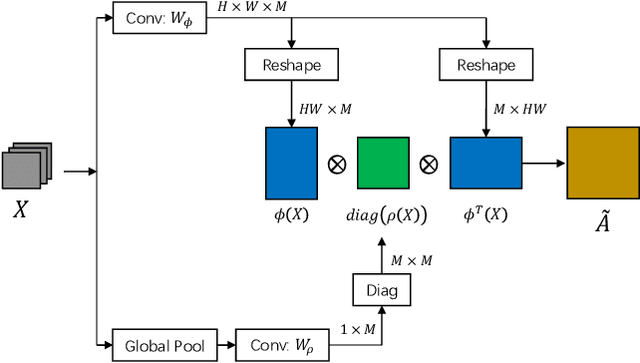
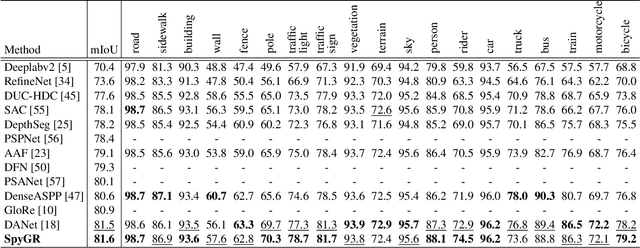
The convolution operation suffers from a limited receptive filed, while global modeling is fundamental to dense prediction tasks, such as semantic segmentation. In this paper, we apply graph convolution into the semantic segmentation task and propose an improved Laplacian. The graph reasoning is directly performed in the original feature space organized as a spatial pyramid. Different from existing methods, our Laplacian is data-dependent and we introduce an attention diagonal matrix to learn a better distance metric. It gets rid of projecting and re-projecting processes, which makes our proposed method a light-weight module that can be easily plugged into current computer vision architectures. More importantly, performing graph reasoning directly in the feature space retains spatial relationships and makes spatial pyramid possible to explore multiple long-range contextual patterns from different scales. Experiments on Cityscapes, COCO Stuff, PASCAL Context and PASCAL VOC demonstrate the effectiveness of our proposed methods on semantic segmentation. We achieve comparable performance with advantages in computational and memory overhead.
MFPN: A Novel Mixture Feature Pyramid Network of Multiple Architectures for Object Detection
Dec 20, 2019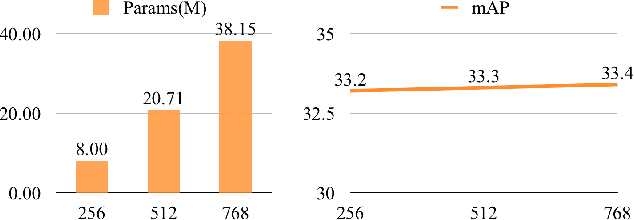
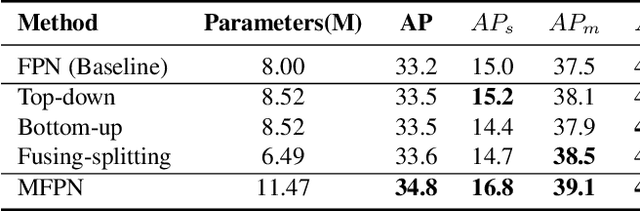
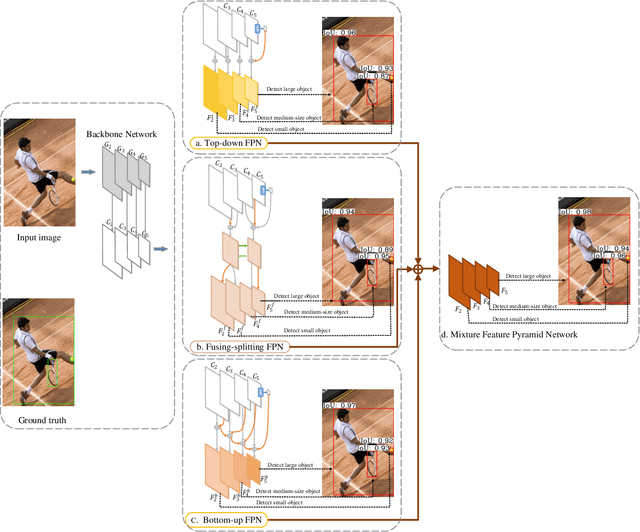
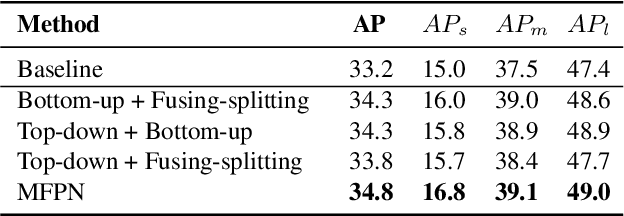
Feature pyramids are widely exploited in many detectors to solve the scale variation problem for object detection. In this paper, we first investigate the Feature Pyramid Network (FPN) architectures and briefly categorize them into three typical fashions: top-down, bottom-up and fusing-splitting, which have their own merits for detecting small objects, large objects, and medium-sized objects, respectively. Further, we design three FPNs of different architectures and propose a novel Mixture Feature Pyramid Network (MFPN) which inherits the merits of all these three