 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisyAG-News: A Benchmark for Addressing Instance-Dependent Noise in Text Classification
Jul 09, 2024



Existing research on learning with noisy labels predominantly focuses on synthetic label noise. Although synthetic noise possesses well-defined structural properties, it often fails to accurately replicate real-world noise patterns. In recent years, there has been a concerted effort to construct generalizable and controllable instance-dependent noise datasets for image classification, significantly advancing the development of noise-robust learning in this area. However, studies on noisy label learning for text classification remain scarce. To better understand label noise in real-world text classification settings, we constructed the benchmark dataset NoisyAG-News through manual annotation. Initially, we analyzed the annotated data to gather observations about real-world noise. We qualitatively and quantitatively demonstrated that real-world noisy labels adhere to instance-dependent patterns. Subsequently, we conducted comprehensive learning experiments on NoisyAG-News and its corresponding synthetic noise datasets using pre-trained language models and noise-handling techniques. Our findings reveal that while pre-trained models are resilient to synthetic noise, they struggle against instance-dependent noise, with samples of varying confusion levels showing inconsistent performance during training and testing. These real-world noise patterns pose new, significant challenges, prompting a reevaluation of noisy label handling methods. We hope that NoisyAG-News will facilitate the development and evaluation of future solutions for learning with noisy labels.
Grey-informed neural network for time-series forecasting
Apr 03, 2024Neural network models have shown outstanding performance and successful resolutions to complex problems in various fields. However, the majority of these models are viewed as black-box, requiring a significant amount of data for development. Consequently, in situations with limited data, constructing appropriate models becomes challenging due to the lack of transparency and scarcity of data. To tackle these challenges, this study suggests the implementation of a grey-informed neural network (GINN). The GINN ensures that the output of the neural network follows the differential equation model of the grey system, improving interpretability. Moreover, incorporating prior knowledge from grey system theory enables traditional neural networks to effectively handle small data samples. Our proposed model has been observed to uncover underlying patterns in the real world and produce reliable forecasts based on empirical data.
PILL: Plug Into LLM with Adapter Expert and Attention Gate
Nov 03, 2023Due to the remarkable capabilities of powerful Large Language Models (LLMs) in effectively following instructions, there has been a growing number of assistants in the community to assist humans. Recently, significant progress has been made in the development of Vision Language Models (VLMs), expanding the capabilities of LLMs and enabling them to execute more diverse instructions. However, it is foreseeable that models will likely need to handle tasks involving additional modalities such as speech, video, and others. This poses a particularly prominent challenge of dealing with the complexity of mixed modalities. To address this, we introduce a novel architecture called PILL: Plug Into LLM with adapter expert and attention gate to better decouple these complex modalities and leverage efficient fine-tuning. We introduce two modules: Firstly, utilizing Mixture-of-Modality-Adapter-Expert to independently handle different modalities, enabling better adaptation to downstream tasks while preserving the expressive capability of the original model. Secondly, by introducing Modality-Attention-Gating, which enables adaptive control of the contribution of modality tokens to the overall representation. In addition, we have made improvements to the Adapter to enhance its learning and expressive capabilities. Experimental results demonstrate that our approach exhibits competitive performance compared to other mainstream methods for modality fusion. For researchers interested in our work, we provide free access to the code and models at https://github.com/DsaltYfish/PILL.
All Labels Together: Low-shot Intent Detection with an Efficient Label Semantic Encoding Paradigm
Sep 08, 2023



In intent detection tasks, leveraging meaningful semantic information from intent labels can be particularly beneficial for few-shot scenarios. However, existing few-shot intent detection methods either ignore the intent labels, (e.g. treating intents as indices) or do not fully utilize this information (e.g. only using part of the intent labels). In this work, we present an end-to-end One-to-All system that enables the comparison of an input utterance with all label candidates. The system can then fully utilize label semantics in this way. Experiments on three few-shot intent detection tasks demonstrate that One-to-All is especially effective when the training resource is extremely scarce, achieving state-of-the-art performance in 1-, 3- and 5-shot settings. Moreover, we present a novel pretraining strategy for our model that utilizes indirect supervision from paraphrasing, enabling zero-shot cross-domain generalization on intent detection tasks. Our code is at https://github.com/jiangshdd/AllLablesTogether.
