 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDRL: A Reinforcement Learning Framework Inspired by Cerebellar Circuits and Dendritic Computational Strategies
Feb 17, 2026Reinforcement learning (RL) has achieved notable performance in high-dimensional sequential decision-making tasks, yet remains limited by low sample efficiency, sensitivity to noise, and weak generalization under partial observability. Most existing approaches address these issues primarily through optimization strategies, while the role of architectural priors in shaping representation learning and decision dynamics is less explored. Inspired by structural principles of the cerebellum, we propose a biologically grounded RL architecture that incorporate large expansion, sparse connectivity, sparse activation, and dendritic-level modulation. Experiments on noisy, high-dimensional RL benchmarks show that both the cerebellar architecture and dendritic modulation consistently improve sample efficiency, robustness, and generalization compared to conventional designs. Sensitivity analysis of architectural parameters suggests that cerebellum-inspired structures can offer optimized performance for RL with constrained model parameters. Overall, our work underscores the value of cerebellar structural priors as effective inductive biases for RL.
SIC-Free Rate-Splitting Multiple Access: Constellation-Constrained Optimization and Application to Large-Scale Systems
Jun 15, 2025Rate-Splitting Multiple Access (RSMA) has been recognized as a promising multiple access technique for future wireless communication systems. Recent research demonstrates that RSMA can maintain its superiority without relying on Successive Interference Cancellation (SIC) receivers. In practical systems, SIC-free receivers are more attractive than SIC receivers because of their low complexity and latency. This paper evaluates the theoretical limits of RSMA with and without SIC receivers under finite constellations. We first derive the constellation-constrained rate expressions for RSMA. We then design algorithms based on projected subgradient ascent to optimize the precoders and maximize the weighted sum-rate or max-min fairness (MMF) among users. To apply the proposed optimization algorithms to large-scale systems, one challenge lies in the exponentially increasing computational complexity brought about by the constellation-constrained rate expressions. In light of this, we propose methods to avoid such computational burden. Numerical results show that, under optimized precoders, SIC-free RSMA leads to minor losses in weighted sum-rate and MMF performance in comparison to RSMA with SIC receivers, making it a viable option for future implementations.
Optimal and Suboptimal Decoders under Finite-Alphabet Interference: A Mismatched Decoding Perspective
Jun 14, 2025Interference widely exists in communication systems and is often not optimally treated at the receivers due to limited knowledge and/or computational burden. Evolutions of receivers have been proposed to balance complexity and spectral efficiency, for example, for 6G, while commonly used performance metrics, such as capacity and mutual information, fail to capture the suboptimal treatment of interference, leading to potentially inaccurate performance evaluations. Mismatched decoding is an information-theoretic tool for analyzing communications with suboptimal decoders. In this work, we use mismatched decoding to analyze communications with decoders that treat interference suboptimally, aiming at more accurate performance metrics. Specifically, we consider a finite-alphabet input Gaussian channel under interference, representative of modern systems, where the decoder can be matched (optimal) or mismatched (suboptimal) to the channel. The matched capacity is derived using Mutual Information (MI), while a lower bound on the mismatched capacity under various decoding metrics is derived using the Generalized Mutual Information (GMI). We show that the decoding metric in the proposed channel model is closely related to the behavior of the demodulator in Bit-Interleaved Coded Modulation (BICM) systems. Simulations illustrate that GMI/MI accurately predicts the throughput performance of BICM-type systems. Finally, we extend the channel model and the GMI to multiple antenna cases, with an example of multi-user multiple-input-single-output (MU-MISO) precoder optimization problem considering GMI under different decoding strategies. In short, this work discovers new insights about the impact of interference, proposes novel receivers, and introduces a new design and performance evaluation framework that more accurately captures the effect of interference.
