 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDAR-VL: Stable and Efficient Block-wise Diffusion for Vision-Language Understanding
Dec 16, 2025



Block-wise discrete diffusion offers an attractive balance between parallel generation and causal dependency modeling, making it a promising backbone for vision-language modeling. However, its practical adoption has been limited by high training cost, slow convergence, and instability, which have so far kept it behind strong autoregressive (AR) baselines. We present \textbf{SDAR-VL}, the first systematic application of block-wise discrete diffusion to large-scale vision-language understanding (VLU), together with an \emph{integrated framework for efficient and stable training}. This framework unifies three components: (1) \textbf{Asynchronous Block-wise Noise Scheduling} to diversify supervision within each batch; (2) \textbf{Effective Mask Ratio Scaling} for unbiased loss normalization under stochastic masking; and (3) a \textbf{Progressive Beta Noise Curriculum} that increases effective mask coverage while preserving corruption diversity. Experiments on 21 single-image, multi-image, and video benchmarks show that SDAR-VL consistently improves \emph{training efficiency}, \emph{convergence stability}, and \emph{task performance} over conventional block diffusion. On this evaluation suite, SDAR-VL sets a new state of the art among diffusion-based vision-language models and, under matched settings, matches or surpasses strong AR baselines such as LLaVA-OneVision as well as the global diffusion baseline LLaDA-V, establishing block-wise diffusion as a practical backbone for VLU.
Multiple Object Stitching for Unsupervised Representation Learning
Jun 09, 2025Contrastive learning for single object centric images has achieved remarkable progress on unsupervised representation, but suffering inferior performance on the widespread images with multiple objects. In this paper, we propose a simple but effective method, Multiple Object Stitching (MOS), to refine the unsupervised representation for multi-object images. Specifically, we construct the multi-object images by stitching the single object centric ones, where the objects in the synthesized multi-object images are predetermined. Hence, compared to the existing contrastive methods, our method provides additional object correspondences between multi-object images without human annotations. In this manner, our method pays more attention to the representations of each object in multi-object image, thus providing more detailed representations for complicated downstream tasks, such as object detection and semantic segmentation. Experimental results on ImageNet, CIFAR and COCO datasets demonstrate that our proposed method achieves the leading unsupervised representation performance on both single object centric images and multi-object ones. The source code is available at https://github.com/visresearch/MultipleObjectStitching.
A Survey on Image-text Multimodal Models
Sep 23, 2023



Amidst the evolving landscape of artificial intelligence, the convergence of visual and textual information has surfaced as a crucial frontier, leading to the advent of image-text multimodal models. This paper provides a comprehensive review of the evolution and current state of image-text multimodal models, exploring their application value, challenges, and potential research trajectories. Initially, we revisit the basic concepts and developmental milestones of these models, introducing a novel classification that segments their evolution into three distinct phases, based on their time of introduction and subsequent impact on the discipline. Furthermore, based on the tasks' significance and prevalence in the academic landscape, we propose a categorization of the tasks associated with image-text multimodal models into five major types, elucidating the recent progress and key technologies within each category. Despite the remarkable accomplishments of these models, numerous challenges and issues persist. This paper delves into the inherent challenges and limitations of image-text multimodal models, fostering the exploration of prospective research directions. Our objective is to offer an exhaustive overview of the present research landscape of image-text multimodal models and to serve as a valuable reference for future scholarly endeavors. We extend an invitation to the broader community to collaborate in enhancing the image-text multimodal model community, accessible at: \href{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}.