Spectral Adversarial Training for Robust Graph Neural Network
Nov 20, 2022Recent studies demonstrate that Graph Neural Networks (GNNs) are vulnerable to slight but adversarially designed perturbations, known as adversarial examples. To address this issue, robust training methods against adversarial examples have received considerable attention in the literature. \emph{Adversarial Training (AT)} is a successful approach to learning a robust model using adversarially perturbed training samples. Existing AT methods on GNNs typically construct adversarial perturbations in terms of graph structures or node features. However, they are less effective and fraught with challenges on graph data due to the discreteness of graph structure and the relationships between connected examples. In this work, we seek to address these challenges and propose Spectral Adversarial Training (SAT), a simple yet effective adversarial training approach for GNNs. SAT first adopts a low-rank approximation of the graph structure based on spectral decomposition, and then constructs adversarial perturbations in the spectral domain rather than directly manipulating the original graph structure. To investigate its effectiveness, we employ SAT on three widely used GNNs. Experimental results on four public graph datasets demonstrate that SAT significantly improves the robustness of GNNs against adversarial attacks without sacrificing classification accuracy and training efficiency.
FlowNAS: Neural Architecture Search for Optical Flow Estimation
Jul 04, 2022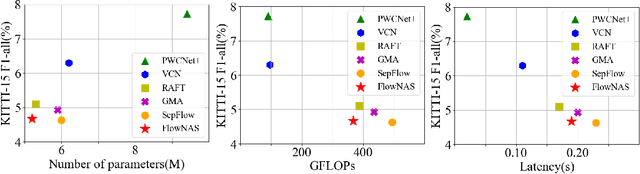
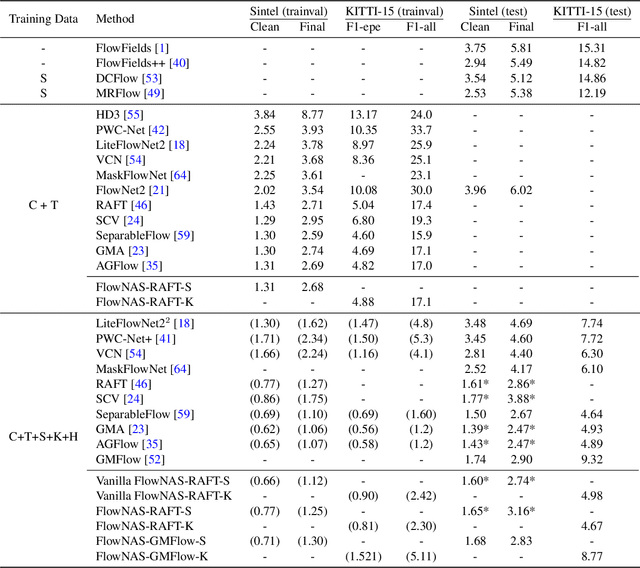
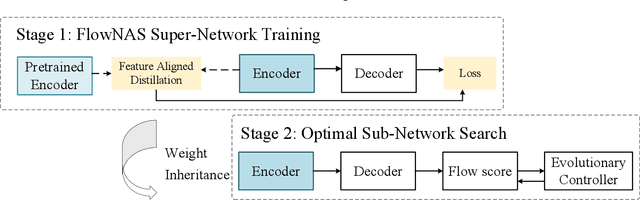
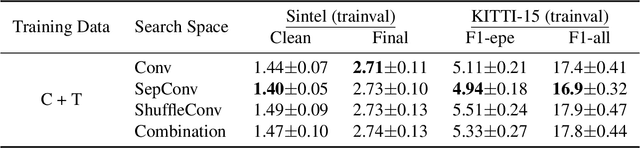
Existing optical flow estimators usually employ the network architectures typically designed for image classification as the encoder to extract per-pixel features. However, due to the natural difference between the tasks, the architectures designed for image classification may be sub-optimal for flow estimation. To address this issue, we propose a neural architecture search method named FlowNAS to automatically find the better encoder architecture for flow estimation task. We first design a suitable search space including various convolutional operators and construct a weight-sharing super-network for efficiently evaluating the candidate architectures. Then, for better training the super-network, we propose Feature Alignment Distillation, which utilizes a well-trained flow estimator to guide the training of super-network. Finally, a resource-constrained evolutionary algorithm is exploited to find an optimal architecture (i.e., sub-network). Experimental results show that the discovered architecture with the weights inherited from the super-network achieves 4.67\% F1-all error on KITTI, an 8.4\% reduction of RAFT baseline, surpassing state-of-the-art handcrafted models GMA and AGFlow, while reducing the model complexity and latency. The source code and trained models will be released in https://github.com/VDIGPKU/FlowNAS.
Benchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection
May 30, 2022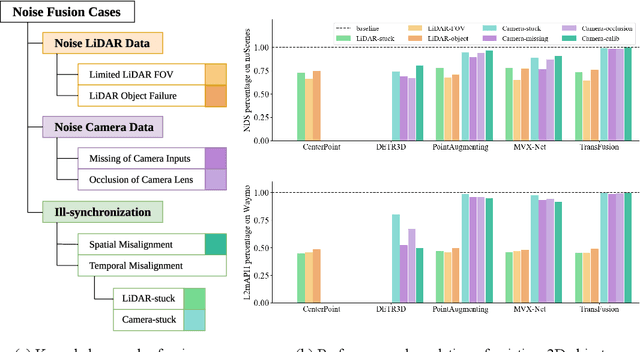
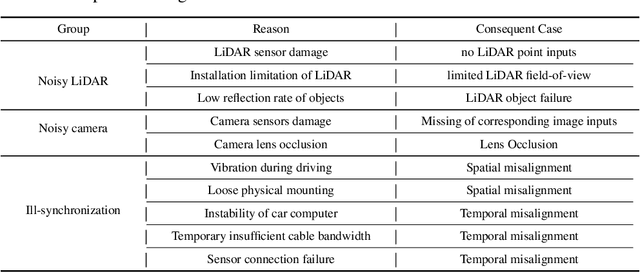
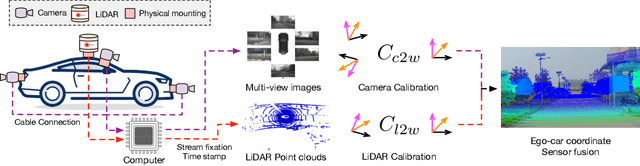
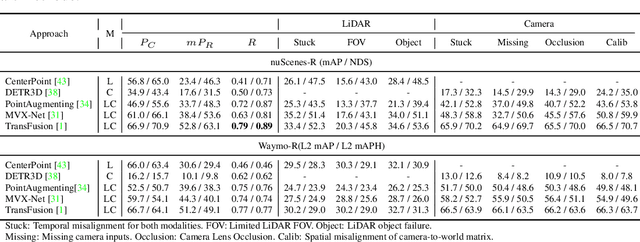
There are two critical sensors for 3D perception in autonomous driving, the camera and the LiDAR. The camera provides rich semantic information such as color, texture, and the LiDAR reflects the 3D shape and locations of surrounding objects. People discover that fusing these two modalities can significantly boost the performance of 3D perception models as each modality has complementary information to the other. However, we observe that current datasets are captured from expensive vehicles that are explicitly designed for data collection purposes, and cannot truly reflect the realistic data distribution due to various reasons. To this end, we collect a series of real-world cases with noisy data distribution, and systematically formulate a robustness benchmark toolkit, that simulates these cases on any clean autonomous driving datasets. We showcase the effectiveness of our toolkit by establishing the robustness benchmark on two widely-adopted autonomous driving datasets, nuScenes and Waymo, then, to the best of our knowledge, holistically benchmark the state-of-the-art fusion methods for the first time. We observe that: i) most fusion methods, when solely developed on these data, tend to fail inevitably when there is a