 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Robustness of LiDAR-Camera Fusion for 3D Object Detection
May 30, 2022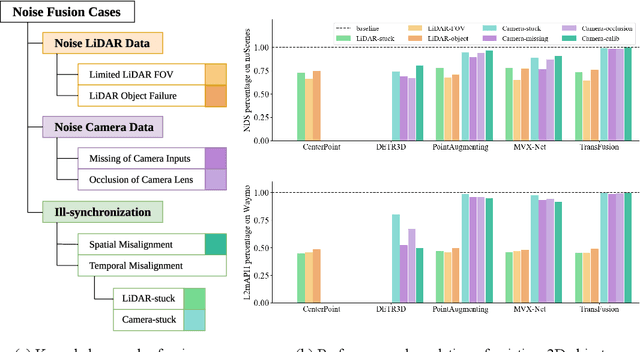
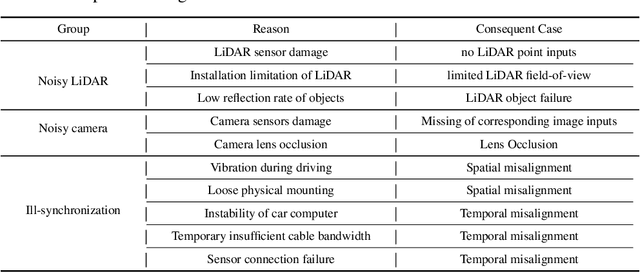
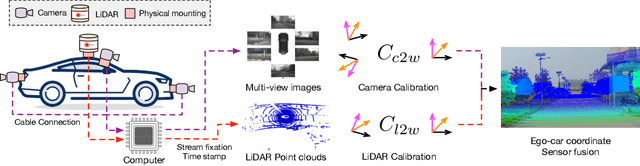
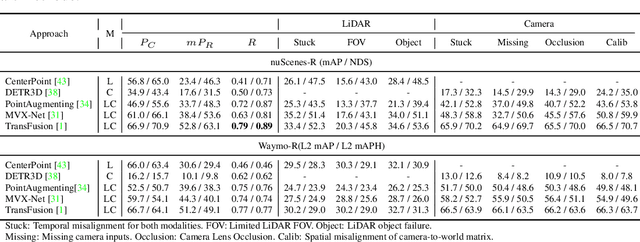
There are two critical sensors for 3D perception in autonomous driving, the camera and the LiDAR. The camera provides rich semantic information such as color, texture, and the LiDAR reflects the 3D shape and locations of surrounding objects. People discover that fusing these two modalities can significantly boost the performance of 3D perception models as each modality has complementary information to the other. However, we observe that current datasets are captured from expensive vehicles that are explicitly designed for data collection purposes, and cannot truly reflect the realistic data distribution due to various reasons. To this end, we collect a series of real-world cases with noisy data distribution, and systematically formulate a robustness benchmark toolkit, that simulates these cases on any clean autonomous driving datasets. We showcase the effectiveness of our toolkit by establishing the robustness benchmark on two widely-adopted autonomous driving datasets, nuScenes and Waymo, then, to the best of our knowledge, holistically benchmark the state-of-the-art fusion methods for the first time. We observe that: i) most fusion methods, when solely developed on these data, tend to fail inevitably when there is a disruption to the LiDAR input; ii) the improvement of the camera input is significantly inferior to the LiDAR one. We further propose an efficient robust training strategy to improve the robustness of the current fusion method. The benchmark and code are available at https://github.com/kcyu2014/lidar-camera-robust-benchmark