 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does the Smoothness Approximation Method Facilitate Generalization for Federated Adversarial Learning?
Dec 11, 2024
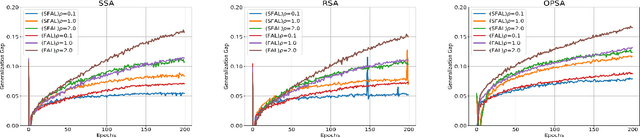
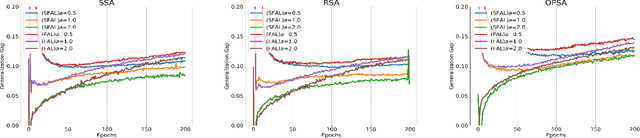
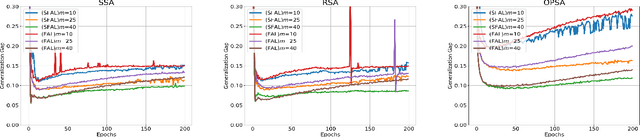
Federated Adversarial Learning (FAL) is a robust framework for resisting adversarial attacks on federated learning. Although some FAL studies have developed efficient algorithms, they primarily focus on convergence performance and overlook generalization. Generalization is crucial for evaluating algorithm performance on unseen data. However, generalization analysis is more challenging due to non-smooth adversarial loss functions. A common approach to addressing this issue is to leverage smoothness approximation. In this paper, we develop algorithm stability measures to evaluate the generalization performance of two popular FAL algorithms: \textit{Vanilla FAL (VFAL)} and {\it Slack FAL (SFAL)}, using three different smooth approximation methods: 1) \textit{Surrogate Smoothness Approximation (SSA)}, (2) \textit{Randomized Smoothness Approximation (RSA)}, and (3) \textit{Over-Parameterized Smoothness Approximation (OPSA)}. Based on our in-depth analysis, we answer the question of how to properly set the smoothness approximation method to mitigate generalization error in FAL. Moreover, we identify RSA as the most effective method for reducing generalization error. In highly data-heterogeneous scenarios, we also recommend employing SFAL to mitigate the deterioration of generalization performance caused by heterogeneity. Based on our theoretical results, we provide insights to help develop more efficient FAL algorithms, such as designing new metrics and dynamic aggregation rules to mitigate heterogeneity.
Way to Specialist: Closing Loop Between Specialized LLM and Evolving Domain Knowledge Graph
Nov 28, 2024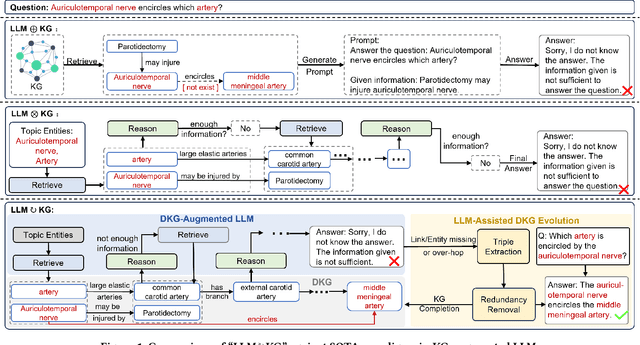
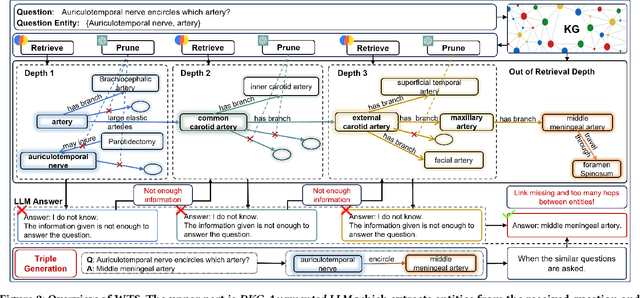
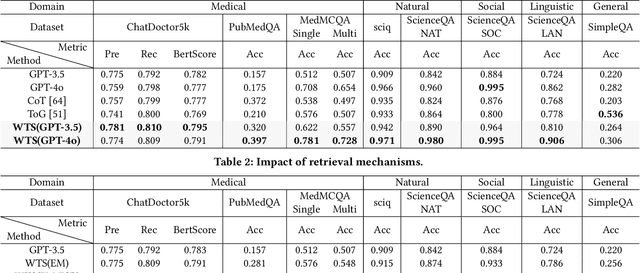
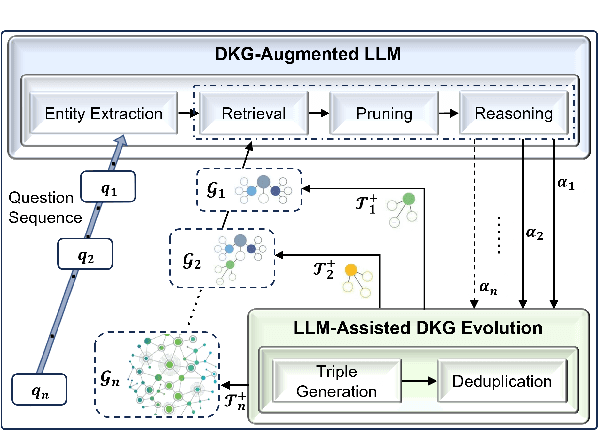
Large language models (LLMs) have demonstrated exceptional performance across a wide variety of domains. Nonetheless, generalist LLMs continue to fall short in reasoning tasks necessitating specialized knowledge. Prior investigations into specialized LLMs focused on domain-specific training, which entails substantial efforts in domain data acquisition and model parameter fine-tuning. To address these challenges, this paper proposes the Way-to-Specialist (WTS) framework, which synergizes retrieval-augmented generation with knowledge graphs (KGs) to enhance the specialized capability of LLMs in the absence of specialized training. In distinction to existing paradigms that merely utilize external knowledge from general KGs or static