kinds of FPNs, by assembling the three kinds of FPNs in a parallel multi-branch architecture and mixing the features. MFPN can significantly enhance both one-stage and two-stage FPN-based detectors with about 2 percent Average Precision(AP) increment on the MS-COCO benchmark, at little sacrifice in running time latency. By simply assembling MFPN with the one-stage and two-stage baseline detectors, we achieve competitive single-model detection results on the COCO detection benchmark without bells and whistles.
SOGNet: Scene Overlap Graph Network for Panoptic Segmentation
Nov 18, 2019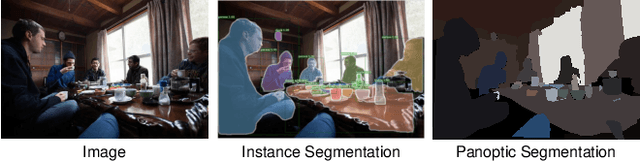
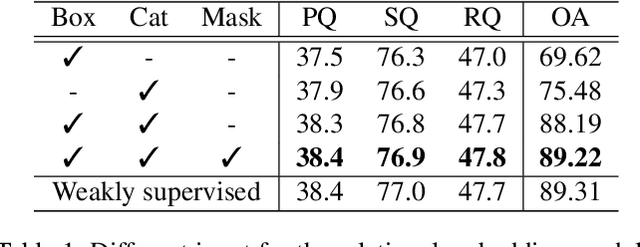
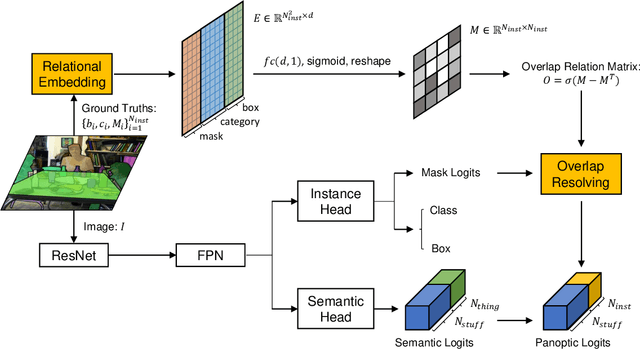
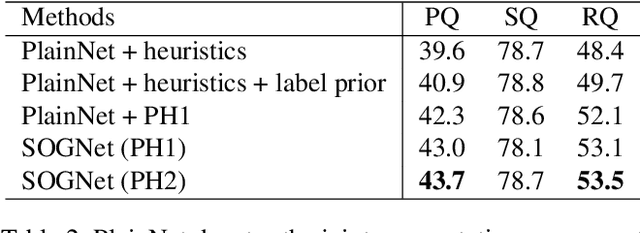
The panoptic segmentation task requires a unified result from semantic and instance segmentation outputs that may contain overlaps. However, current studies widely ignore modeling overlaps. In this study, we aim to model overlap relations among instances and resolve them for panoptic segmentation. Inspired by scene graph representation, we formulate the overlapping problem as a simplified case, named scene overlap graph. We leverage each object's category, geometry and appearance features to perform relational embedding, and output a relation matrix that encodes overlap relations. In order to overcome the lack of supervision, we introduce a differentiable module to resolve the overlap between any pair of instances. The mask logits after removing overlaps are fed into per-pixel instance \verb|id| classification, which leverages the panoptic supervision to assist in the modeling of overlap relations. Besides, we generate an approximate ground truth of overlap relations as the weak supervision, to quantify the accuracy of overlap relations predicted by our method. Experiments on COCO and Cityscapes demonstrate that our method is able to accurately predict overlap relations, and outperform the state-of-the-art performance for panoptic segmentation. Our method also won the Innovation Award in COCO 2019 challenge.
