 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
Nov 11, 2022



Feature reuse has been a key technique in light-weight convolutional neural networks (CNNs) design. Current methods usually utilize a concatenation operator to keep large channel numbers cheaply (thus large network capacity) by reusing feature maps from other layers. Although concatenation is parameters- and FLOPs-free, its computational cost on hardware devices is non-negligible. To address this, this paper provides a new perspective to realize feature reuse via structural re-parameterization technique. A novel hardware-efficient RepGhost module is proposed for implicit feature reuse via re-parameterization, instead of using concatenation operator. Based on the RepGhost module, we develop our efficient RepGhost bottleneck and RepGhostNet. Experiments on ImageNet and COCO benchmarks demonstrate that the proposed RepGhostNet is much more effective and efficient than GhostNet and MobileNetV3 on mobile devices. Specially, our RepGhostNet surpasses GhostNet 0.5x by 2.5% Top-1 accuracy on ImageNet dataset with less parameters and comparable latency on an ARM-based mobile phone.
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 20, 2021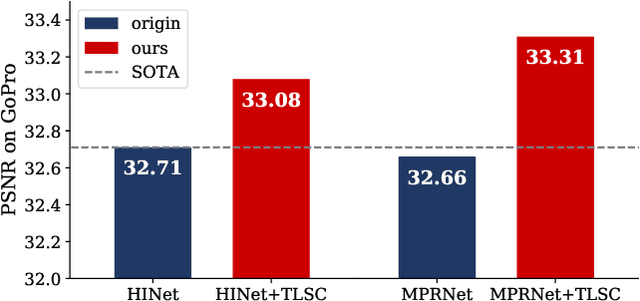
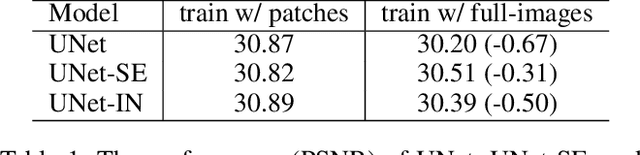
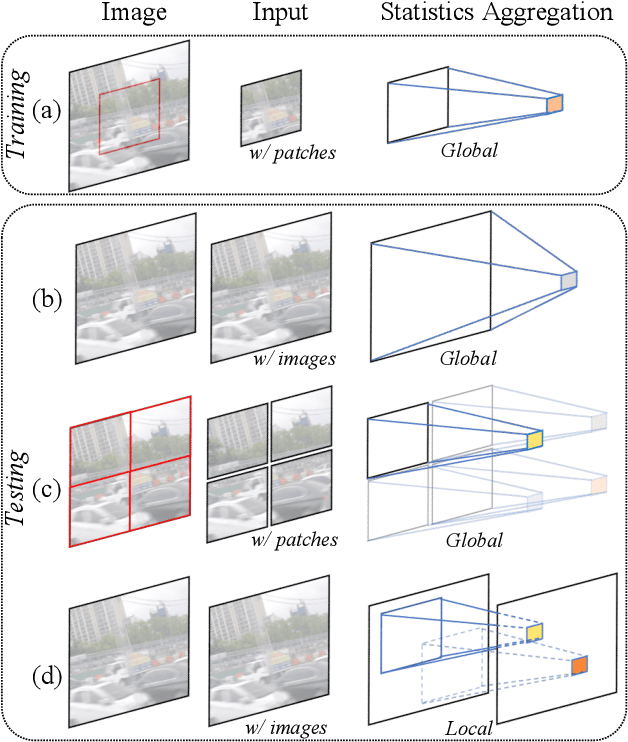
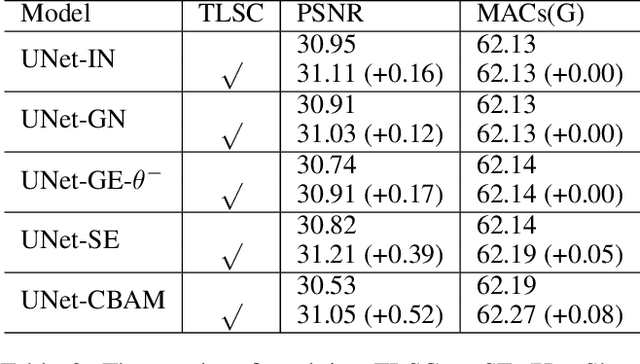
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
HINet: Half Instance Normalization Network for Image Restoration
May 13, 2021
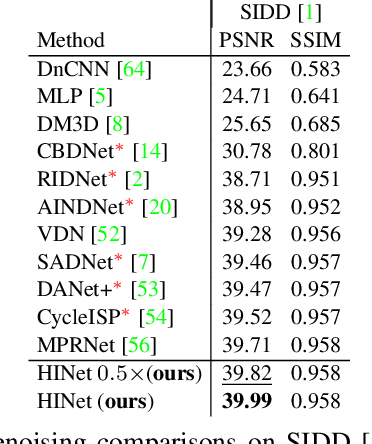
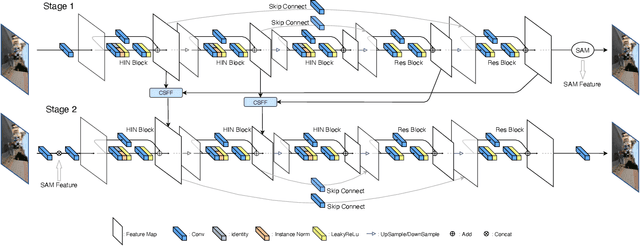
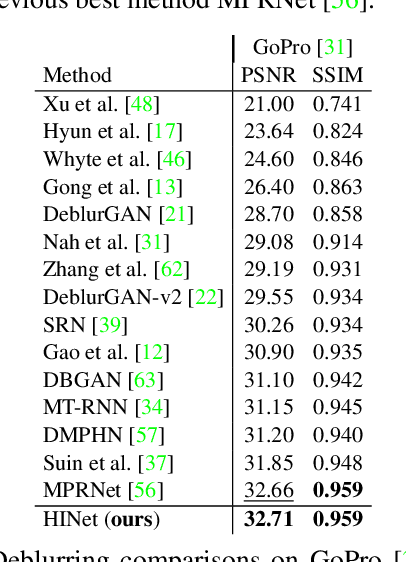
In this paper, we explore the role of Instance Normalization in low-level vision tasks. Specifically, we present a novel block: Half Instance Normalization Block (HIN Block), to boost the performance of image restoration networks. Based on HIN Block, we design a simple and powerful multi-stage network named HINet, which consists of two subnetworks. With the help of HIN Block, HINet surpasses the state-of-the-art (SOTA) on various image restoration tasks. For image denoising, we exceed it 0.11dB and 0.28 dB in PSNR on SIDD dataset, with only 7.5% and 30% of its multiplier-accumulator