domain KGs to prompt LLM for enhanced domain-specific reasoning, WTS proposes an innovative "LLM$\circlearrowright$KG" paradigm, which achieves bidirectional enhancement between specialized LLM and domain knowledge graph (DKG). The proposed paradigm encompasses two closely coupled components: the DKG-Augmented LLM and the LLM-Assisted DKG Evolution. The former retrieves question-relevant domain knowledge from DKG and uses it to prompt LLM to enhance the reasoning capability for domain-specific tasks; the latter leverages LLM to generate new domain knowledge from processed tasks and use it to evolve DKG. WTS closes the loop between DKG-Augmented LLM and LLM-Assisted DKG Evolution, enabling continuous improvement in the domain specialization as it progressively answers and learns from domain-specific questions. We validate the performance of WTS on 6 datasets spanning 5 domains. The experimental results show that WTS surpasses the previous SOTA in 4 specialized domains and achieves a maximum performance improvement of 11.3%.
MARE: Multi-Aspect Rationale Extractor on Unsupervised Rationale Extraction
Oct 04, 2024
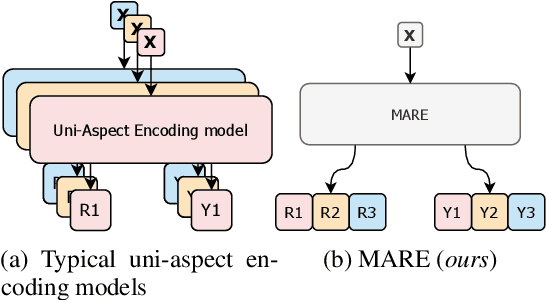
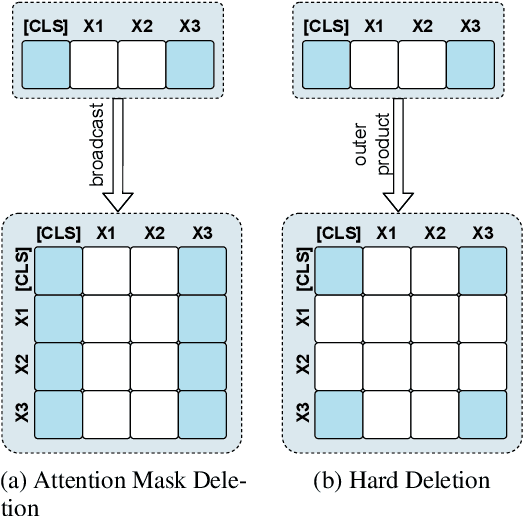
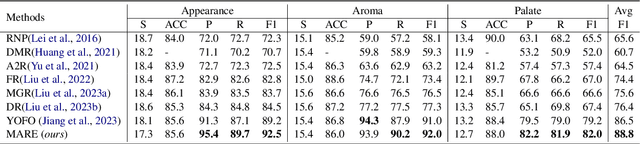
Unsupervised rationale extraction aims to extract text snippets to support model predictions without explicit rationale annotation. Researchers have made many efforts to solve this task. Previous works often encode each aspect independently, which may limit their ability to capture meaningful internal correlations between aspects. While there has been significant work on mitigating spurious correlations, our approach focuses on leveraging the beneficial internal correlations to improve multi-aspect rationale extraction. In this paper, we propose a Multi-Aspect Rationale Extractor (MARE) to explain and predict multiple aspects simultaneously. Concretely, we propose a Multi-Aspect Multi-Head Attention (MAMHA) mechanism based on hard deletion to encode multiple text chunks simultaneously. Furthermore, multiple special tokens are prepended in front of the text with each corresponding to one certain aspect. Finally, multi-task training is deployed to reduce the training overhead. Experimental results on two unsupervised rationale extraction benchmarks show that MARE achieves state-of-the-art performance. Ablation studies further demonstrate the effectiveness of our method. Our codes have been available at https://github.com/CSU-NLP-Group/MARE.
Stability and Generalization for Stochastic Recursive Momentum-based Algorithms for (Strongly-)Convex One to $K$-Level Stochastic Optimizations
Jul 07, 2024