CBNet: A Novel Composite Backbone Network Architecture for Object Detection
Sep 09, 2019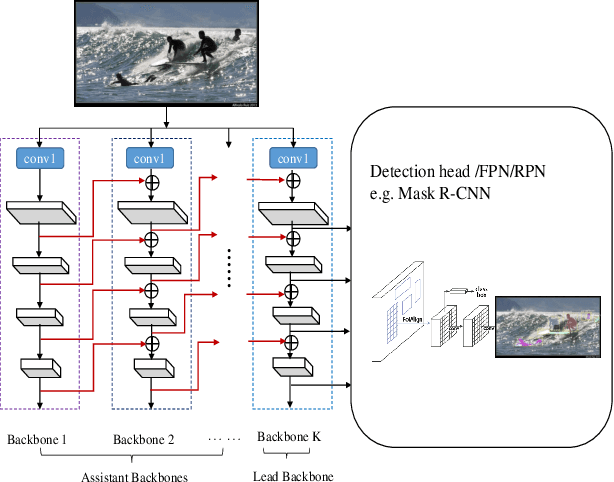


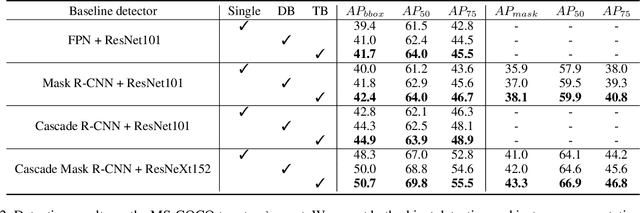
In existing CNN based detectors, the backbone network is a very important component for basic feature extraction, and the performance of the detectors highly depends on it. In this paper, we aim to achieve better detection performance by building a more powerful backbone from existing backbones like ResNet and ResNeXt. Specifically, we propose a novel strategy for assembling multiple identical backbones by composite connections between the adjacent backbones, to form a more powerful backbone named Composite Backbone Network (CBNet). In this way, CBNet iteratively feeds the output features of the previous backbone, namely high-level features, as part of input features to the succeeding backbone, in a stage-by-stage fashion, and finally the feature maps of the last backbone (named Lead Backbone) are used for object detection. We show that CBNet can be very easily integrated into most state-of-the-art detectors and significantly improve their performances. For example, it boosts the mAP of FPN, Mask R-CNN and Cascade R-CNN on the COCO dataset by about 1.5 to 3.0 percent. Meanwhile, experimental results show that the instance segmentation results can also be improved. Specially, by simply integrating the proposed CBNet into the baseline detector Cascade Mask R-CNN, we achieve a new state-of-the-art result on COCO dataset (mAP of 53.3) with single model, which demonstrates great effectiveness of the proposed CBNet architecture. Code will be made available on https://github.com/PKUbahuangliuhe/CBNet.
