 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAS-BNN: Neural Architecture Search for Binary Neural Networks
Aug 28, 2024



Binary Neural Networks (BNNs) have gained extensive attention for their superior inferencing efficiency and compression ratio compared to traditional full-precision networks. However, due to the unique characteristics of BNNs, designing a powerful binary architecture is challenging and often requires significant manpower. A promising solution is to utilize Neural Architecture Search (NAS) to assist in designing BNNs, but current NAS methods for BNNs are relatively straightforward and leave a performance gap between the searched models and manually designed ones. To address this gap, we propose a novel neural architecture search scheme for binary neural networks, named NAS-BNN. We first carefully design a search space based on the unique characteristics of BNNs. Then, we present three training strategies, which significantly enhance the training of supernet and boost the performance of all subnets. Our discovered binary model family outperforms previous BNNs for a wide range of operations (OPs) from 20M to 200M. For instance, we achieve 68.20% top-1 accuracy on ImageNet with only 57M OPs. In addition, we validate the transferability of these searched BNNs on the object detection task, and our binary detectors with the searched BNNs achieve a novel state-of-the-art result, e.g., 31.6% mAP with 370M OPs, on MS COCO dataset. The source code and models will be released at https://github.com/VDIGPKU/NAS-BNN.
SCSC: Spatial Cross-scale Convolution Module to Strengthen both CNNs and Transformers
Aug 14, 2023



This paper presents a module, Spatial Cross-scale Convolution (SCSC), which is verified to be effective in improving both CNNs and Transformers. Nowadays, CNNs and Transformers have been successful in a variety of tasks. Especially for Transformers, increasing works achieve state-of-the-art performance in the computer vision community. Therefore, researchers start to explore the mechanism of those architectures. Large receptive fields, sparse connections, weight sharing, and dynamic weight have been considered keys to designing effective base models. However, there are still some issues to be addressed: large dense kernels and self-attention are inefficient, and large receptive fields make it hard to capture local features. Inspired by the above analyses and to solve the mentioned problems, in this paper, we design a general module taking in these design keys to enhance both CNNs and Transformers. SCSC introduces an efficient spatial cross-scale encoder and spatial embed module to capture assorted features in one layer. On the face recognition task, FaceResNet with SCSC can improve 2.7% with 68% fewer FLOPs and 79% fewer parameters. On the ImageNet classification task, Swin Transformer with SCSC can achieve even better performance with 22% fewer FLOPs, and ResNet with CSCS can improve 5.3% with similar complexity. Furthermore, a traditional network (e.g., ResNet) embedded with SCSC can match Swin Transformer's performance.
DynamicDet: A Unified Dynamic Architecture for Object Detection
