 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiSem: Hierarchical Semantic Disentangling for Remote Sensing Image Change Captioning
May 14, 2026Remote sensing image change captioning (RSICC) aims to achieve high-level semantic understanding of genuine changes occurring between bi-temporal images. Despite notable progress, existing methods are fundamentally limited by a shared modeling assumption: changed and unchanged image pairs, which have intrinsically different semantic granularities, are processed under a unified modeling strategy. This modeling inconsistency leads to semantic entanglement between coarse-grained change existence judgment and fine-grained semantic understanding.To address the above limitation, we propose a novel hierarchical semantic disentangling network (HiSem) that explicitly disentangles semantic representations of different granularities. Specifically, we first introduce the Bidirectional Differential Attention Modulation (BDAM) module that leverages discrepancy-aware attention to enhance cross-temporal interactions, thereby amplifying true change signals while suppressing irrelevant variations. Building upon this, we design a Hierarchical Adaptive Semantic Disentanglement (HASD) module that performs adaptive routing at two hierarchical levels: a coarse-grained image-level routing mechanism distinguishes changed and unchanged image pairs, while a fine-grained token-level Mixture-of-Experts (MoE) block models diverse and heterogeneous change semantics for changed samples. Extensive experiments on two benchmark datasets demonstrate that HiSem outperfoms previous methods, achieving a significant improvement of +7.52\% BLEU-4 on the WHU-CDC dataset. More importantly, our approach provides a structured perspective for RSICC by explicitly aligning model design with the intrinsic semantic heterogeneity of bi-temporal scenes. The code will be available at https://github.com/Man-Wang-star/HiSem
PP-DocBee: Improving Multimodal Document Understanding Through a Bag of Tricks
Mar 06, 2025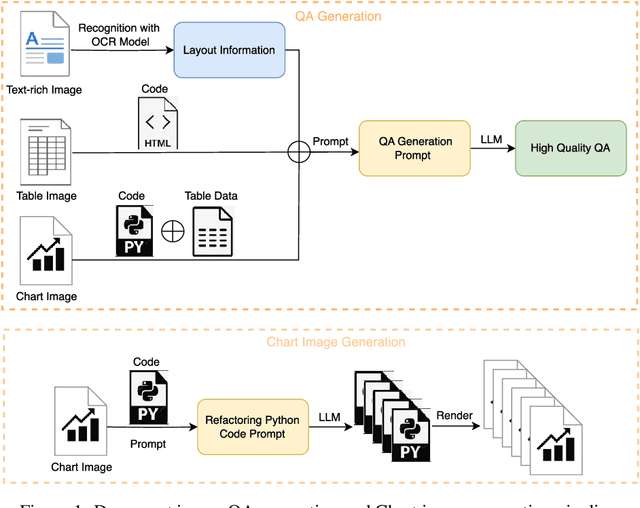

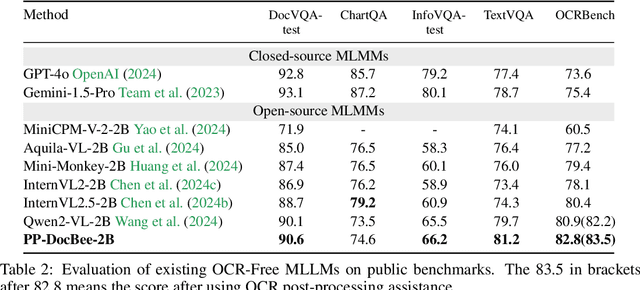
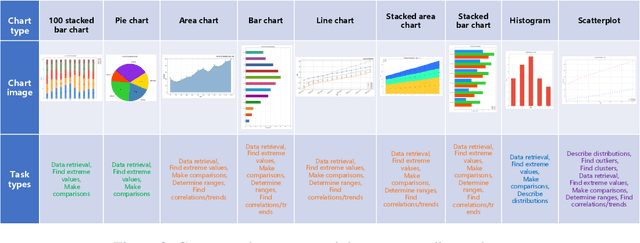
With the rapid advancement of digitalization, various document images are being applied more extensively in production and daily life, and there is an increasingly urgent need for fast and accurate parsing of the content in document images. Therefore, this report presents PP-DocBee, a novel multimodal large language model designed for end-to-end document image understanding. First, we develop a data synthesis strategy tailored to document scenarios in which we build a diverse dataset to improve the model generalization. Then, we apply a few training techniques, including dynamic proportional sampling, data preprocessing, and OCR postprocessing strategies. Extensive evaluations demonstrate the superior performance of PP-DocBee, achieving state-of-the-art results on English document understanding benchmarks and even outperforming existing open source and commercial models in Chinese document understanding. The source code and pre-trained models are publicly available at \href{https://github.com/PaddlePaddle/PaddleMIX}{https://github.com/PaddlePaddle/PaddleMIX}.
PF-Net: Point Fractal Network for 3D Point Cloud Completion
Mar 01, 2020
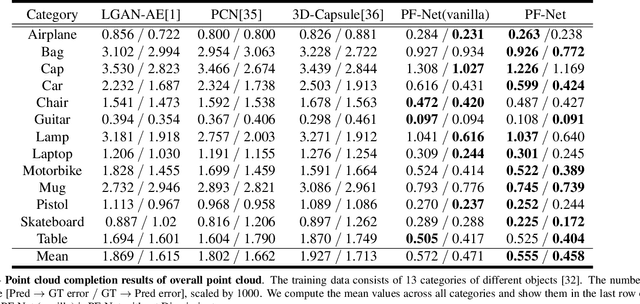

