 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategory Discovery: An Open-World Perspective
Sep 26, 2025



Category discovery (CD) is an emerging open-world learning task, which aims at automatically categorizing unlabelled data containing instances from unseen classes, given some labelled data from seen classes. This task has attracted significant attention over the years and leads to a rich body of literature trying to address the problem from different perspectives. In this survey, we provide a comprehensive review of the literature, and offer detailed analysis and in-depth discussion on different methods. Firstly, we introduce a taxonomy for the literature by considering two base settings, namely novel category discovery (NCD) and generalized category discovery (GCD), and several derived settings that are designed to address the extra challenges in different real-world application scenarios, including continual category discovery, skewed data distribution, federated category discovery, etc. Secondly, for each setting, we offer a detailed analysis of the methods encompassing three fundamental components, representation learning, label assignment, and estimation of class number. Thirdly, we benchmark all the methods and distill key insights showing that large-scale pretrained backbones, hierarchical and auxiliary cues, and curriculum-style training are all beneficial for category discovery, while challenges remain in the design of label assignment, the estimation of class numbers, and scaling to complex multi-object scenarios.Finally, we discuss the key insights from the literature so far and point out promising future research directions. We compile a living survey of the category discovery literature at \href{https://github.com/Visual-AI/Category-Discovery}{https://github.com/Visual-AI/Category-Discovery}.
Hyperbolic Category Discovery
Apr 08, 2025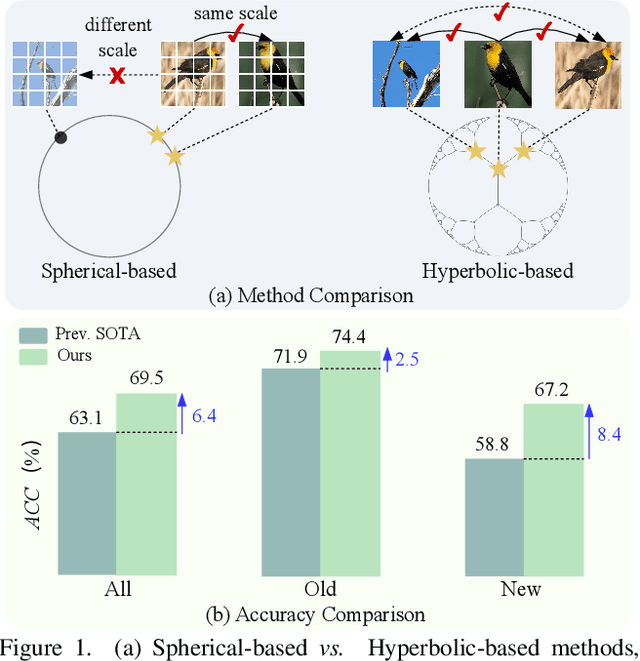
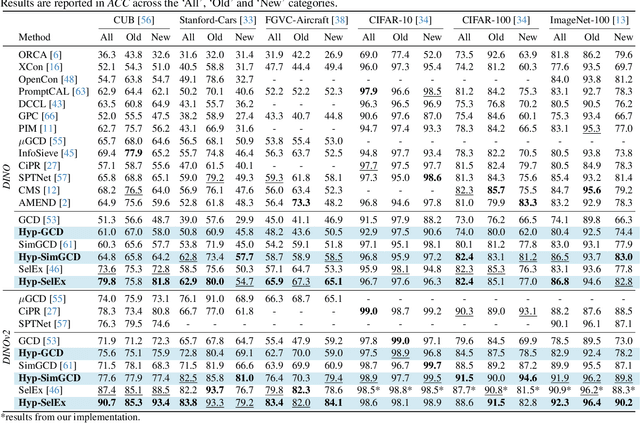
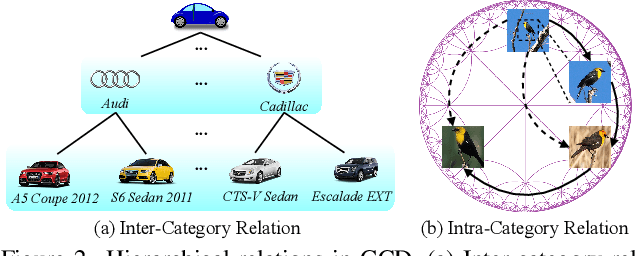
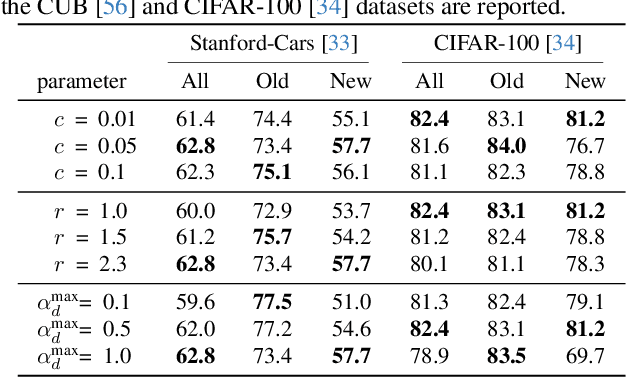
Generalized Category Discovery (GCD) is an intriguing open-world problem that has garnered increasing attention. Given a dataset that includes both labelled and unlabelled images, GCD aims to categorize all images in the unlabelled subset, regardless of whether they belong to known or unknown classes. In GCD, the common practice typically involves applying a spherical projection operator at the end of the self-supervised pretrained backbone, operating within Euclidean or spherical space. However, both of these spaces have been shown to be suboptimal for encoding samples that possesses hierarchical structures. In contrast, hyperbolic space exhibits exponential volume growth relative to radius, making it inherently strong at capturing the hierarchical structure of samples from both seen and unseen categories. Therefore, we propose to tackle the category discovery challenge in the hyperbolic space. We introduce HypCD, a simple \underline{Hyp}erbolic framework for learning hierarchy-aware representations and classifiers for generalized \underline{C}ategory \underline{D}iscovery. HypCD first transforms the Euclidean embedding space of the backbone network into hyperbolic space, facilitating subsequent representation and classification learning by considering both hyperbolic distance and the angle between samples. This approach is particularly helpful for knowledge transfer from known to unknown categories in GCD. We thoroughly evaluate HypCD on public GCD benchmarks, by applying it to various baseline and state-of-the-art methods, consistently achieving significant improvements.
