 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIHE: Linguistic Instance-Split Hyperbolic-Euclidean Framework for Generalized Weakly-Supervised Referring Expression Comprehension
Nov 15, 2025



Existing Weakly-Supervised Referring Expression Comprehension (WREC) methods, while effective, are fundamentally limited by a one-to-one mapping assumption, hindering their ability to handle expressions corresponding to zero or multiple targets in realistic scenarios. To bridge this gap, we introduce the Weakly-Supervised Generalized Referring Expression Comprehension task (WGREC), a more practical paradigm that handles expressions with variable numbers of referents. However, extending WREC to WGREC presents two fundamental challenges: supervisory signal ambiguity, where weak image-level supervision is insufficient for training a model to infer the correct number and identity of referents, and semantic representation collapse, where standard Euclidean similarity forces hierarchically-related concepts into non-discriminative clusters, blurring categorical boundaries. To tackle these challenges, we propose a novel WGREC framework named Linguistic Instance-Split Hyperbolic-Euclidean (LIHE), which operates in two stages. The first stage, Referential Decoupling, predicts the number of target objects and decomposes the complex expression into simpler sub-expressions. The second stage, Referent Grounding, then localizes these sub-expressions using HEMix, our innovative hybrid similarity module that synergistically combines the precise alignment capabilities of Euclidean proximity with the hierarchical modeling strengths of hyperbolic geometry. This hybrid approach effectively prevents semantic collapse while preserving fine-grained distinctions between related concepts. Extensive experiments demonstrate LIHE establishes the first effective weakly supervised WGREC baseline on gRefCOCO and Ref-ZOM, while HEMix achieves consistent improvements on standard REC benchmarks, improving IoU@0.5 by up to 2.5\%. The code is available at https://anonymous.4open.science/r/LIHE.
WeakMCN: Multi-task Collaborative Network for Weakly Supervised Referring Expression Comprehension and Segmentation
May 24, 2025Weakly supervised referring expression comprehension(WREC) and segmentation(WRES) aim to learn object grounding based on a given expression using weak supervision signals like image-text pairs. While these tasks have traditionally been modeled separately, we argue that they can benefit from joint learning in a multi-task framework. To this end, we propose WeakMCN, a novel multi-task collaborative network that effectively combines WREC and WRES with a dual-branch architecture. Specifically, the WREC branch is formulated as anchor-based contrastive learning, which also acts as a teacher to supervise the WRES branch. In WeakMCN, we propose two innovative designs to facilitate multi-task collaboration, namely Dynamic Visual Feature Enhancement(DVFE) and Collaborative Consistency Module(CCM). DVFE dynamically combines various pre-trained visual knowledge to meet different task requirements, while CCM promotes cross-task consistency from the perspective of optimization. Extensive experimental results on three popular REC and RES benchmarks, i.e., RefCOCO, RefCOCO+, and RefCOCOg, consistently demonstrate performance gains of WeakMCN over state-of-the-art single-task alternatives, e.g., up to 3.91% and 13.11% on RefCOCO for WREC and WRES tasks, respectively. Furthermore, experiments also validate the strong generalization ability of WeakMCN in both semi-supervised REC and RES settings against existing methods, e.g., +8.94% for semi-REC and +7.71% for semi-RES on 1% RefCOCO. The code is publicly available at https://github.com/MRUIL/WeakMCN.
UADet: A Remarkably Simple Yet Effective Uncertainty-Aware Open-Set Object Detection Framework
Dec 12, 2024



We tackle the challenging problem of Open-Set Object Detection (OSOD), which aims to detect both known and unknown objects in unlabelled images. The main difficulty arises from the absence of supervision for these unknown classes, making it challenging to distinguish them from the background. Existing OSOD detectors either fail to properly exploit or inadequately leverage the abundant unlabeled unknown objects in training data, restricting their performance. To address these limitations, we propose UADet, an Uncertainty-Aware Open-Set Object Detector that considers appearance and geometric uncertainty. By integrating these uncertainty measures, UADet effectively reduces the number of unannotated instances incorrectly utilized or omitted by previous methods. Extensive experiments on OSOD benchmarks demonstrate that UADet substantially outperforms previous state-of-the-art (SOTA) methods in detecting both known and unknown objects, achieving a 1.8x improvement in unknown recall while maintaining high performance on known classes. When extended to Open World Object Detection (OWOD), our method shows significant advantages over the current SOTA method, with average improvements of 13.8% and 6.9% in unknown recall on M-OWODB and S-OWODB benchmarks, respectively. Extensive results validate the effectiveness of our uncertainty-aware approach across different open-set scenarios.
PRA-Net: Point Relation-Aware Network for 3D Point Cloud Analysis
Dec 09, 2021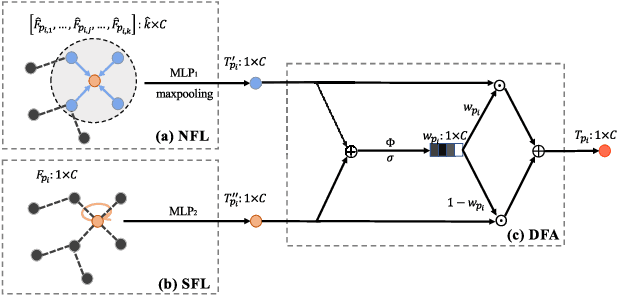
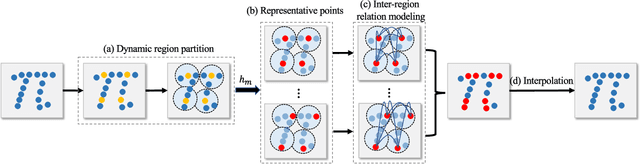
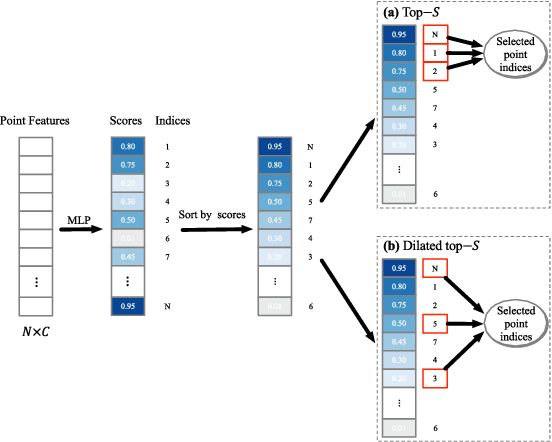

