 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
DDO: Dual-Decision Optimization via Multi-Agent Collaboration for LLM-Based Medical Consultation
May 24, 2025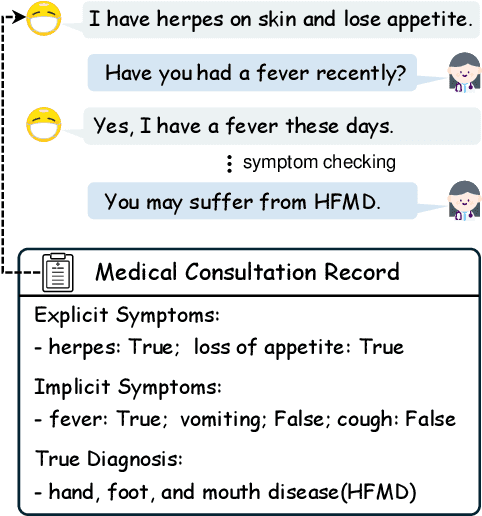
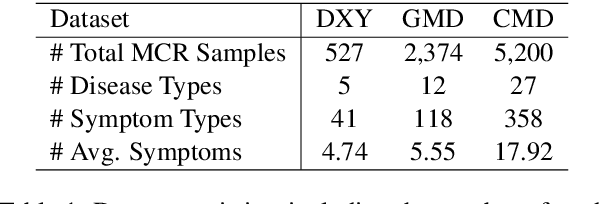
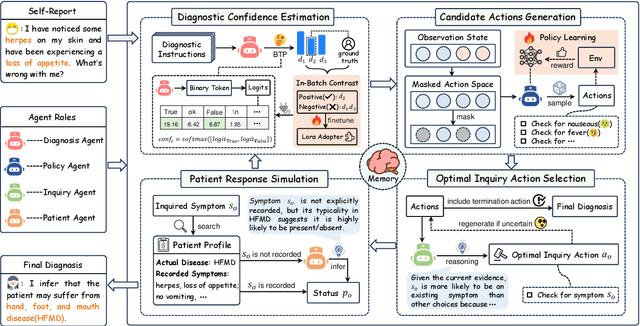
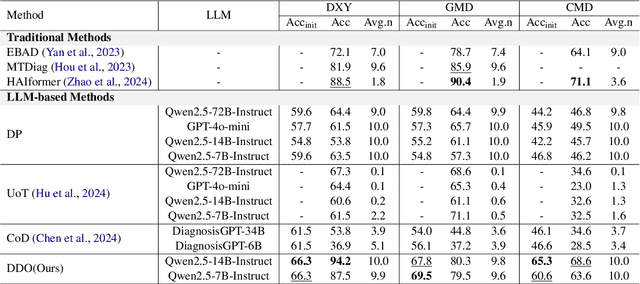
Large Language Models (LLMs) demonstrate strong generalization and reasoning abilities, making them well-suited for complex decision-making tasks such as medical consultation (MC). However, existing LLM-based methods often fail to capture the dual nature of MC, which entails two distinct sub-tasks: symptom inquiry, a sequential decision-making process, and disease diagnosis, a classification problem. This mismatch often results in ineffective symptom inquiry and unreliable disease diagnosis. To address this, we propose \textbf{DDO}, a novel LLM-based framework that performs \textbf{D}ual-\textbf{D}ecision \textbf{O}ptimization by decoupling and independently optimizing the the two sub-tasks through a collaborative multi-agent workflow. Experiments on three real-world MC datasets show that DDO consistently outperforms existing LLM-based approaches and achieves competitive performance with state-of-the-art generation-based methods, demonstrating its effectiveness in the MC task.