DebGCD: Debiased Learning with Distribution Guidance for Generalized Category Discovery
Apr 07, 2025In this paper, we tackle the problem of Generalized Category Discovery (GCD). Given a dataset containing both labelled and unlabelled images, the objective is to categorize all images in the unlabelled subset, irrespective of whether they are from known or unknown classes. In GCD, an inherent label bias exists between known and unknown classes due to the lack of ground-truth labels for the latter. State-of-the-art methods in GCD leverage parametric classifiers trained through self-distillation with soft labels, leaving the bias issue unattended. Besides, they treat all unlabelled samples uniformly, neglecting variations in certainty levels and resulting in suboptimal learning. Moreover, the explicit identification of semantic distribution shifts between known and unknown classes, a vital aspect for effective GCD, has been neglected. To address these challenges, we introduce DebGCD, a \underline{Deb}iased learning with distribution guidance framework for \underline{GCD}. Initially, DebGCD co-trains an auxiliary debiased classifier in the same feature space as the GCD classifier, progressively enhancing the GCD features. Moreover, we introduce a semantic distribution detector in a separate feature space to implicitly boost the learning efficacy of GCD. Additionally, we employ a curriculum learning strategy based on semantic distribution certainty to steer the debiased learning at an optimized pace. Thorough evaluations on GCD benchmarks demonstrate the consistent state-of-the-art performance of our framework, highlighting its superiority. Project page: https://visual-ai.github.io/debgcd/
ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
Feb 21, 2025The objective in this paper is to improve the performance of text-to-image retrieval. To this end, we introduce a new framework that can boost the performance of large-scale pre-trained vision-language models, so that they can be used for text-to-image re-ranking. The approach, Enhanced Language-Image Pre-training (ELIP), uses the text query to predict a set of visual prompts to condition the ViT image encoding. ELIP can easily be applied to the commonly used CLIP/SigLIP and the state-of-the-art BLIP-2 architectures. To train the architecture with limited computing resources, we develop a 'student friendly' best practice involving global hard sample mining, and selection and curation of a large-scale dataset. On the evaluation side, we set up two new out-of-distribution benchmarks, Occluded COCO and ImageNet-R, to assess the zero-shot generalisation of the models to different domains. Benefiting from the novel architecture and data curation, experiments show our enhanced network significantly boosts CLIP/SigLIP performance and outperforms the state-of-the-art BLIP-2 model on text-to-image retrieval.