STOchastic Recursive Momentum (STORM)-based algorithms have been widely developed to solve one to $K$-level ($K \geq 3$) stochastic optimization problems. Specifically, they use estimators to mitigate the biased gradient issue and achieve near-optimal convergence results. However, there is relatively little work on understanding their generalization performance, particularly evident during the transition from one to $K$-level optimization contexts. This paper provides a comprehensive generalization analysis of three representative STORM-based algorithms: STORM, COVER, and SVMR, for one, two, and $K$-level stochastic optimizations under both convex and strongly convex settings based on algorithmic stability. Firstly, we define stability for $K$-level optimizations and link it to generalization. Then, we detail the stability results for three prominent STORM-based algorithms. Finally, we derive their excess risk bounds by balancing stability results with optimization errors. Our theoretical results provide strong evidence to complete STORM-based algorithms: (1) Each estimator may decrease their stability due to variance with its estimation target. (2) Every additional level might escalate the generalization error, influenced by the stability and the variance between its cumulative stochastic gradient and the true gradient. (3) Increasing the batch size for the initial computation of estimators presents a favorable trade-off, enhancing the generalization performance.
Unsupervised Collaborative Metric Learning with Mixed-Scale Groups for General Object Retrieval
Mar 16, 2024



The task of searching for visual objects in a large image dataset is difficult because it requires efficient matching and accurate localization of objects that can vary in size. Although the segment anything model (SAM) offers a potential solution for extracting object spatial context, learning embeddings for local objects remains a challenging problem. This paper presents a novel unsupervised deep metric learning approach, termed unsupervised collaborative metric learning with mixed-scale groups (MS-UGCML), devised to learn embeddings for objects of varying scales. Following this, a benchmark of challenges is assembled by utilizing COCO 2017 and VOC 2007 datasets to facilitate the training and evaluation of general object retrieval models. Finally, we conduct comprehensive ablation studies and discuss the complexities faced within the domain of general object retrieval. Our object retrieval evaluations span a range of datasets, including BelgaLogos, Visual Genome, LVIS, in addition to a challenging evaluation set that we have individually assembled for open-vocabulary evaluation. These comprehensive evaluations effectively highlight the robustness of our unsupervised MS-UGCML approach, with an object level and image level mAPs improvement of up to 6.69% and 10.03%, respectively. The code is publicly available at https://github.com/dengyuhai/MS-UGCML.