CheXLearner: Text-Guided Fine-Grained Representation Learning for Progression Detection
May 11, 2025



Temporal medical image analysis is essential for clinical decision-making, yet existing methods either align images and text at a coarse level - causing potential semantic mismatches - or depend solely on visual information, lacking medical semantic integration. We present CheXLearner, the first end-to-end framework that unifies anatomical region detection, Riemannian manifold-based structure alignment, and fine-grained regional semantic guidance. Our proposed Med-Manifold Alignment Module (Med-MAM) leverages hyperbolic geometry to robustly align anatomical structures and capture pathologically meaningful discrepancies across temporal chest X-rays. By introducing regional progression descriptions as supervision, CheXLearner achieves enhanced cross-modal representation learning and supports dynamic low-level feature optimization. Experiments show that CheXLearner achieves 81.12% (+17.2%) average accuracy and 80.32% (+11.05%) F1-score on anatomical region progression detection - substantially outperforming state-of-the-art baselines, especially in structurally complex regions. Additionally, our model attains a 91.52% average AUC score in downstream disease classification, validating its superior feature representation.
FIND: Fine-grained Information Density Guided Adaptive Retrieval-Augmented Generation for Disease Diagnosis
Feb 20, 2025Retrieval-Augmented Large Language Models (LLMs), which integrate external knowledge into LLMs, have shown remarkable performance in various medical domains, including clinical diagnosis. However, existing RAG methods struggle to effectively assess task difficulty to make retrieval decisions, thereby failing to meet the clinical requirements for balancing efficiency and accuracy. So in this paper, we propose FIND (\textbf{F}ine-grained \textbf{In}formation \textbf{D}ensity Guided Adaptive RAG), a novel framework that improves the reliability of RAG in disease diagnosis scenarios. FIND incorporates a fine-grained adaptive control module to determine whether retrieval is necessary based on the information density of the input. By optimizing the retrieval process and implementing a knowledge filtering module, FIND ensures that the retrieval is better suited to clinical scenarios. Experiments on three Chinese electronic medical record datasets demonstrate that FIND significantly outperforms various baseline methods, highlighting its effectiveness in clinical diagnosis tasks.
MARE: Multi-Aspect Rationale Extractor on Unsupervised Rationale Extraction
Oct 04, 2024
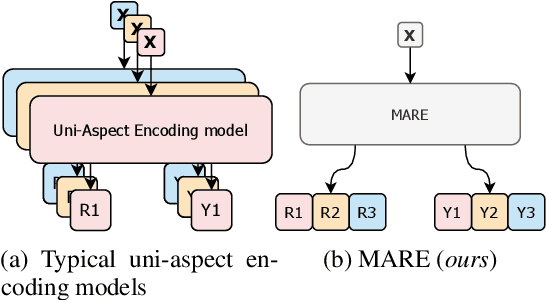
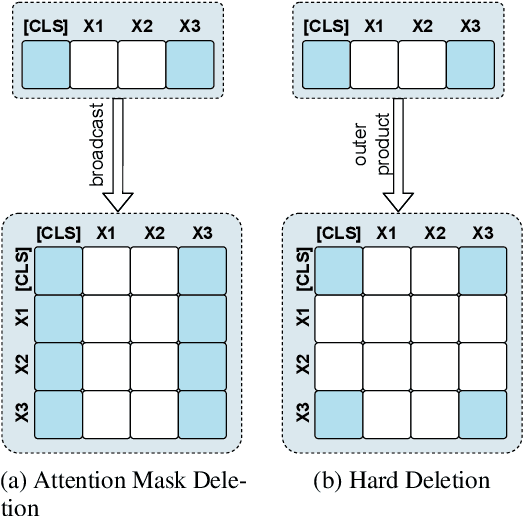
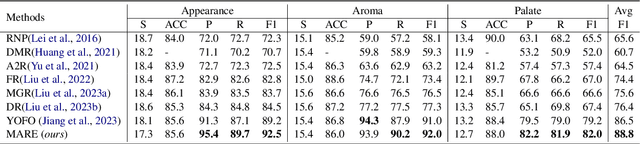
Unsupervised rationale extraction aims to extract text snippets to support model predictions without explicit rationale annotation. Researchers have made many efforts to solve this task. Previous works often encode each aspect independently, which may limit their ability to capture meaningful internal correlations between aspects. While there has been significant work on mitigating spurious correlations, our approach focuses on leveraging the beneficial internal correlations to improve multi-aspect rationale extraction. In this paper, we propose a Multi-Aspect Rationale Extractor (MARE) to explain and predict multiple aspects simultaneously. Concretely, we propose a Multi-Aspect Multi-Head Attention (MAMHA) mechanism based on hard deletion to encode multiple text chunks simultaneously. Furthermore, multiple special tokens are prepended in front of the text with each corresponding to one certain aspect. Finally, multi-task training is deployed to reduce the training overhead. Experimental results on two unsupervised rationale extraction benchmarks show that MARE achieves state-of-the-art performance. Ablation studies further demonstrate the effectiveness of our method. Our codes have been available at https://github.com/CSU-NLP-Group/MARE.