Apr 12, 2023
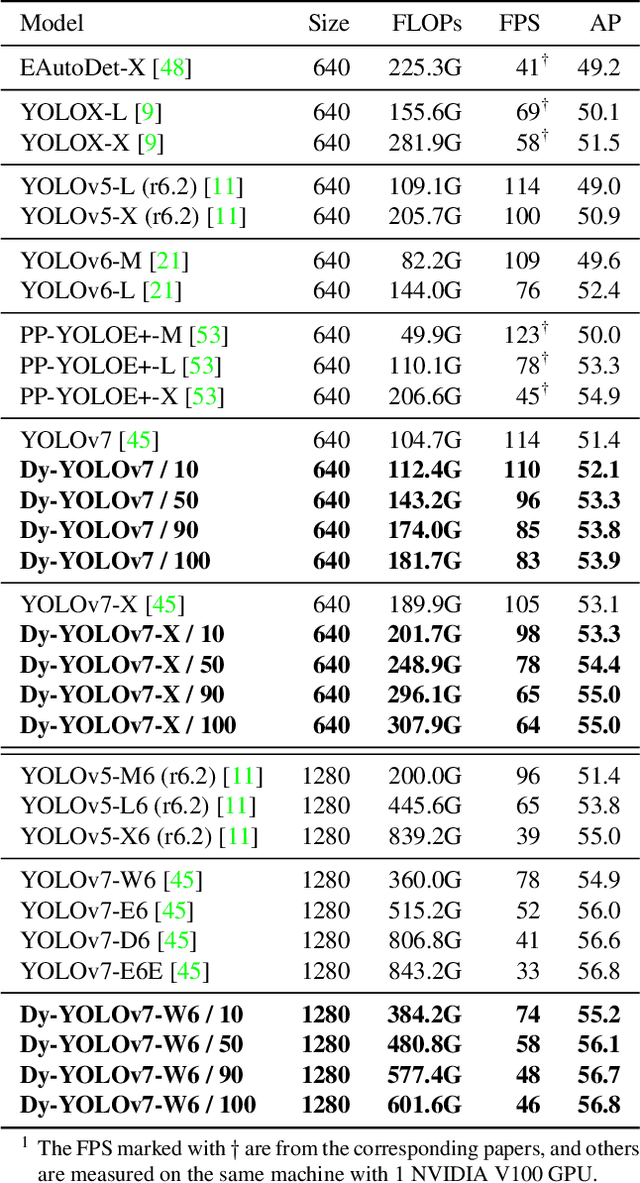


Dynamic neural network is an emerging research topic in deep learning. With adaptive inference, dynamic models can achieve remarkable accuracy and computational efficiency. However, it is challenging to design a powerful dynamic detector, because of no suitable dynamic architecture and exiting criterion for object detection. To tackle these difficulties, we propose a dynamic framework for object detection, named DynamicDet. Firstly, we carefully design a dynamic architecture based on the nature of the object detection task. Then, we propose an adaptive router to analyze the multi-scale information and to decide the inference route automatically. We also present a novel optimization strategy with an exiting criterion based on the detection losses for our dynamic detectors. Last, we present a variable-speed inference strategy, which helps to realize a wide range of accuracy-speed trade-offs with only one dynamic detector. Extensive experiments conducted on the COCO benchmark demonstrate that the proposed DynamicDet achieves new state-of-the-art accuracy-speed trade-offs. For instance, with comparable accuracy, the inference speed of our dynamic detector Dy-YOLOv7-W6 surpasses YOLOv7-E6 by 12%, YOLOv7-D6 by 17%, and YOLOv7-E6E by 39%. The code is available at https://github.com/VDIGPKU/DynamicDet.
A Simple and Generic Framework for Feature Distillation via Channel-wise Transformation
Mar 24, 2023
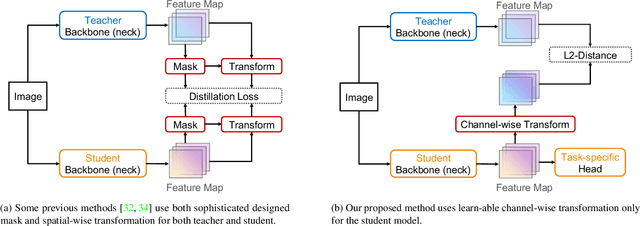

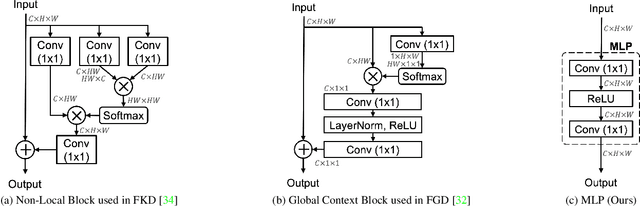
Knowledge distillation is a popular technique for transferring the knowledge from a large teacher model to a smaller student model by mimicking. However, distillation by directly aligning the feature maps between teacher and student may enforce overly strict constraints on the student thus degrade the performance of the student model. To alleviate the above feature misalignment issue, existing works mainly focus on spatially aligning the feature maps of the teacher and the student, with pixel-wise transformation. In this paper, we newly find that aligning the feature maps between teacher and student along the channel-wise dimension is also effective for addressing the feature misalignment issue. Specifically, we propose a learnable nonlinear channel-wise transformation to align the features of the student and the teacher model. Based on it, we further propose a simple and generic framework for feature distillation, with only one hyper-parameter to balance the distillation loss and the task specific loss. Extensive experimental results show that our method achieves significant performance improvements in various computer vision tasks including image classification (+3.28% top-1 accuracy for MobileNetV1 on ImageNet-1K), object detection (+3.9% bbox mAP for ResNet50-based Faster-RCNN on MS COCO), instance segmentation (+2.8% Mask mAP for ResNet50-based Mask-RCNN), and semantic segmentation (+4.66% mIoU for ResNet18-based PSPNet in semantic segmentation on Cityscapes), which demonstrates the effectiveness and the versatility of the proposed method. The code will be made publicly available.