Inter-Instance Similarity Modeling for Contrastive Learning
Jun 29, 2023



The existing contrastive learning methods widely adopt one-hot instance discrimination as pretext task for self-supervised learning, which inevitably neglects rich inter-instance similarities among natural images, then leading to potential representation degeneration. In this paper, we propose a novel image mix method, PatchMix, for contrastive learning in Vision Transformer (ViT), to model inter-instance similarities among images. Following the nature of ViT, we randomly mix multiple images from mini-batch in patch level to construct mixed image patch sequences for ViT. Compared to the existing sample mix methods, our PatchMix can flexibly and efficiently mix more than two images and simulate more complicated similarity relations among natural images. In this manner, our contrastive framework can significantly reduce the gap between contrastive objective and ground truth in reality. Experimental results demonstrate that our proposed method significantly outperforms the previous state-of-the-art on both ImageNet-1K and CIFAR datasets, e.g., 3.0% linear accuracy improvement on ImageNet-1K and 8.7% kNN accuracy improvement on CIFAR100. Moreover, our method achieves the leading transfer performance on downstream tasks, object detection and instance segmentation on COCO dataset. The code is available at https://github.com/visresearch/patchmix
Machine-learning-based methods for output only structural modal identification
Apr 16, 2020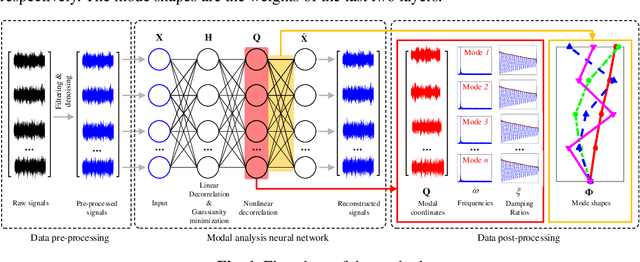
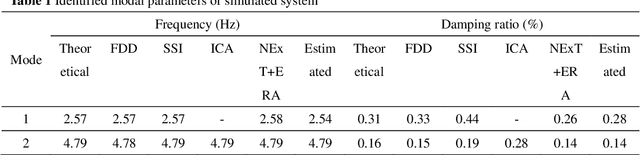
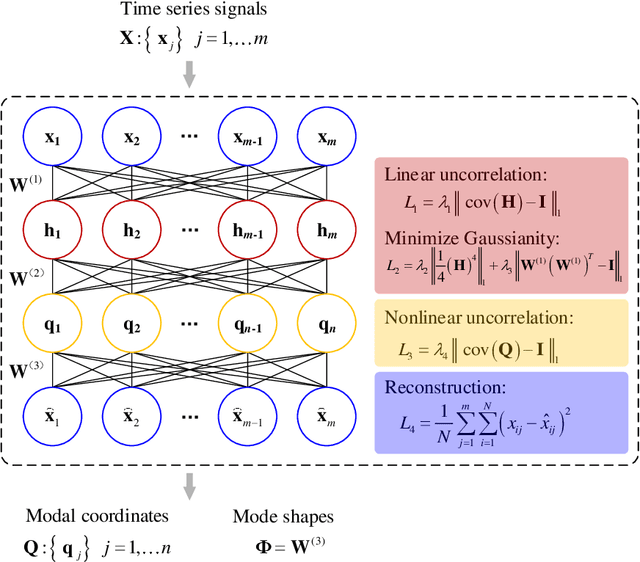
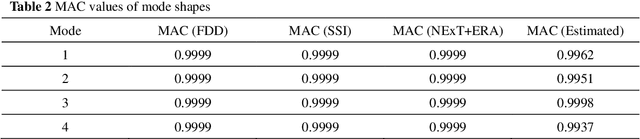
In this study, we propose a machine-learning-based approach to identify the modal parameters of the output only data for structural health monitoring (SHM) that makes full use of the characteristic of independence of modal responses and the principle of machine learning. By taking advantage of the independence feature of each mode, we use the principle of unsupervised learning, making the training process of the deep neural network becomes the process of modal separation. A self-coding deep neural network is designed to identify the structural modal parameters from the vibration data of structures. The mixture signals, that is, the structural response data, are used as the input of the neural network. Then we use a complex cost function to restrict the training process of the neural network, making the output of the third layer the modal responses we want, and the weights of the last two layers are mode shapes. The deep neural network is essentially a nonlinear objective function optimization problem. A novel loss function is proposed to constrain the independent feature with consideration of uncorrelation and non-Gaussianity to restrict the designed neural network to obtain the structural modal parameters. A numerical example of a simple structure and an example of actual SHM data from a cable-stayed bridge are presented to illustrate the modal parameter identification ability of the proposed approach. The results show the approach s good capability in blindly extracting modal information from system responses.