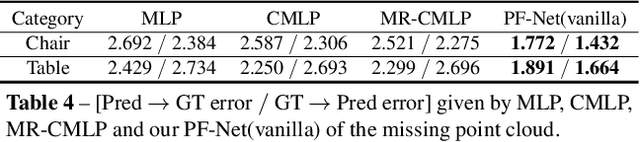
In this paper, we propose a Point Fractal Network (PF-Net), a novel learning-based approach for precise and high-fidelity point cloud completion. Unlike existing point cloud completion networks, which generate the overall shape of the point cloud from the incomplete point cloud and always change existing points and encounter noise and geometrical loss, PF-Net preserves the spatial arrangements of the incomplete point cloud and can figure out the detailed geometrical structure of the missing region(s) in the prediction. To succeed at this task, PF-Net estimates the missing point cloud hierarchically by utilizing a feature-points-based multi-scale generating network. Further, we add up multi-stage completion loss and adversarial loss to generate more realistic missing region(s). The adversarial loss can better tackle multiple modes in the prediction. Our experiments demonstrate the effectiveness of our method for several challenging point cloud completion tasks.
CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving
Oct 10, 2018
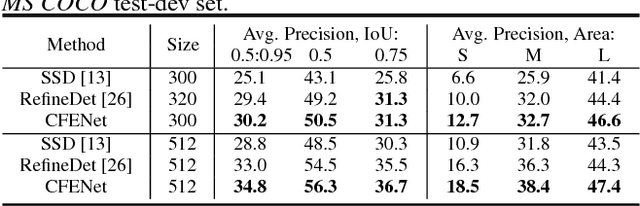


The ability to detect small objects and the speed of the object detector are very important for the application of autonomous driving, and in this paper, we propose an effective yet efficient one-stage detector, which gained the second place in the Road Object Detection competition of CVPR2018 workshop - Workshop of Autonomous Driving(WAD). The proposed detector inherits the architecture of SSD and introduces a novel Comprehensive Feature Enhancement(CFE) module into it. Experimental results on this competition dataset as well as the MSCOCO dataset demonstrate that the proposed detector (named CFENet) performs much better than the original SSD and the state-of-the-art method RefineDet especially for small objects, while keeping high efficiency close to the original SSD. Specifically, the single scale version of the proposed detector can run at the speed of 21 fps, while the multi-scale version with larger input size achieves the mAP 29.69, ranking second on the leaderboard
Deep Dual Pyramid Network for Barcode Segmentation using Barcode-30k Database
Jul 31, 2018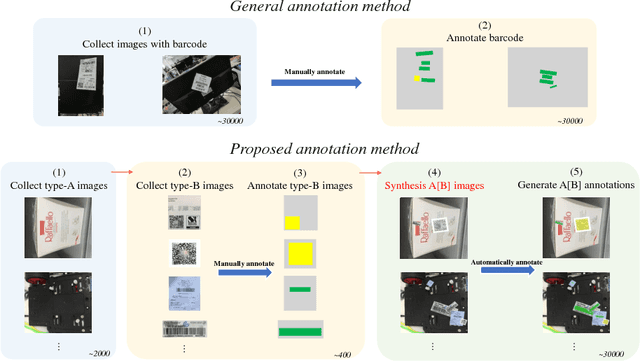



Digital signs(such as barcode or QR code) are widely used in our daily life, and for many applications, we need to localize them on images. However, difficult cases such as targets with small scales, half-occlusion, shape deformation and large illumination changes cause challenges for conventional methods. In this paper, we address this problem by producing a large-scale dataset and adopting a deep learning based semantic segmentation approach. Specifically, a synthesizing method was proposed to generate well-annotated images containing barcode and QR code labels, which contributes to largely decrease the annotation time. Through the synthesis strategy, we introduce a dataset that contains 30000 images with Barcode and QR code - Barcode-30k. Moreover, we further propose a dual pyramid structure based segmentation network - BarcodeNet, which is mainly formed with two novel modules, Prior Pyramid Pooling Module(P3M) and Pyramid Refine Module(PRM). We validate the effectiveness of BarcodeNet on the proposed synthetic dataset, and it yields the result of mIoU accuracy 95.36\% on validation set. Additional segmentation results of real images have shown that accurate segmentation performance is achieved.