NAFSSR: Stereo Image Super-Resolution Using NAFNet
Apr 26, 2022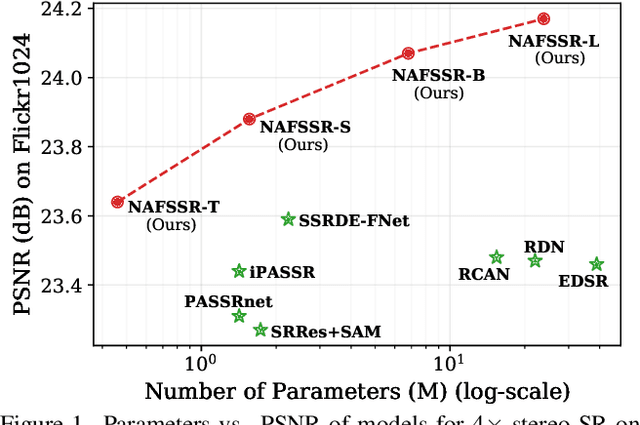
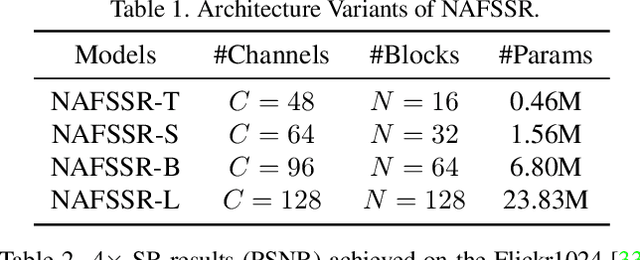
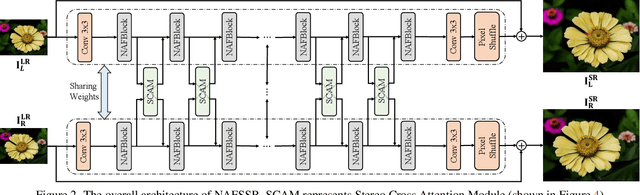
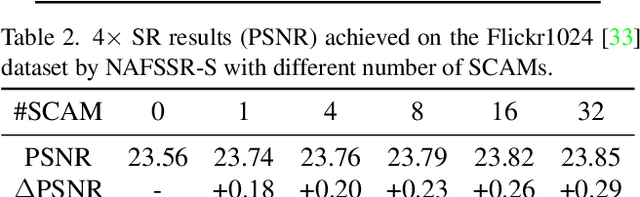
Stereo image super-resolution aims at enhancing the quality of super-resolution results by utilizing the complementary information provided by binocular systems. To obtain reasonable performance, most methods focus on finely designing modules, loss functions, and etc. to exploit information from another viewpoint. This has the side effect of increasing system complexity, making it difficult for researchers to evaluate new ideas and compare methods. This paper inherits a strong and simple image restoration model, NAFNet, for single-view feature extraction and extends it by adding cross attention modules to fuse features between views to adapt to binocular scenarios. The proposed baseline for stereo image super-resolution is noted as NAFSSR. Furthermore, training/testing strategies are proposed to fully exploit the performance of NAFSSR. Extensive experiments demonstrate the effectiveness of our method. In particular, NAFSSR outperforms the state-of-the-art methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets. With NAFSSR, we won 1st place in the NTIRE 2022 Stereo Image Super-resolution Challenge. Codes and models will be released at https://github.com/megvii-research/NAFNet.