MMDetection: Open MMLab Detection Toolbox and Benchmark
Jun 17, 2019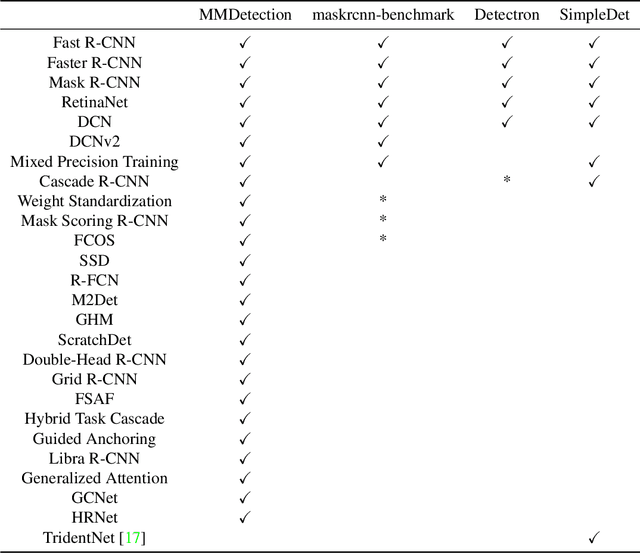
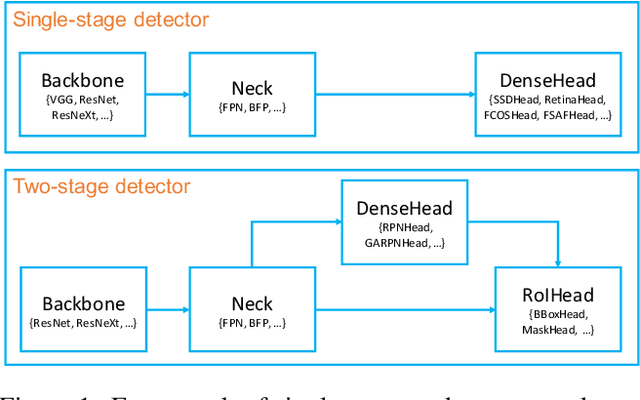
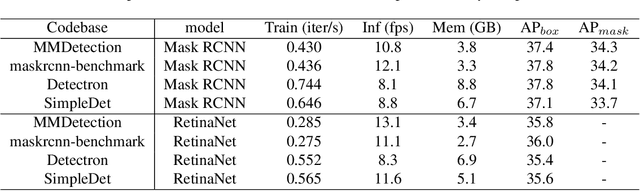
We present MMDetection, an object detection toolbox that contains a rich set of object detection and instance segmentation methods as well as related components and modules. The toolbox started from a codebase of MMDet team who won the detection track of COCO Challenge 2018. It gradually evolves into a unified platform that covers many popular detection methods and contemporary modules. It not only includes training and inference codes, but also provides weights for more than 200 network models. We believe this toolbox is by far the most complete detection toolbox. In this paper, we introduce the various features of this toolbox. In addition, we also conduct a benchmarking study on different methods, components, and their hyper-parameters. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new detectors. Code and models are available at https://github.com/open-mmlab/mmdetection. The project is under active development and we will keep this document updated.
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
Nov 13, 2018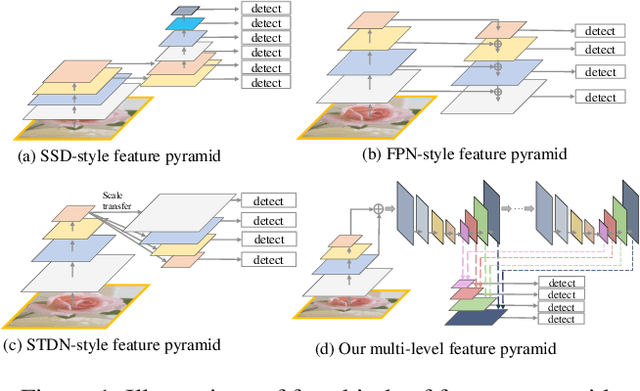
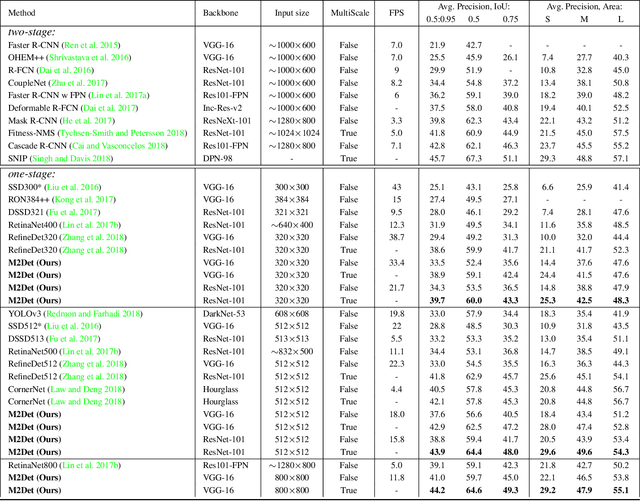
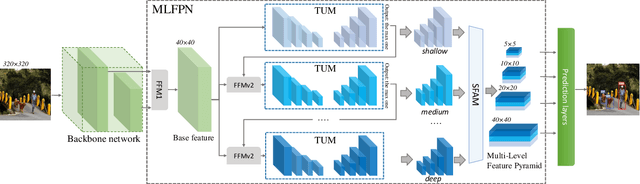
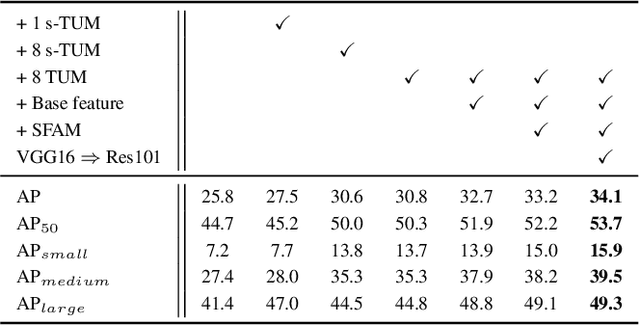
Feature pyramids are widely exploited by both the state-of-the-art one-stage object detectors (e.g., DSSD, RetinaNet, RefineDet) and the two-stage object detectors (e.g., Mask R-CNN, DetNet) to alleviate the problem arising from scale variation across object instances. Although these object detectors with feature pyramids achieve encouraging results, they have some limitations due to that they only simply construct the feature pyramid according to the inherent multi-scale, pyramidal architecture of the backbones which are actually designed for object classification task. Newly, in this work, we present a method called Multi-Level Feature Pyramid Network (MLFPN) to construct more effective feature pyramids for detecting objects of different scales. First, we fuse multi-level features (i.e. multiple layers) extracted by backbone as the base feature. Second, we feed the base feature into a block of alternating joint Thinned