RUIE: Retrieval-based Unified Information Extraction using Large Language Model
Sep 18, 2024Unified information extraction (UIE) aims to complete all information extraction tasks using a single model or framework. While previous work has primarily focused on instruction-tuning large language models (LLMs) with constructed datasets, these methods require significant computational resources and struggle to generalize to unseen tasks. To address these limitations, we propose RUIE (Retrieval-based Unified Information Extraction), a framework that leverages in-context learning to enable rapid generalization while reducing computational costs. The key challenge in RUIE is selecting the most beneficial demonstrations for LLMs to effectively handle diverse IE tasks. To achieve this, we integrate LLM preferences for ranking candidate demonstrations and design a keyword-enhanced reward model to capture fine-grained relationships between queries and demonstrations. We then train a bi-encoder retriever for UIE through contrastive learning and knowledge distillation. To the best of our knowledge, RUIE is the first trainable retrieval framework for UIE. Experimental results on 8 held-out datasets demonstrate RUIE's effectiveness in generalizing to unseen tasks, with average F1-score improvements of 19.22 and 3.13 compared to instruction-tuning methods and other retrievers, respectively. Further analysis confirms RUIE's adaptability to LLMs of varying sizes and the importance of its key components.
Cross-Modality Safety Alignment
Jun 21, 2024As Artificial General Intelligence (AGI) becomes increasingly integrated into various facets of human life, ensuring the safety and ethical alignment of such systems is paramount. Previous studies primarily focus on single-modality threats, which may not suffice given the integrated and complex nature of cross-modality interactions. We introduce a novel safety alignment challenge called Safe Inputs but Unsafe Output (SIUO) to evaluate cross-modality safety alignment. Specifically, it considers cases where single modalities are safe independently but could potentially lead to unsafe or unethical outputs when combined. To empirically investigate this problem, we developed the SIUO, a cross-modality benchmark encompassing 9 critical safety domains, such as self-harm, illegal activities, and privacy violations. Our findings reveal substantial safety vulnerabilities in both closed- and open-source LVLMs, such as GPT-4V and LLaVA, underscoring the inadequacy of current models to reliably interpret and respond to complex, real-world scenarios.
medIKAL: Integrating Knowledge Graphs as Assistants of LLMs for Enhanced Clinical Diagnosis on EMRs
Jun 20, 2024



Electronic Medical Records (EMRs), while integral to modern healthcare, present challenges for clinical reasoning and diagnosis due to their complexity and information redundancy. To address this, we proposed medIKAL (Integrating Knowledge Graphs as Assistants of LLMs), a framework that combines Large Language Models (LLMs) with knowledge graphs (KGs) to enhance diagnostic capabilities. medIKAL assigns weighted importance to entities in medical records based on their type, enabling precise localization of candidate diseases within KGs. It innovatively employs a residual network-like approach, allowing initial diagnosis by the LLM to be merged into KG search results. Through a path-based reranking algorithm and a fill-in-the-blank style prompt template, it further refined the diagnostic process. We validated medIKAL's effectiveness through extensive experiments on a newly introduced open-sourced Chinese EMR dataset, demonstrating its potential to improve clinical diagnosis in real-world settings.