Simple Baselines for Image Restoration
Apr 10, 2022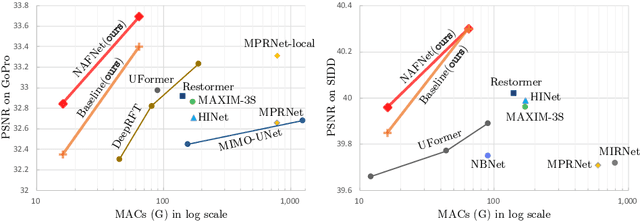

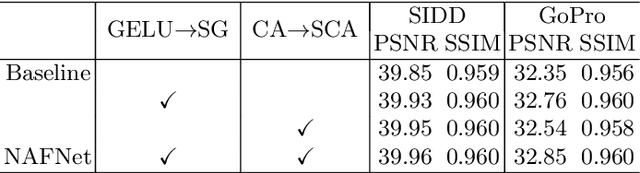
Although there have been significant advances in the field of image restoration recently, the system complexity of the state-of-the-art (SOTA) methods is increasing as well, which may hinder the convenient analysis and comparison of methods. In this paper, we propose a simple baseline that exceeds the SOTA methods and is computationally efficient. To further simplify the baseline, we reveal that the nonlinear activation functions, e.g. Sigmoid, ReLU, GELU, Softmax, etc. are not necessary: they could be replaced by multiplication or removed. Thus, we derive a Nonlinear Activation Free Network, namely NAFNet, from the baseline. SOTA results are achieved on various challenging benchmarks, e.g. 33.69 dB PSNR on GoPro (for image deblurring), exceeding the previous SOTA 0.38 dB with only 8.4% of its computational costs; 40.30 dB PSNR on SIDD (for image denoising), exceeding the previous SOTA 0.28 dB with less than half of its computational costs. The code and the pretrained models will be released at https://github.com/megvii-research/NAFNet.
IterVM: Iterative Vision Modeling Module for Scene Text Recognition
Apr 06, 2022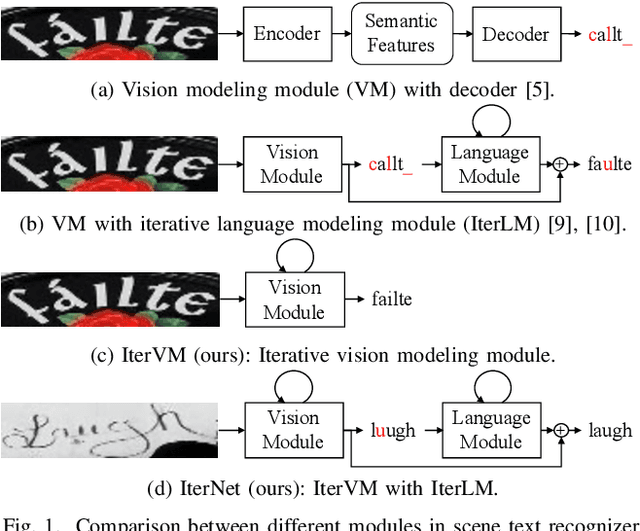
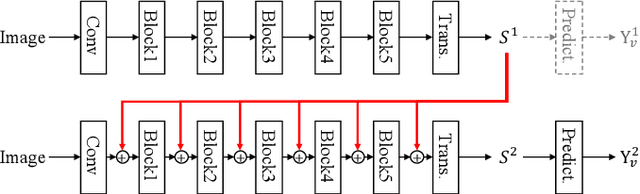
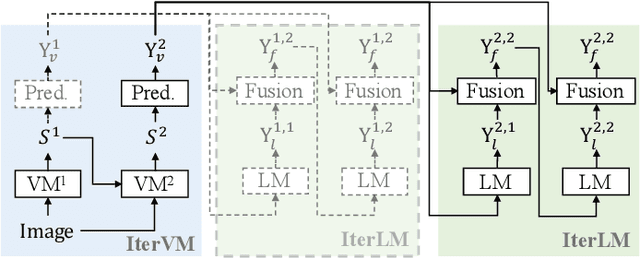

Scene text recognition (STR) is a challenging problem due to the imperfect imagery conditions in natural images. State-of-the-art methods utilize both visual cues and linguistic knowledge to tackle this challenging problem. Specifically, they propose iterative language modeling module (IterLM) to repeatedly refine the output sequence from the visual modeling module (VM). Though achieving promising results, the vision modeling module has become the performance bottleneck of these methods. In this paper, we newly propose iterative vision modeling module (IterVM) to further improve the STR accuracy. Specifically, the first VM directly extracts multi-level features from the input image, and the following VMs re-extract multi-level features from the input image and fuse them with the high-level (i.e., the most semantic one) feature extracted by the previous VM. By combining the proposed IterVM with iterative language modeling module, we further propose a powerful scene text recognizer called IterNet. Extensive experiments demonstrate that the proposed IterVM can significantly improve the scene text recognition accuracy, especially on low-quality scene text images. Moreover, the proposed scene text recognizer IterNet achieves new state-of-the-art results on several public benchmarks. Codes will be available at https://github.com/VDIGPKU/IterNet.