Brain-inspired Computing Based on Machine Learning And Deep Learning:A Review
Dec 12, 2023



The continuous development of artificial intelligence has a profound impact on biomedical research and other fields.Brain-inspired computing is an important intersection of multimodal technology and biomedical field. This paper provides a comprehensive review of machine learning (ML) and deep learning (DL) models in brain-inspired computing, tracking their evolution, application value, challenges, and potential research trajectories. First, the basic concepts and development history are reviewed, and their evolution is divided into two stages: recent machine learning and current deep learning, emphasizing the importance of each stage in the research state of brain-inspired computing. In addition, the latest progress and key techniques of deep learning in different tasks of brain-inspired computing are introduced from six perspectives. Despite significant progress, challenges remain in making full use of its capabilities. This paper aims to provide a comprehensive review of brain-inspired computing models based on machine learning and deep learning, highlighting their potential in various applications and providing a valuable reference for future academic research. It can be accessed through the following url: https://github.com/ultracoolHub/brain-inspired-computing
A Survey on Image-text Multimodal Models
Sep 23, 2023



Amidst the evolving landscape of artificial intelligence, the convergence of visual and textual information has surfaced as a crucial frontier, leading to the advent of image-text multimodal models. This paper provides a comprehensive review of the evolution and current state of image-text multimodal models, exploring their application value, challenges, and potential research trajectories. Initially, we revisit the basic concepts and developmental milestones of these models, introducing a novel classification that segments their evolution into three distinct phases, based on their time of introduction and subsequent impact on the discipline. Furthermore, based on the tasks' significance and prevalence in the academic landscape, we propose a categorization of the tasks associated with image-text multimodal models into five major types, elucidating the recent progress and key technologies within each category. Despite the remarkable accomplishments of these models, numerous challenges and issues persist. This paper delves into the inherent challenges and limitations of image-text multimodal models, fostering the exploration of prospective research directions. Our objective is to offer an exhaustive overview of the present research landscape of image-text multimodal models and to serve as a valuable reference for future scholarly endeavors. We extend an invitation to the broader community to collaborate in enhancing the image-text multimodal model community, accessible at: \href{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}.
Rate-Splitting Multiple Access: Finite Constellations, Receiver Design, and SIC-free Implementation
May 30, 2023



Rate-Splitting Multiple Access (RSMA) has emerged as a novel multiple access technique that enlarges the achievable rate region of Multiple-Input Multiple-Output (MIMO) broadcast channels with linear precoding. In this work, we jointly address three practical but fundamental questions: (1) How to exploit the benefit of RSMA under finite constellations? (2) What are the potential and promising ways to implement RSMA receivers? (3) Can RSMA still retain its superiority in the absence of successive interference cancellers (SIC)? To address these concerns, we first propose low-complexity precoder designs taking finite constellations into account and show that the potential of RSMA is better achieved with such designs than those assuming Gaussian signalling. We then consider some practical receiver designs that can be applied to RSMA. We notice that these receiver designs follow one of two principles: (1) SIC: cancelling upper layer signals before decoding the lower layer and (2) non-SIC: treating upper layer signals as noise when decoding the lower layer. In light of this, we propose to alter the precoder design according to the receiver category. Through link-level simulations, the effectiveness of the proposed precoder and receiver designs are verified. More importantly, we show that it is possible to preserve the superiority of RSMA over Spatial Domain Multiple Access (SDMA), including SDMA with advanced receivers, even without SIC at the receivers. Those results therefore open the door to competitive implementable RSMA strategies for 6G and beyond communications.
Vision-based Excavator Activity Analysis and Safety Monitoring System
Oct 06, 2021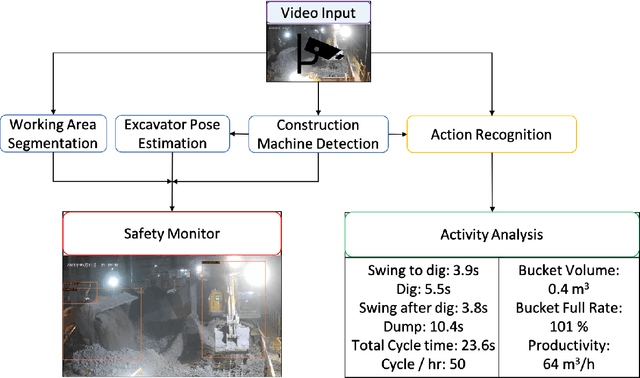
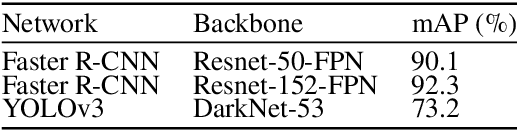

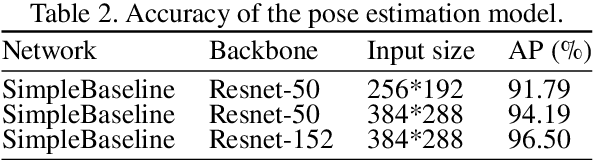
In this paper, we propose an excavator activity analysis and safety monitoring system, leveraging recent advancements in deep learning and computer vision. Our proposed system detects the surrounding environment and the excavators while estimating the poses and actions of the excavators. Compared to previous systems, our method achieves higher accuracy in object detection, pose estimation, and action recognition tasks. In addition, we build an excavator dataset using the Autonomous Excavator System (AES) on the waste disposal recycle scene to demonstrate the effectiveness of our system. We also evaluate our method on a benchmark construction dataset. The experimental results show that the proposed action recognition approach outperforms the state-of-the-art approaches on top-1 accuracy by about 5.18%.
