 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHLAT: Multi-hop Label-wise Attention Model for Automatic ICD Coding
Paper and Code
Sep 16, 2023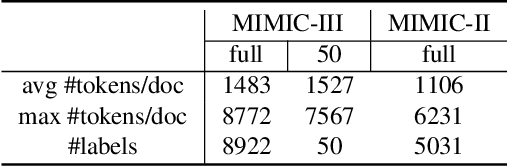
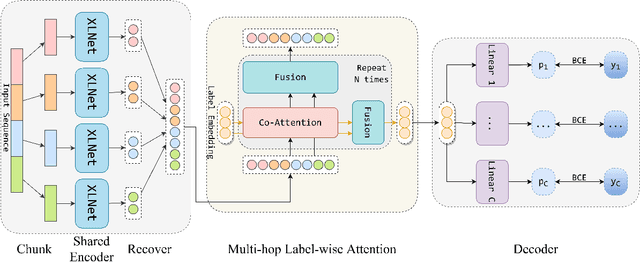
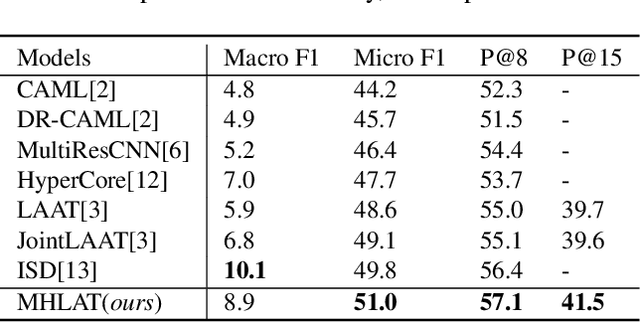
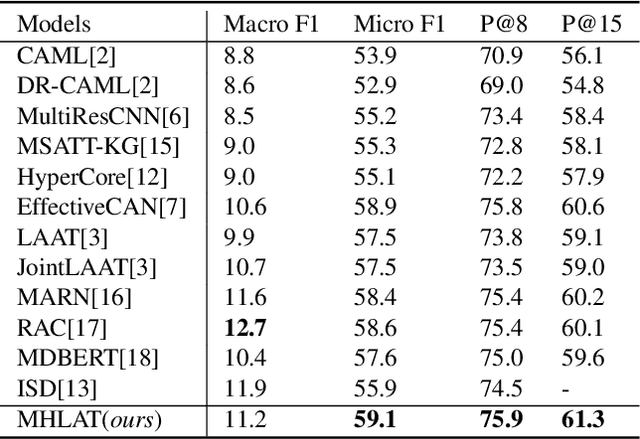
International Classification of Diseases (ICD) coding is the task of assigning ICD diagnosis codes to clinical notes. This can be challenging given the large quantity of labels (nearly 9,000) and lengthy texts (up to 8,000 tokens). However, unlike the single-pass reading process in previous works, humans tend to read the text and label definitions again to get more confident answers. Moreover, although pretrained language models have been used to address these problems, they suffer from huge memory usage. To address the above problems, we propose a simple but effective model called the Multi-Hop Label-wise ATtention (MHLAT), in which multi-hop label-wise attention is deployed to get more precise and informative representations. Extensive experiments on three benchmark MIMIC datasets indicate that our method achieves significantly better or competitive performance on all seven metrics, with much fewer parameters to optimize.