Training Protocol Matters: Towards Accurate Scene Text Recognition via Training Protocol Searching
Mar 17, 2022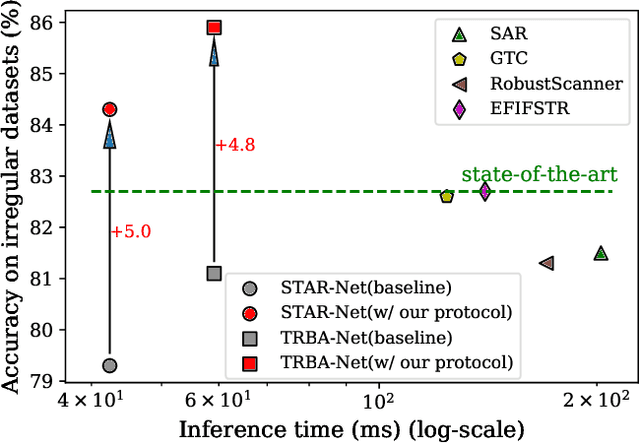
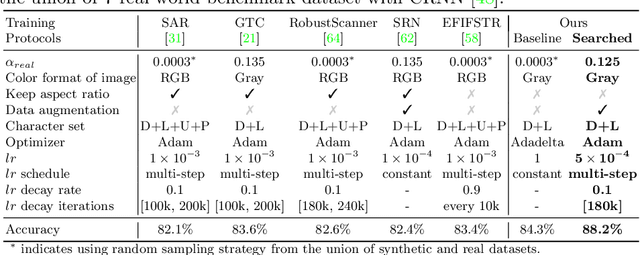

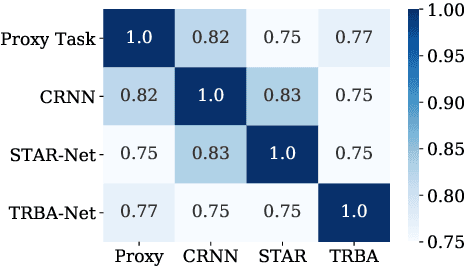
The development of scene text recognition (STR) in the era of deep learning has been mainly focused on novel architectures of STR models. However, training protocol (i.e., settings of the hyper-parameters involved in the training of STR models), which plays an equally important role in successfully training a good STR model, is under-explored for scene text recognition. In this work, we attempt to improve the accuracy of existing STR models by searching for optimal training protocol. Specifically, we develop a training protocol search algorithm, based on a newly designed search space and an efficient search algorithm using evolutionary optimization and proxy tasks. Experimental results show that our searched training protocol can improve the recognition accuracy of mainstream STR models by 2.7%~3.9%. In particular, with the searched training protocol, TRBA-Net achieves 2.1% higher accuracy than the state-of-the-art STR model (i.e., EFIFSTR), while the inference speed is 2.3x and 3.7x faster on CPU and GPU respectively. Extensive experiments are conducted to demonstrate the effectiveness of the proposed method and the generalization ability of the training protocol found by our search method. Code is available at https://github.com/VDIGPKU/STR_TPSearch.