operations (MACs), 6.8 times and 2.9 times speedup respectively. For image deblurring, we get comparable performance with 22.5% of its MACs and 3.3 times speedup on REDS and GoPro datasets. For image deraining, we exceed it by 0.3 dB in PSNR on the average result of multiple datasets with 1.4 times speedup. With HINet, we won 1st place on the NTIRE 2021 Image Deblurring Challenge - Track2. JPEG Artifacts, with a PSNR of 29.70. The code is available at https://github.com/megvii-model/HINet.
Learning Effective RGB-D Representations for Scene Recognition
Sep 17, 2018
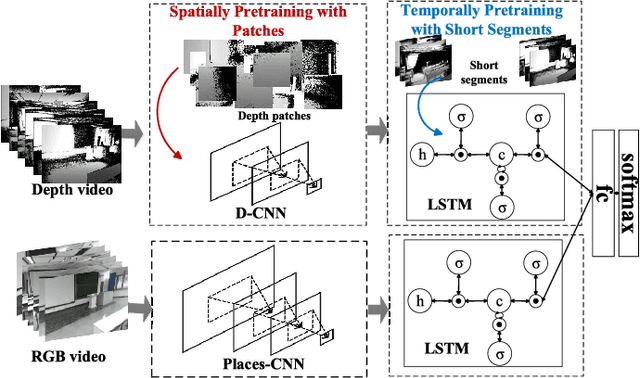
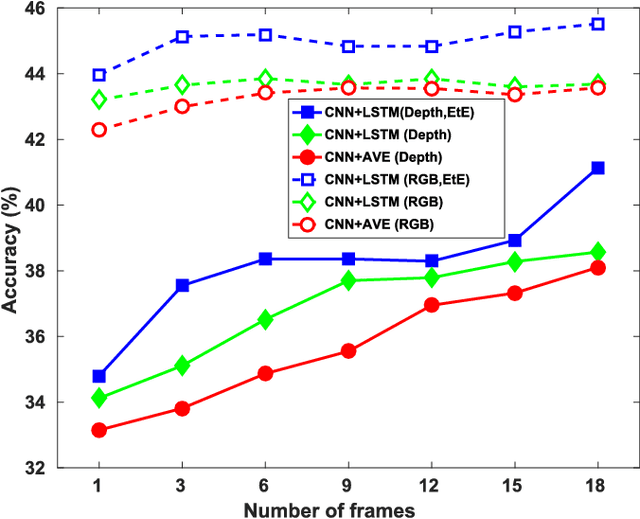
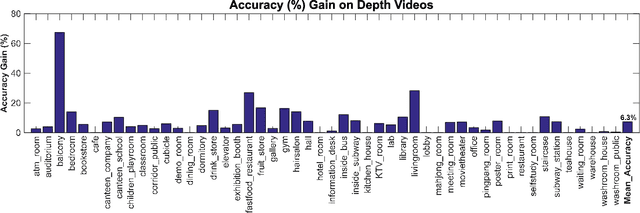
Deep convolutional networks (CNN) can achieve impressive results on RGB scene recognition thanks to large datasets such as Places. In contrast, RGB-D scene recognition is still underdeveloped in comparison, due to two limitations of RGB-D data we address in this paper. The first limitation is the lack of depth data for training deep learning models. Rather than fine tuning or transferring RGB-specific features, we address this limitation by proposing an architecture and a two-step training approach that directly learns effective depth-specific features using weak supervision via patches. The resulting RGB-D model also benefits from more complementary multimodal features. Another limitation is the short range of depth sensors (typically 0.5m to 5.5m), resulting in depth images not capturing distant objects in the scenes that RGB images can. We show that this limitation can be addressed by using RGB-D videos, where more comprehensive depth information is accumulated as the camera travels across the scene. Focusing on this scenario, we introduce the ISIA RGB-D video dataset to evaluate RGB-D scene recognition with videos. Our video recognition architecture combines convolutional and recurrent neural networks (RNNs) that are trained in three steps with increasingly complex data to learn effective features (i.e. patches, frames and sequences). Our approach obtains state-of-the-art performances on RGB-D image (NYUD2 and SUN RGB-D) and video (ISIA RGB-D) scene recognition.
* Accepted at IEEE Transactions on Image Processing