 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP-Net: Correspondence-Aware Point-view Fusion Network for 3D Shape Analysis
Paper and Code
Sep 03, 2021
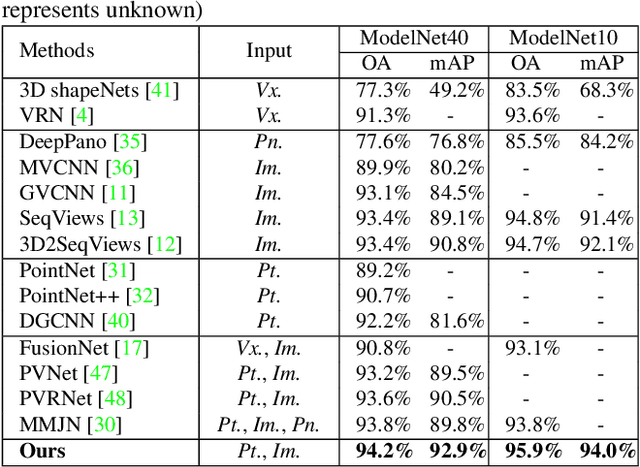
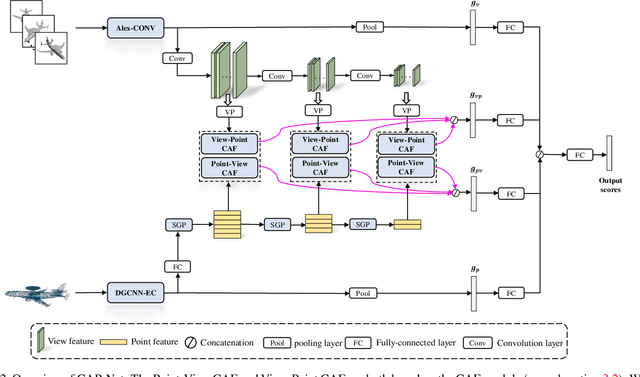

Learning 3D representations by fusing point cloud and multi-view data has been proven to be fairly effective. While prior works typically focus on exploiting global features of the two modalities, in this paper we argue that more discriminative features can be derived by modeling "where to fuse". To investigate this, we propose a novel Correspondence-Aware Point-view Fusion Net (CAPNet). The core element of CAP-Net is a module named Correspondence-Aware Fusion (CAF) which integrates the local features of the two modalities based on their correspondence scores. We further propose to filter out correspondence scores with low values to obtain salient local correspondences, which reduces redundancy for the fusion process. In our CAP-Net, we utilize the CAF modules to fuse the multi-scale features of the two modalities both bidirectionally and hierarchically in order to obtain more informative features. Comprehensive evaluations on popular 3D shape benchmarks covering 3D object classification and retrieval show the superiority of the proposed framework.