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
Mar 15, 2024



Multi-agent perception (MAP) allows autonomous systems to understand complex environments by interpreting data from multiple sources. This paper investigates intermediate collaboration for MAP with a specific focus on exploring "good" properties of collaborative view (i.e., post-collaboration feature) and its underlying relationship to individual views (i.e., pre-collaboration features), which were treated as an opaque procedure by most existing works. We propose a novel framework named CMiMC (Contrastive Mutual Information Maximization for Collaborative Perception) for intermediate collaboration. The core philosophy of CMiMC is to preserve discriminative information of individual views in the collaborative view by maximizing mutual information between pre- and post-collaboration features while enhancing the efficacy of collaborative views by minimizing the loss function of downstream tasks. In particular, we define multi-view mutual information (MVMI) for intermediate collaboration that evaluates correlations between collaborative views and individual views on both global and local scales. We establish CMiMNet based on multi-view contrastive learning to realize estimation and maximization of MVMI, which assists the training of a collaboration encoder for voxel-level feature fusion. We evaluate CMiMC on V2X-Sim 1.0, and it improves the SOTA average precision by 3.08% and 4.44% at 0.5 and 0.7 IoU (Intersection-over-Union) thresholds, respectively. In addition, CMiMC can reduce communication volume to 1/32 while achieving performance comparable to SOTA. Code and Appendix are released at https://github.com/77SWF/CMiMC.
Parrot-Trained Adversarial Examples: Pushing the Practicality of Black-Box Audio Attacks against Speaker Recognition Models
Nov 17, 2023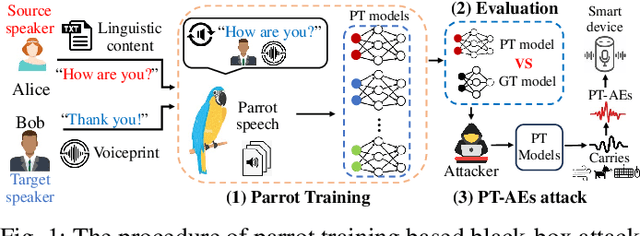
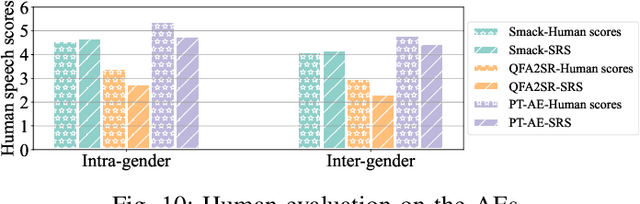
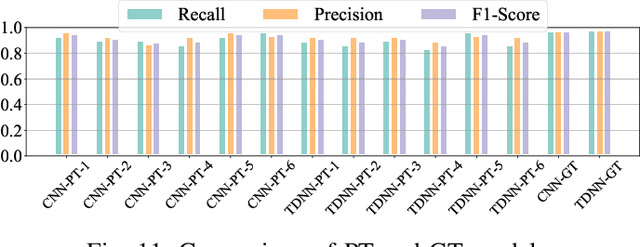
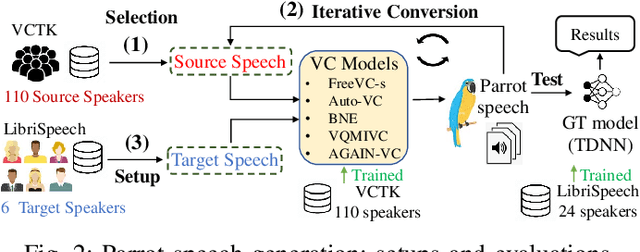
Audio adversarial examples (AEs) have posed significant security challenges to real-world speaker recognition systems. Most black-box attacks still require certain information from the speaker recognition model to be effective (e.g., keeping probing and requiring the knowledge of similarity scores). This work aims to push the practicality of the black-box attacks by minimizing the attacker's knowledge about a target speaker recognition model. Although it is not feasible for an attacker to succeed with completely zero knowledge, we assume that the attacker only knows a short (or a few seconds) speech sample of a target speaker. Without any probing to gain further knowledge about the target model, we propose a new mechanism, called parrot training, to generate AEs against the target model. Motivated by recent advancements in voice conversion (VC), we propose to use the one short sentence knowledge to generate more synthetic speech samples that sound like the target speaker, called parrot speech. Then, we use these parrot speech samples to train a parrot-trained(PT) surrogate model for the attacker. Under a joint transferability and perception framework, we investigate different ways to generate AEs on the PT model (called PT-AEs) to ensure the PT-AEs can be generated with high transferability to a black-box target model with good human perceptual quality. Real-world experiments show that the resultant PT-AEs achieve the attack success rates of 45.8% - 80.8% against the open-source models in the digital-line scenario and 47.9% - 58.3% against smart devices, including Apple HomePod (Siri), Amazon Echo, and Google Home, in the over-the-air scenario.