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 20, 2021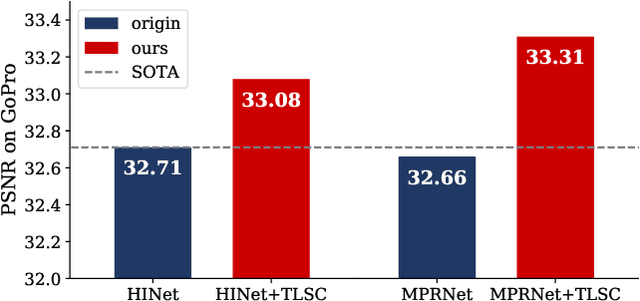
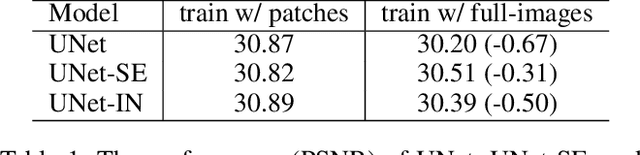
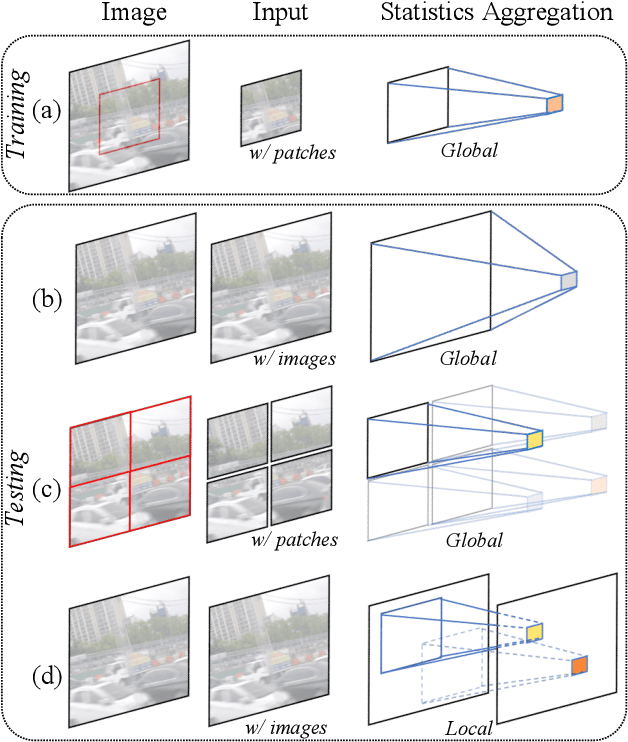
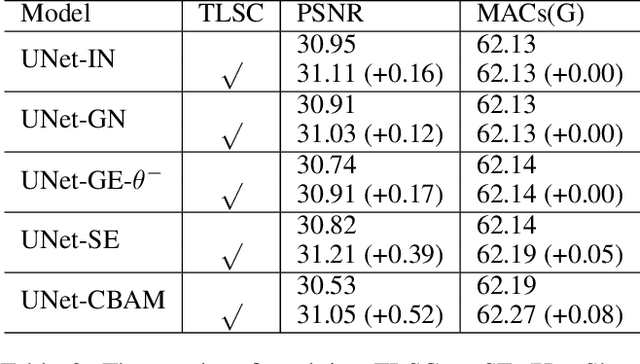
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
CBNetV2: A Composite Backbone Network Architecture for Object Detection
Jul 29, 2021
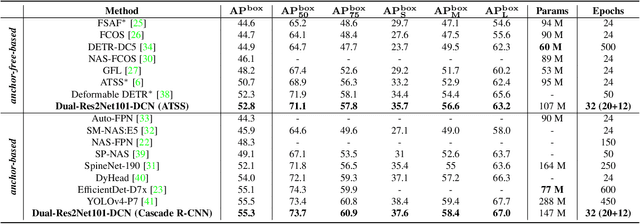
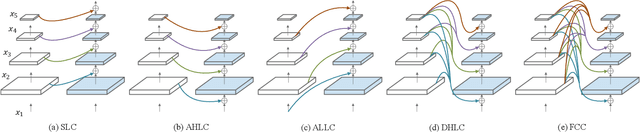
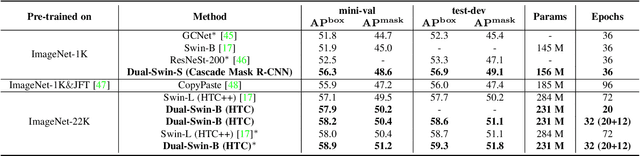
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. We also propose a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNetV2 introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our Dual-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which is significantly better than the state-of-the-art result (57.7% box AP and 50.2% mask AP) achieved by Swin-L, while the training schedule is reduced by 6$\times$. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data. Code is available at https://github.com/VDIGPKU/CBNetV2.