UADet: A Remarkably Simple Yet Effective Uncertainty-Aware Open-Set Object Detection Framework
Dec 12, 2024



We tackle the challenging problem of Open-Set Object Detection (OSOD), which aims to detect both known and unknown objects in unlabelled images. The main difficulty arises from the absence of supervision for these unknown classes, making it challenging to distinguish them from the background. Existing OSOD detectors either fail to properly exploit or inadequately leverage the abundant unlabeled unknown objects in training data, restricting their performance. To address these limitations, we propose UADet, an Uncertainty-Aware Open-Set Object Detector that considers appearance and geometric uncertainty. By integrating these uncertainty measures, UADet effectively reduces the number of unannotated instances incorrectly utilized or omitted by previous methods. Extensive experiments on OSOD benchmarks demonstrate that UADet substantially outperforms previous state-of-the-art (SOTA) methods in detecting both known and unknown objects, achieving a 1.8x improvement in unknown recall while maintaining high performance on known classes. When extended to Open World Object Detection (OWOD), our method shows significant advantages over the current SOTA method, with average improvements of 13.8% and 6.9% in unknown recall on M-OWODB and S-OWODB benchmarks, respectively. Extensive results validate the effectiveness of our uncertainty-aware approach across different open-set scenarios.
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
May 11, 2023


The Segment Anything Model (SAM) has recently gained popularity in the field of image segmentation. Thanks to its impressive capabilities in all-round segmentation tasks and its prompt-based interface, SAM has sparked intensive discussion within the community. It is even said by many prestigious experts that image segmentation task has been "finished" by SAM. However, medical image segmentation, although an important branch of the image segmentation family, seems not to be included in the scope of Segmenting "Anything". Many individual experiments and recent studies have shown that SAM performs subpar in medical image segmentation. A natural question is how to find the missing piece of the puzzle to extend the strong segmentation capability of SAM to medical image segmentation. In this paper, instead of fine-tuning the SAM model, we propose Med SAM Adapter, which integrates the medical specific domain knowledge to the segmentation model, by a simple yet effective adaptation technique. Although this work is still one of a few to transfer the popular NLP technique Adapter to computer vision cases, this simple implementation shows surprisingly good performance on medical image segmentation. A medical image adapted SAM, which we have dubbed Medical SAM Adapter (MSA), shows superior performance on 19 medical image segmentation tasks with various image modalities including CT, MRI, ultrasound image, fundus image, and dermoscopic images. MSA outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, such as nnUNet, TransUNet, UNetr, MedSegDiff, and also outperforms the fully fine-turned MedSAM with a considerable performance gap. Code will be released at: https://github.com/WuJunde/Medical-SAM-Adapter.
Multi-rater Prism: Learning self-calibrated medical image segmentation from multiple raters
Dec 01, 2022



In medical image segmentation, it is often necessary to collect opinions from multiple experts to make the final decision. This clinical routine helps to mitigate individual bias. But when data is multiply annotated, standard deep learning models are often not applicable. In this paper, we propose a novel neural network framework, called Multi-Rater Prism (MrPrism) to learn the medical image segmentation from multiple labels. Inspired by the iterative half-quadratic optimization, the proposed MrPrism will combine the multi-rater confidences assignment task and calibrated segmentation task in a recurrent manner. In this recurrent process, MrPrism can learn inter-observer variability taking into account the image semantic properties, and finally converges to a self-calibrated segmentation result reflecting the inter-observer agreement. Specifically, we propose Converging Prism (ConP) and Diverging Prism (DivP) to process the two tasks iteratively. ConP learns calibrated segmentation based on the multi-rater confidence maps estimated by DivP. DivP generates multi-rater confidence maps based on the segmentation masks estimated by ConP. The experimental results show that by recurrently running ConP and DivP, the two tasks can achieve mutual improvement. The final converged segmentation result of MrPrism outperforms state-of-the-art (SOTA) strategies on a wide range of medical image segmentation tasks.