Text2Video: Text-driven Talking-head Video Synthesis with Phonetic Dictionary
Apr 29, 2021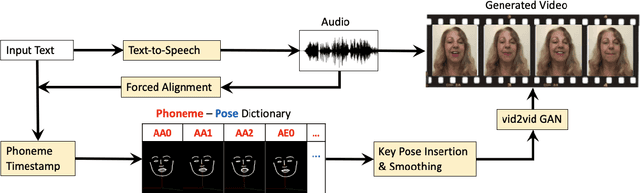

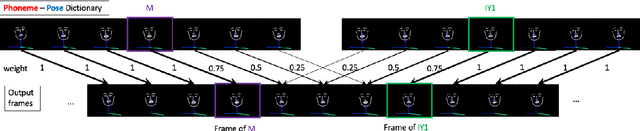
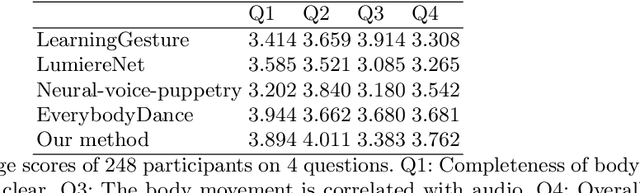
With the advance of deep learning technology, automatic video generation from audio or text has become an emerging and promising research topic. In this paper, we present a novel approach to synthesize video from the text. The method builds a phoneme-pose dictionary and trains a generative adversarial network (GAN) to generate video from interpolated phoneme poses. Compared to audio-driven video generation algorithms, our approach has a number of advantages: 1) It only needs a fraction of the training data used by an audio-driven approach; 2) It is more flexible and not subject to vulnerability due to speaker variation; 3) It significantly reduces the preprocessing, training and inference time. We perform extensive experiments to compare the proposed method with state-of-the-art talking face generation methods on a benchmark dataset and datasets of our own. The results demonstrate the effectiveness and superiority of our approach.
Personalized Speech2Video with 3D Skeleton Regularization and Expressive Body Poses
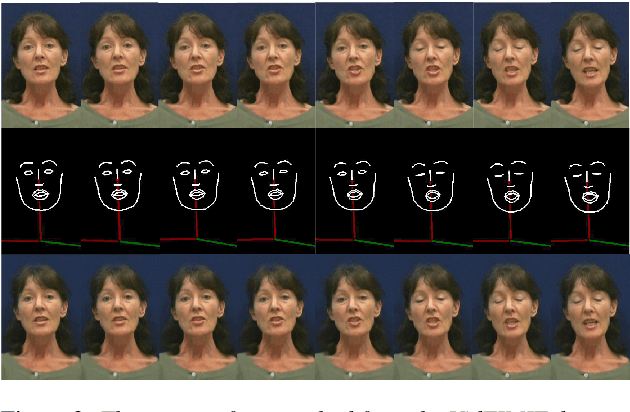
Jul 17, 2020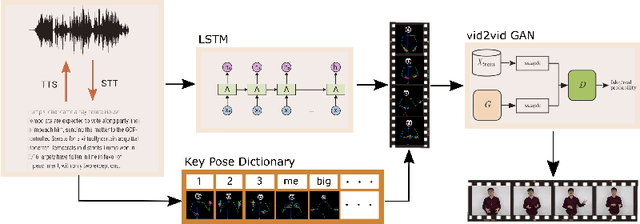
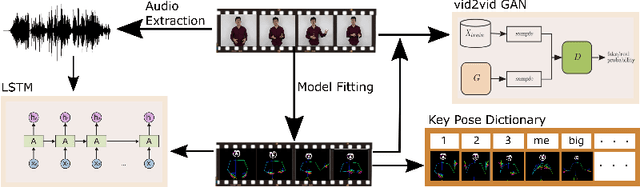
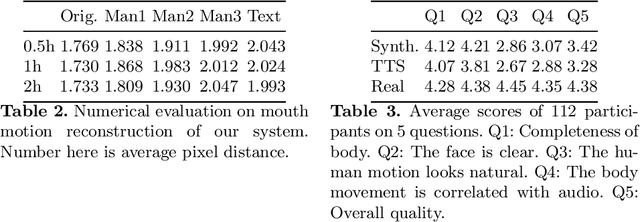
In this paper, we propose a novel approach to convert given speech audio to a photo-realistic speaking video of a specific person, where the output video has synchronized, realistic, and expressive rich body dynamics. We achieve this by first generating 3D skeleton movements from the audio sequence using a recurrent neural network (RNN), and then synthesizing the output video via a conditional generative adversarial network (GAN). To make the skeleton movement realistic and expressive, we embed the knowledge of an articulated 3D human skeleton and a learned dictionary of personal speech iconic gestures into the generation process in both learning and testing pipelines. The former prevents the generation