You Only Forward Once: Prediction and Rationalization in A Single Forward Pass
Nov 04, 2023



Unsupervised rationale extraction aims to extract concise and contiguous text snippets to support model predictions without any annotated rationale. Previous studies have used a two-phase framework known as the Rationalizing Neural Prediction (RNP) framework, which follows a generate-then-predict paradigm. They assumed that the extracted explanation, called rationale, should be sufficient to predict the golden label. However, the assumption above deviates from the original definition and is too strict to perform well. Furthermore, these two-phase models suffer from the interlocking problem and spurious correlations. To solve the above problems, we propose a novel single-phase framework called You Only Forward Once (YOFO), derived from a relaxed version of rationale where rationales aim to support model predictions rather than make predictions. In our framework, A pre-trained language model like BERT is deployed to simultaneously perform prediction and rationalization with less impact from interlocking or spurious correlations. Directly choosing the important tokens in an unsupervised manner is intractable. Instead of directly choosing the important tokens, YOFO gradually removes unimportant tokens during forward propagation. Through experiments on the BeerAdvocate and Hotel Review datasets, we demonstrate that our model is able to extract rationales and make predictions more accurately compared to RNP-based models. We observe an improvement of up to 18.4\% in token-level F1 compared to previous state-of-the-art methods. We also conducted analyses and experiments to explore the extracted rationales and token decay strategies. The results show that YOFO can extract precise and important rationales while removing unimportant tokens in the middle part of the model.
MHLAT: Multi-hop Label-wise Attention Model for Automatic ICD Coding
Sep 16, 2023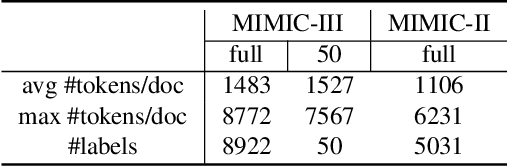
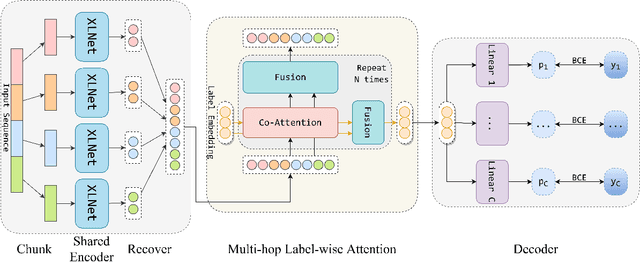
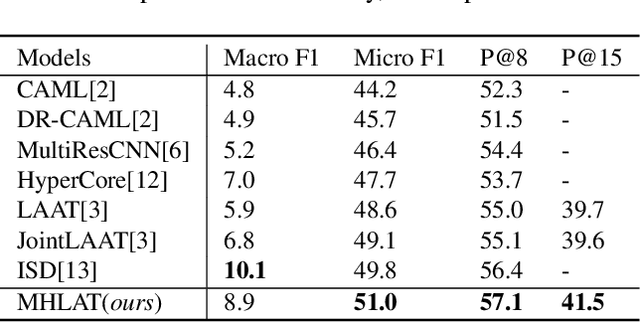
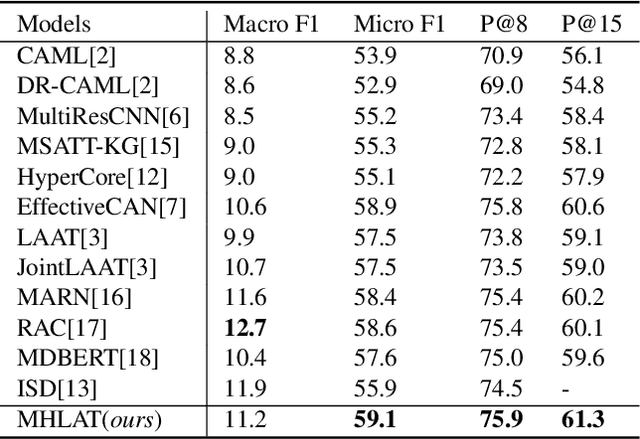
International Classification of Diseases (ICD) coding is the task of assigning ICD diagnosis codes to clinical notes. This can be challenging given the large quantity of labels (nearly 9,000) and lengthy texts (up to 8,000 tokens). However, unlike the single-pass reading process in previous works, humans tend to read the text and label definitions again to get more confident answers. Moreover, although pretrained language models have been used to address these problems, they suffer from huge memory usage. To address the above problems, we propose a simple but effective model called the Multi-Hop Label-wise ATtention (MHLAT), in which multi-hop label-wise attention is deployed to get more precise and informative representations. Extensive experiments on three benchmark MIMIC datasets indicate that our method achieves significantly better or competitive performance on all seven metrics, with much fewer parameters to optimize.