An Efficient Person Clustering Algorithm for Open Checkout-free Groceries
Aug 05, 2022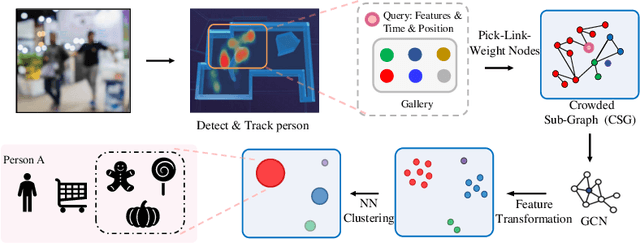

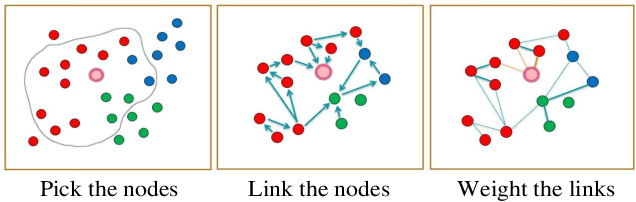
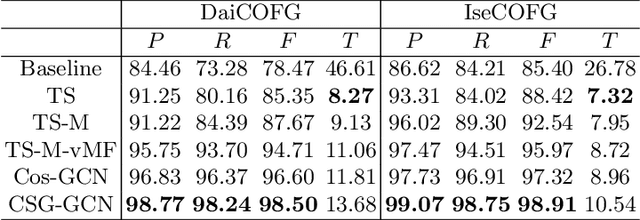
Open checkout-free grocery is the grocery store where the customers never have to wait in line to check out. Developing a system like this is not trivial since it faces challenges of recognizing the dynamic and massive flow of people. In particular, a clustering method that can efficiently assign each snapshot to the corresponding customer is essential for the system. In order to address the unique challenges in the open checkout-free grocery, we propose an efficient and effective person clustering method. Specifically, we first propose a Crowded Sub-Graph (CSG) to localize the relationship among massive and continuous data streams. CSG is constructed by the proposed Pick-Link-Weight (PLW) strategy, which \textbf{picks} the nodes based on time-space information, \textbf{links} the nodes via trajectory information, and \textbf{weighs} the links by the proposed von Mises-Fisher (vMF) similarity metric. Then, to ensure that the method adapts to the dynamic and unseen person flow, we propose Graph Convolutional Network (GCN) with a simple Nearest Neighbor (NN) strategy to accurately cluster the instances of CSG. GCN is adopted to project the features into low-dimensional separable space, and NN is able to quickly produce a result in this space upon dynamic person flow. The experimental results show that the proposed method outperforms other alternative algorithms in this scenario. In practice, the whole system has been implemented and deployed in several real-world open checkout-free groceries.
