 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Effective RGB-D Representations for Scene Recognition
Paper and Code
Sep 17, 2018
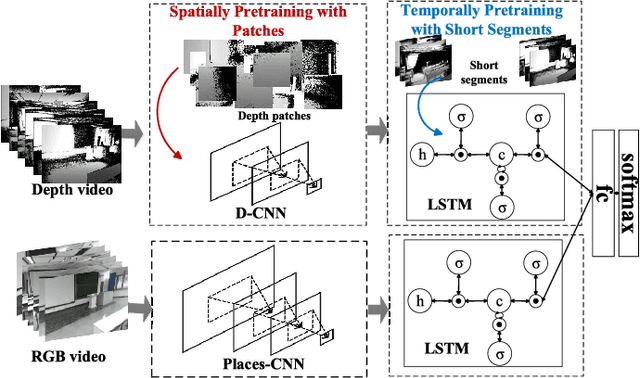
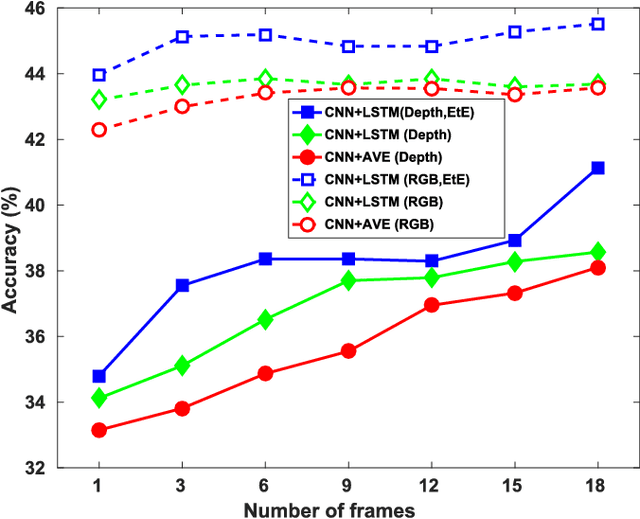
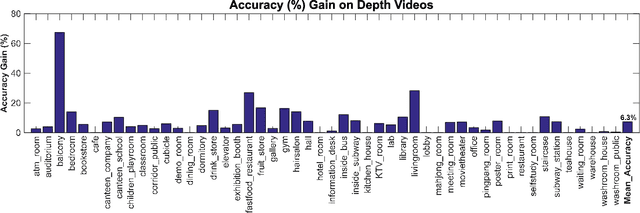
Deep convolutional networks (CNN) can achieve impressive results on RGB scene recognition thanks to large datasets such as Places. In contrast, RGB-D scene recognition is still underdeveloped in comparison, due to two limitations of RGB-D data we address in this paper. The first limitation is the lack of depth data for training deep learning models. Rather than fine tuning or transferring RGB-specific features, we address this limitation by proposing an architecture and a two-step training approach that directly learns effective depth-specific features using weak supervision via patches. The resulting RGB-D model also benefits from more complementary multimodal features. Another limitation is the short range of depth sensors (typically 0.5m to 5.5m), resulting in depth images not capturing distant objects in the scenes that RGB images can. We show that this limitation can be addressed by using RGB-D videos, where more comprehensive depth information is accumulated as the camera travels across the scene. Focusing on this scenario, we introduce the ISIA RGB-D video dataset to evaluate RGB-D scene recognition with videos. Our video recognition architecture combines convolutional and recurrent neural networks (RNNs) that are trained in three steps with increasingly complex data to learn effective features (i.e. patches, frames and sequences). Our approach obtains state-of-the-art performances on RGB-D image (NYUD2 and SUN RGB-D) and video (ISIA RGB-D) scene recognition.