 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Multi-View Active Fine-Grained Recognition
Jun 02, 2022
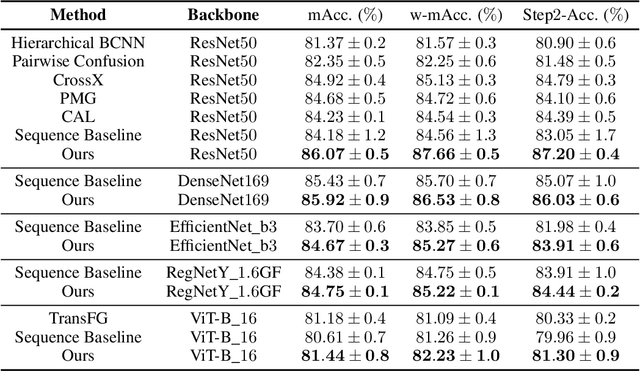
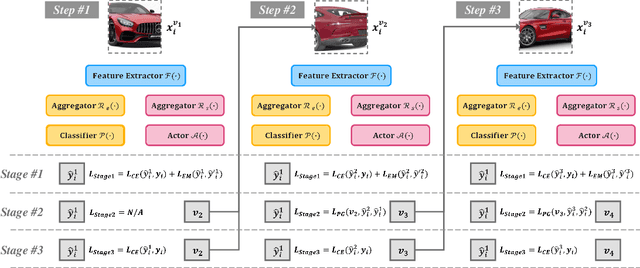
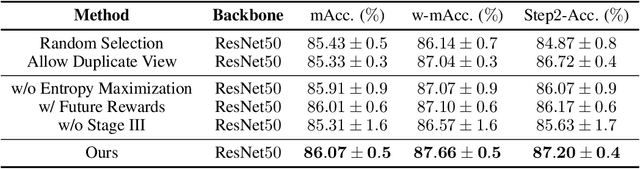
As fine-grained visual classification (FGVC) being developed for decades, great works related have exposed a key direction -- finding discriminative local regions and revealing subtle differences. However, unlike identifying visual contents within static images, for recognizing objects in the real physical world, discriminative information is not only present within seen local regions but also hides in other unseen perspectives. In other words, in addition to focusing on the distinguishable part from the whole, for efficient and accurate recognition, it is required to infer the key perspective with a few glances, e.g., people may recognize a "Benz AMG GT" with a glance of its front and then know that taking a look at its exhaust pipe can help to tell which year's model it is. In this paper, back to reality, we put forward the problem of active fine-grained recognition (AFGR) and complete this study in three steps: (i) a hierarchical, multi-view, fine-grained vehicle dataset is collected as the testbed, (ii) a simple experiment is designed to verify that different perspectives contribute differently for FGVC and different categories own different discriminative perspective, (iii) a policy-gradient-based framework is adopted to achieve efficient recognition with active view selection. Comprehensive experiments demonstrate that the proposed method delivers a better performance-efficient trade-off than previous FGVC methods and advanced neural networks.
NAFSSR: Stereo Image Super-Resolution Using NAFNet
Apr 26, 2022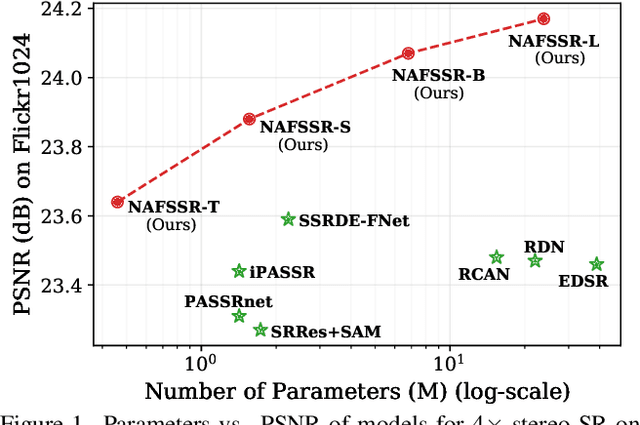
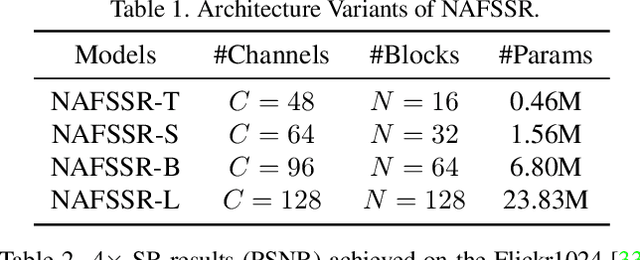
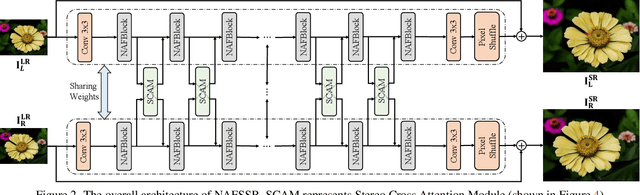
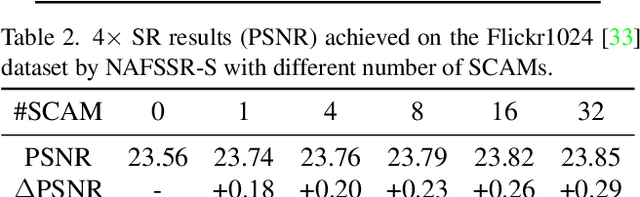
Stereo image super-resolution aims at enhancing the quality of super-resolution results by utilizing the complementary information provided by binocular systems. To obtain reasonable performance, most methods focus on finely designing modules, loss functions, and etc. to exploit information from another viewpoint. This has the side effect of increasing system complexity, making it difficult for researchers to evaluate new ideas and compare methods. This paper inherits a strong and simple image restoration model, NAFNet, for single-view feature extraction and extends it by adding cross attention modules to fuse features between views to adapt to binocular scenarios. The proposed baseline for stereo image super-resolution is noted as NAFSSR. Furthermore, training/testing strategies are proposed to fully exploit the performance of NAFSSR. Extensive experiments demonstrate the effectiveness of our method. In particular, NAFSSR outperforms the state-of-the-art methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets. With NAFSSR, we won 1st place in the NTIRE 2022 Stereo Image Super-resolution Challenge. Codes and models will be released at https://github.com/megvii-research/NAFNet.