U-shape Modules and Feature Fusion Modules and exploit the decoder layers of each u-shape module as the features for detecting objects. Finally, we gather up the decoder layers with equivalent scales (sizes) to develop a feature pyramid for object detection, in which every feature map consists of the layers (features) from multiple levels. To evaluate the effectiveness of the proposed MLFPN, we design and train a powerful end-to-end one-stage object detector we call M2Det by integrating it into the architecture of SSD, which gets better detection performance than state-of-the-art one-stage detectors. Specifically, on MS-COCO benchmark, M2Det achieves AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy and AP of 44.2 with multi-scale inference strategy, which is the new state-of-the-art results among one-stage detectors. The code will be made available on \url{https://github.com/qijiezhao/M2Det.
CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving
Oct 10, 2018
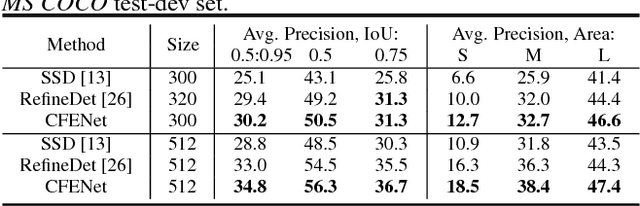


The ability to detect small objects and the speed of the object detector are very important for the application of autonomous driving, and in this paper, we propose an effective yet efficient one-stage detector, which gained the second place in the Road Object Detection competition of CVPR2018 workshop - Workshop of Autonomous Driving(WAD). The proposed detector inherits the architecture of SSD and introduces a novel Comprehensive Feature Enhancement(CFE) module into it. Experimental results on this competition dataset as well as the MSCOCO dataset demonstrate that the proposed detector (named CFENet) performs much better than the original SSD and the state-of-the-art method RefineDet especially for small objects, while keeping high efficiency close to the original SSD. Specifically, the single scale version of the proposed detector can run at the speed of 21 fps, while the multi-scale version with larger input size achieves the mAP 29.69, ranking second on the leaderboard
Deep Dual Pyramid Network for Barcode Segmentation using Barcode-30k Database
Jul 31, 2018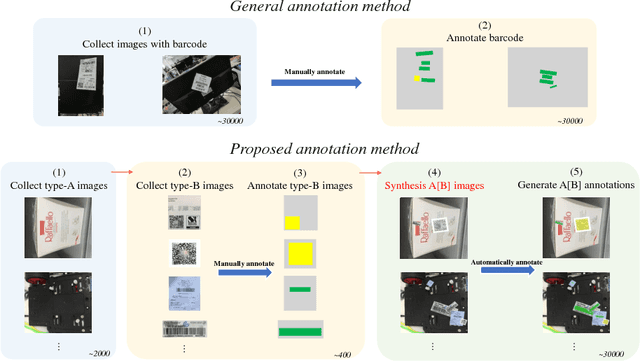



