 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Spatial-Temporal Modelling and Multi-Modal Fusion for Human Action Recognition
Paper and Code
Jun 27, 2018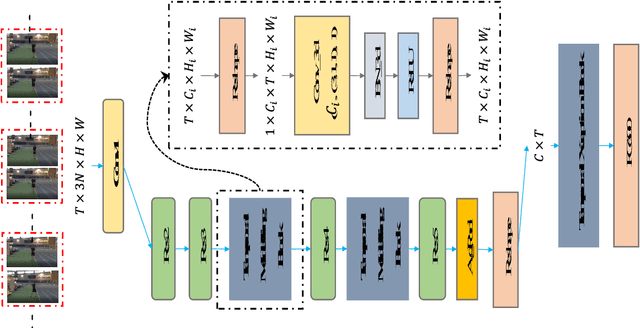

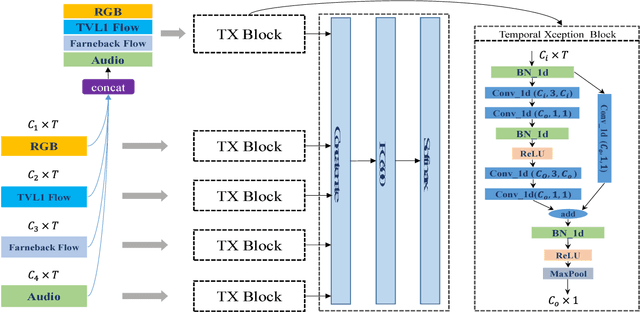

In this report, our approach to tackling the task of ActivityNet 2018 Kinetics-600 challenge is described in detail. Though spatial-temporal modelling methods, which adopt either such end-to-end framework as I3D \cite{i3d} or two-stage frameworks (i.e., CNN+RNN), have been proposed in existing state-of-the-arts for this task, video modelling is far from being well solved. In this challenge, we propose spatial-temporal network (StNet) for better joint spatial-temporal modelling and comprehensively video understanding. Besides, given that multi-modal information is contained in video source, we manage to integrate both early-fusion and later-fusion strategy of multi-modal information via our proposed improved temporal Xception network (iTXN) for video understanding. Our StNet RGB single model achieves 78.99\% top-1 precision in the Kinetics-600 validation set and that of our improved temporal Xception network which integrates RGB, flow and audio modalities is up to 82.35\%. After model ensemble, we achieve top-1 precision as high as 85.0\% on the validation set and rank No.1 among all submissions.