disruption to the LiDAR input; ii) the improvement of the camera input is significantly inferior to the LiDAR one. We further propose an efficient robust training strategy to improve the robustness of the current fusion method. The benchmark and code are available at https://github.com/kcyu2014/lidar-camera-robust-benchmark
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022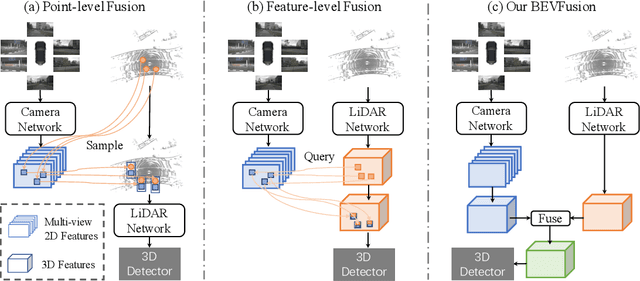

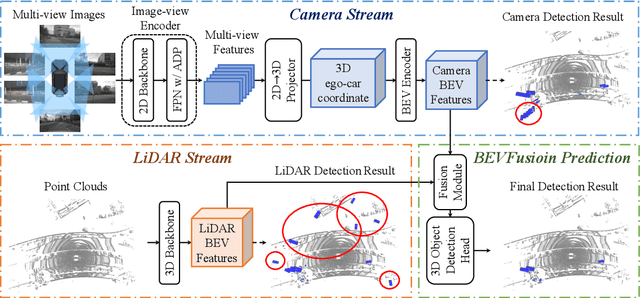
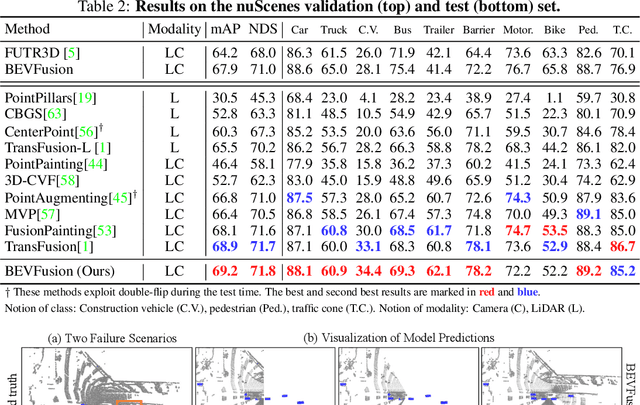
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
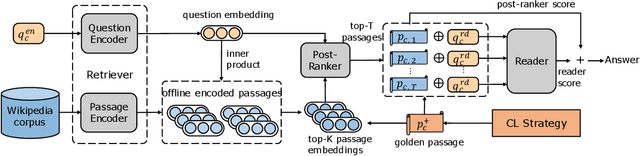
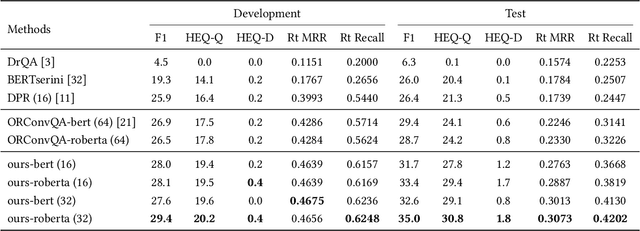
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.
CBNetV2: A Composite Backbone Network Architecture for Object Detection
Jul 29, 2021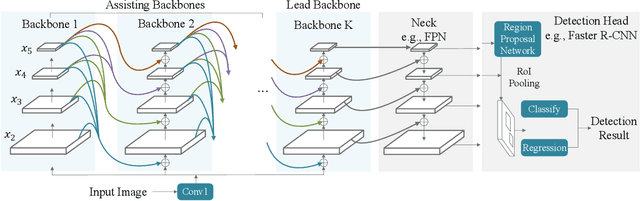
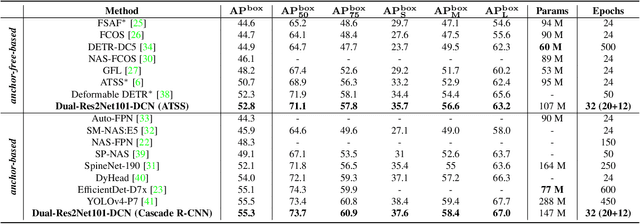
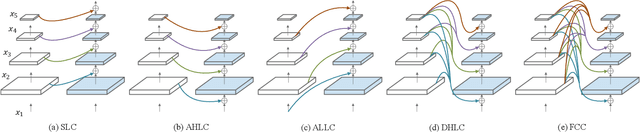
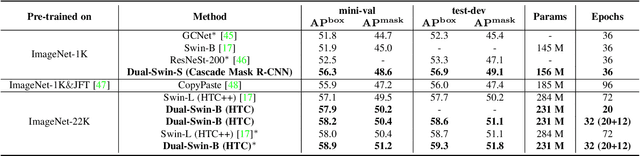
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. We also propose a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNetV2 introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our Dual-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which is significantly better than the state-of-the-art result (57.7% box AP and 50.2% mask AP) achieved by Swin-L, while the training schedule is reduced by 6$\times$. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data. Code is available at https://github.com/VDIGPKU/CBNetV2.