Digital signs(such as barcode or QR code) are widely used in our daily life, and for many applications, we need to localize them on images. However, difficult cases such as targets with small scales, half-occlusion, shape deformation and large illumination changes cause challenges for conventional methods. In this paper, we address this problem by producing a large-scale dataset and adopting a deep learning based semantic segmentation approach. Specifically, a synthesizing method was proposed to generate well-annotated images containing barcode and QR code labels, which contributes to largely decrease the annotation time. Through the synthesis strategy, we introduce a dataset that contains 30000 images with Barcode and QR code - Barcode-30k. Moreover, we further propose a dual pyramid structure based segmentation network - BarcodeNet, which is mainly formed with two novel modules, Prior Pyramid Pooling Module(P3M) and Pyramid Refine Module(PRM). We validate the effectiveness of BarcodeNet on the proposed synthetic dataset, and it yields the result of mIoU accuracy 95.36\% on validation set. Additional segmentation results of real images have shown that accurate segmentation performance is achieved.
Exploiting Spatial-Temporal Modelling and Multi-Modal Fusion for Human Action Recognition
Jun 27, 2018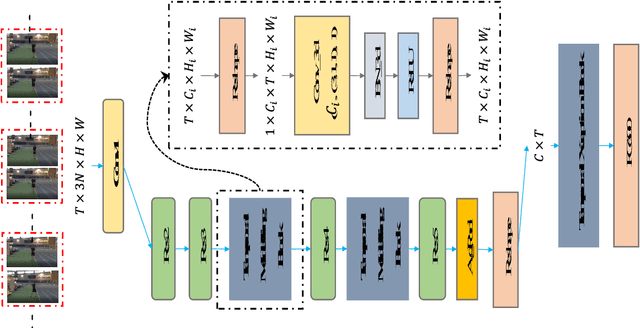

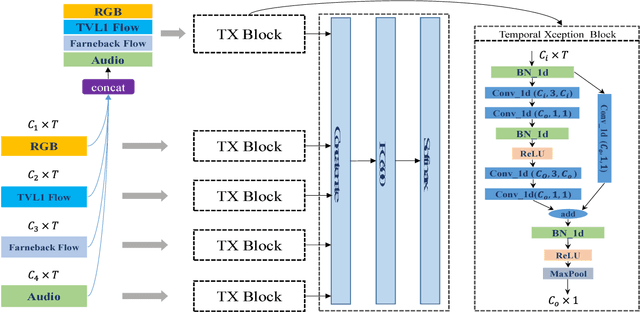

In this report, our approach to tackling the task of ActivityNet 2018 Kinetics-600 challenge is described in detail. Though spatial-temporal modelling methods, which adopt either such end-to-end framework as I3D \cite{i3d} or two-stage frameworks (i.e., CNN+RNN), have been proposed in existing state-of-the-arts for this task, video modelling is far from being well solved. In this challenge, we propose spatial-temporal network (StNet) for better joint spatial-temporal modelling and comprehensively video understanding. Besides, given that multi-modal information is contained in video source, we manage to integrate both early-fusion and later-fusion strategy of multi-modal information via our proposed improved temporal Xception network (iTXN) for video understanding. Our StNet RGB single model achieves 78.99\% top-1 precision in the Kinetics-600 validation set and that of our improved temporal Xception network which integrates RGB, flow and audio modalities is up to 82.35\%. After model ensemble, we achieve top-1 precision as high as 85.0\% on the validation set and rank No.1 among all submissions.