Learning intra-region contexts and inter-region relations are two effective strategies to strengthen feature representations for point cloud analysis. However, unifying the two strategies for point cloud representation is not fully emphasized in existing methods. To this end, we propose a novel framework named Point Relation-Aware Network (PRA-Net), which is composed of an Intra-region Structure Learning (ISL) module and an Inter-region Relation Learning (IRL) module. The ISL module can dynamically integrate the local structural information into the point features, while the IRL module captures inter-region relations adaptively and efficiently via a differentiable region partition scheme and a representative point-based strategy. Extensive experiments on several 3D benchmarks covering shape classification, keypoint estimation, and part segmentation have verified the effectiveness and the generalization ability of PRA-Net. Code will be available at https://github.com/XiwuChen/PRA-Net .
* 13 pages
CAP-Net: Correspondence-Aware Point-view Fusion Network for 3D Shape Analysis
Sep 03, 2021
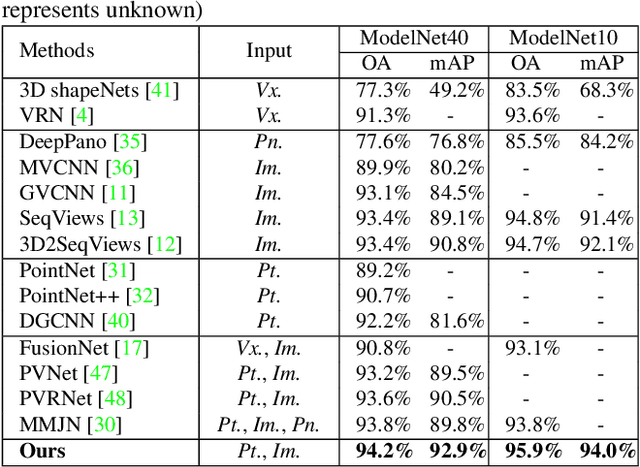
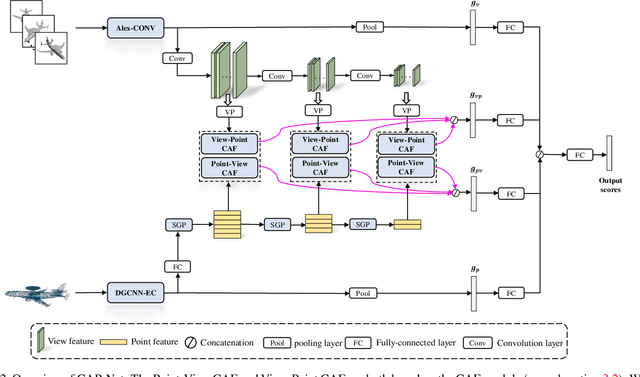

Learning 3D representations by fusing point cloud and multi-view data has been proven to be fairly effective. While prior works typically focus on exploiting global features of the two modalities, in this paper we argue that more discriminative features can be derived by modeling "where to fuse". To investigate this, we propose a novel Correspondence-Aware Point-view Fusion Net (CAPNet). The core element of CAP-Net is a module named Correspondence-Aware Fusion (CAF) which integrates the local features of the two modalities based on their correspondence scores. We further propose to filter out correspondence scores with low values to obtain salient local correspondences, which reduces redundancy for the fusion process. In our CAP-Net, we utilize the CAF modules to fuse the multi-scale features of the two modalities both bidirectionally and hierarchically in order to obtain more informative features. Comprehensive evaluations on popular 3D shape benchmarks covering 3D object classification and retrieval show the superiority of the proposed framework.