Semi-Unsupervised Lifelong Learning for Sentiment Classification: Less Manual Data Annotation and More Self-Studying
May 30, 2019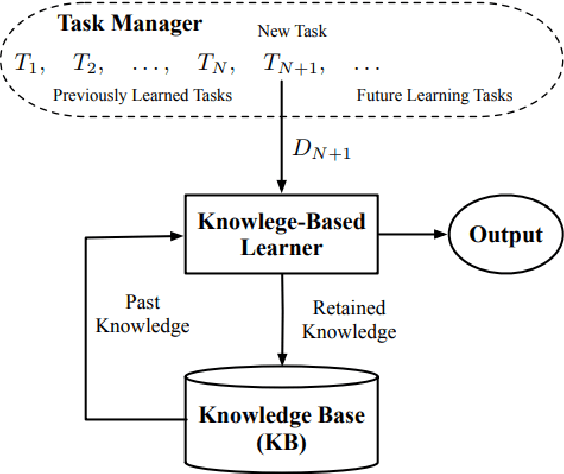
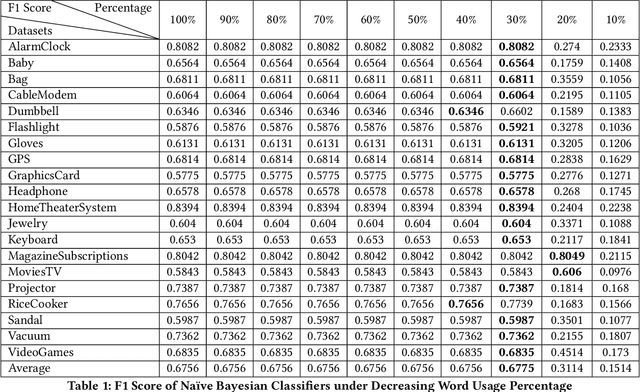
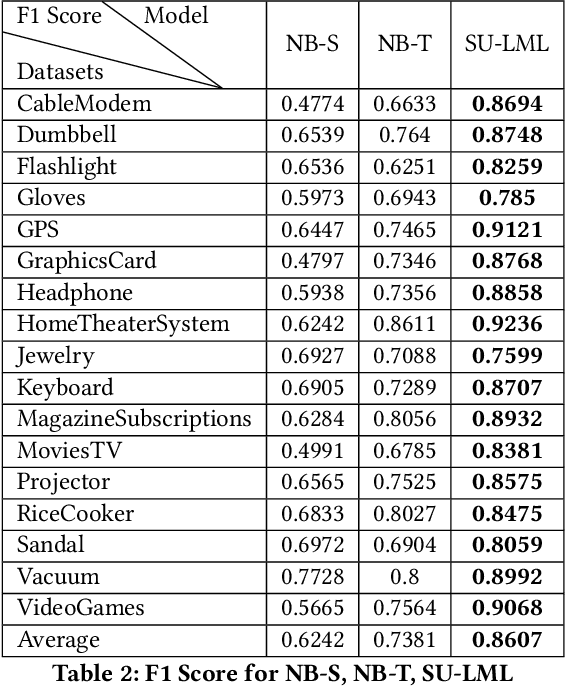
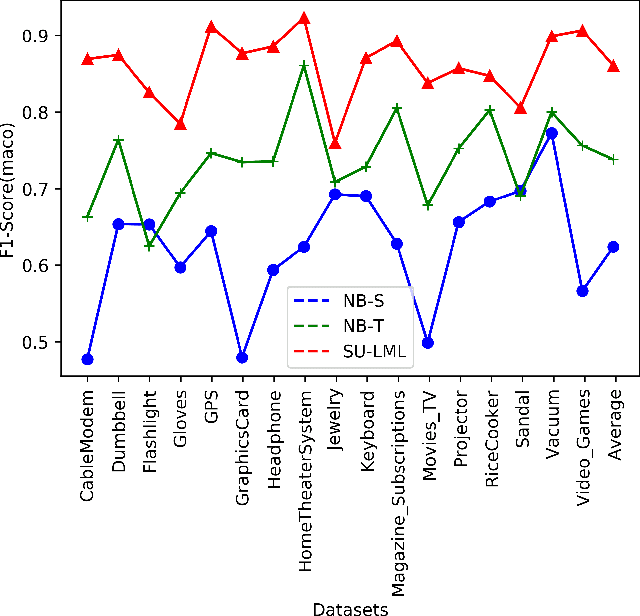
Lifelong machine learning is a novel machine learning paradigm which can continually accumulate knowledge during learning. The knowledge extracting and reusing abilities enable the lifelong machine learning to solve the related problems. The traditional approaches like Na\"ive Bayes and some neural network based approaches only aim to achieve the best performance upon a single task. Unlike them, the lifelong machine learning in this paper focuses on how to accumulate knowledge during learning and leverage them for further tasks. Meanwhile, the demand for labelled data for training also is significantly decreased with the knowledge reusing. This paper suggests that the aim of the lifelong learning is to use less labelled data and computational cost to achieve the performance as well as or even better than the supervised learning.