You Only Forward Once: Prediction and Rationalization in A Single Forward Pass
Nov 04, 2023



Unsupervised rationale extraction aims to extract concise and contiguous text snippets to support model predictions without any annotated rationale. Previous studies have used a two-phase framework known as the Rationalizing Neural Prediction (RNP) framework, which follows a generate-then-predict paradigm. They assumed that the extracted explanation, called rationale, should be sufficient to predict the golden label. However, the assumption above deviates from the original definition and is too strict to perform well. Furthermore, these two-phase models suffer from the interlocking problem and spurious correlations. To solve the above problems, we propose a novel single-phase framework called You Only Forward Once (YOFO), derived from a relaxed version of rationale where rationales aim to support model predictions rather than make predictions. In our framework, A pre-trained language model like BERT is deployed to simultaneously perform prediction and rationalization with less impact from interlocking or spurious correlations. Directly choosing the important tokens in an unsupervised manner is intractable. Instead of directly choosing the important tokens, YOFO gradually removes unimportant tokens during forward propagation. Through experiments on the BeerAdvocate and Hotel Review datasets, we demonstrate that our model is able to extract rationales and make predictions more accurately compared to RNP-based models. We observe an improvement of up to 18.4\% in token-level F1 compared to previous state-of-the-art methods. We also conducted analyses and experiments to explore the extracted rationales and token decay strategies. The results show that YOFO can extract precise and important rationales while removing unimportant tokens in the middle part of the model.
Breaking the Complexity Barrier in Compositional Minimax Optimization
Aug 18, 2023



Compositional minimax optimization is a pivotal yet under-explored challenge across machine learning, including distributionally robust training and policy evaluation for reinforcement learning. Current techniques exhibit suboptimal complexity or rely heavily on large batch sizes. This paper proposes Nested STOchastic Recursive Momentum (NSTORM), attaining the optimal sample complexity of $O(\kappa^3/\epsilon^3)$ for finding an $\epsilon$-accurate solution. However, NSTORM requires low learning rates, potentially limiting applicability. Thus we introduce ADAptive NSTORM (ADA-NSTORM) with adaptive learning rates, proving it achieves the same sample complexity while experiments demonstrate greater effectiveness. Our methods match lower bounds for minimax optimization without large batch requirements, validated through extensive experiments. This work significantly advances compositional minimax optimization, a crucial capability for distributional robustness and policy evaluation
Inter-Instance Similarity Modeling for Contrastive Learning
Jun 29, 2023



The existing contrastive learning methods widely adopt one-hot instance discrimination as pretext task for self-supervised learning, which inevitably neglects rich inter-instance similarities among natural images, then leading to potential representation degeneration. In this paper, we propose a novel image mix method, PatchMix, for contrastive learning in Vision Transformer (ViT), to model inter-instance similarities among images. Following the nature of ViT, we randomly mix multiple images from mini-batch in patch level to construct mixed image patch sequences for ViT. Compared to the existing sample mix methods, our PatchMix can flexibly and efficiently mix more than two images and simulate more complicated similarity relations among natural images. In this manner, our contrastive framework can significantly reduce the gap between contrastive objective and ground truth in reality. Experimental results demonstrate that our proposed method significantly outperforms the previous state-of-the-art on both ImageNet-1K and CIFAR datasets, e.g., 3.0% linear accuracy improvement on ImageNet-1K and 8.7% kNN accuracy improvement on CIFAR100. Moreover, our method achieves the leading transfer performance on downstream tasks, object detection and instance segmentation on COCO dataset. The code is available at https://github.com/visresearch/patchmix