of unreasonable body distortion, while the later helps our model quickly learn meaningful body movement through a few recorded videos. To produce photo-realistic and high-resolution video with motion details, we propose to insert part attention mechanisms in the conditional GAN, where each detailed part, e.g. head and hand, is automatically zoomed in to have their own discriminators. To validate our approach, we collect a dataset with 20 high-quality videos from 1 male and 1 female model reading various documents under different topics. Compared with previous SoTA pipelines handling similar tasks, our approach achieves better results by a user study.
DVI: Depth Guided Video Inpainting for Autonomous Driving
Jul 17, 2020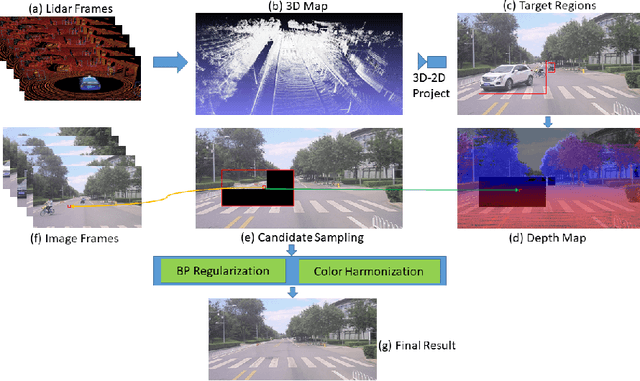
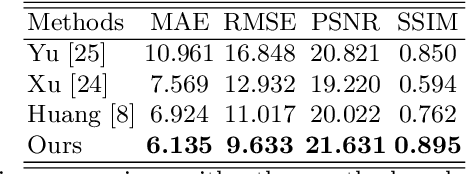


To get clear street-view and photo-realistic simulation in autonomous driving, we present an automatic video inpainting algorithm that can remove traffic agents from videos and synthesize missing regions with the guidance of depth/point cloud. By building a dense 3D map from stitched point clouds, frames within a video are geometrically correlated via this common 3D map. In order to fill a target inpainting area in a frame, it is straightforward to transform pixels from other frames into the current one with correct occlusion. Furthermore, we are able to fuse multiple videos through 3D point cloud registration, making it possible to inpaint a target video with multiple source videos. The motivation is to solve the long-time occlusion problem where an occluded area has never been visible in the entire video. To our knowledge, we are the first to fuse multiple videos for video inpainting. To verify the effectiveness of our approach, we build a large inpainting dataset in the real urban road environment with synchronized images and Lidar data including many challenge scenes, e.g., long time occlusion. The experimental results show that the proposed approach outperforms the state-of-the-art approaches for all the criteria, especially the RMSE (Root Mean Squared Error) has been reduced by about 13%.