CVPR 2019 WAD Challenge on Trajectory Prediction and 3D Perception
Apr 06, 2020

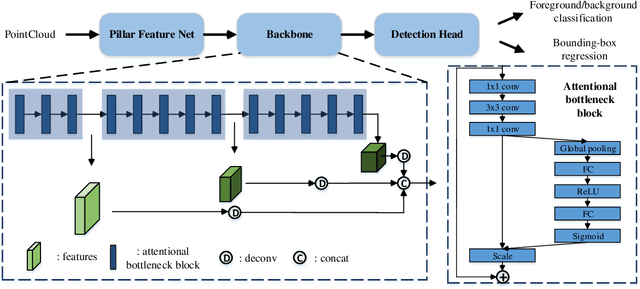
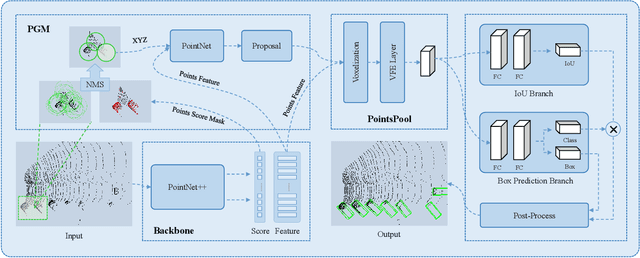
This paper reviews the CVPR 2019 challenge on Autonomous Driving. Baidu's Robotics and Autonomous Driving Lab (RAL) providing 150 minutes labeled Trajectory and 3D Perception dataset including about 80k lidar point cloud and 1000km trajectories for urban traffic. The challenge has two tasks in (1) Trajectory Prediction and (2) 3D Lidar Object Detection. There are more than 200 teams submitted results on Leaderboard and more than 1000 participants attended the workshop.
Teacher-Students Knowledge Distillation for Siamese Trackers
Jul 24, 2019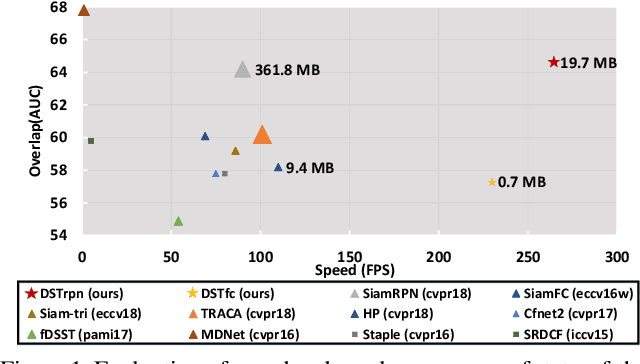
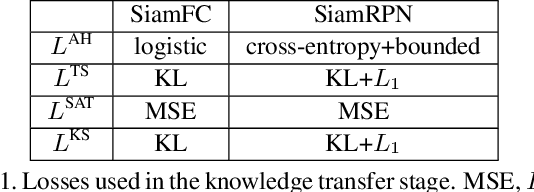
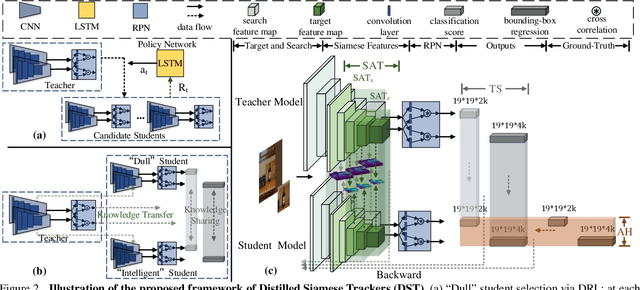

With the development of Siamese network based trackers, a variety of techniques have been fused into this framework for real-time object tracking. However, Siamese trackers suffer from the dilemma between high memory cost and strict constraints on memory budget for practical applications. In this paper, we propose a novel distilled Siamese tracker framework to learn small, fast yet accurate trackers (students), which can capture critical knowledge from large Siamese trackers (teachers) by a teacher-students knowledge distillation model. This model is intuitively inspired by a one teacher vs multi-students learning mechanism, which is the most usual teaching method in the school. In particular, it contains a single teacher-student distillation model and a student-student knowledge sharing mechanism. The first one is designed by a tracking-specific distillation strategy to transfer knowledge from teacher to students. The second one is applied for mutual learning between students to enable more in-depth knowledge understanding. Moreover, to demonstrate its generality and effectiveness, we conduct theoretical analysis and extensive empirical evaluations on two Siamese trackers, on several popular tracking benchmarks. The results show that the distilled trackers achieve compression rates of 13$\times$--18$\times$, while maintaining the same or even slightly improved tracking accuracy.