 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Test-time Inference for Visual Grounding
Jan 20, 2026Visual grounding is an essential capability of Visual Language Models (VLMs) to understand the real physical world. Previous state-of-the-art grounding visual language models usually have large model sizes, making them heavy for deployment and slow for inference. However, we notice that the sizes of visual encoders are nearly the same for small and large VLMs and the major difference is the sizes of the language models. Small VLMs fall behind larger VLMs in grounding because of the difference in language understanding capability rather than visual information handling. To mitigate the gap, we introduce 'Efficient visual Grounding language Models' (EGM): a method to scale the test-time computation (#generated tokens). Scaling the test-time computation of a small model is deployment-friendly, and yields better end-to-end latency as the cost of each token is much cheaper compared to directly running a large model. On the RefCOCO benchmark, our EGM-Qwen3-VL-8B demonstrates 91.4 IoU with an average of 737ms (5.9x faster) latency while Qwen3-VL-235B demands 4,320ms to achieve 90.5 IoU. To validate our approach's generality, we further set up a new amodal grounding setting that requires the model to predict both the visible and occluded parts of the objects. Experiments show our method can consistently and significantly improve the vanilla grounding and amodal grounding capabilities of small models to be on par with or outperform the larger models, thereby improving the efficiency for visual grounding.
Inferring Dynamic Physical Properties from Video Foundation Models
Oct 02, 2025We study the task of predicting dynamic physical properties from videos. More specifically, we consider physical properties that require temporal information to be inferred: elasticity of a bouncing object, viscosity of a flowing liquid, and dynamic friction of an object sliding on a surface. To this end, we make the following contributions: (i) We collect a new video dataset for each physical property, consisting of synthetic training and testing splits, as well as a real split for real world evaluation. (ii) We explore three ways to infer the physical property from videos: (a) an oracle method where we supply the visual cues that intrinsically reflect the property using classical computer vision techniques; (b) a simple read out mechanism using a visual prompt and trainable prompt vector for cross-attention on pre-trained video generative and self-supervised models; and (c) prompt strategies for Multi-modal Large Language Models (MLLMs). (iii) We show that video foundation models trained in a generative or self-supervised manner achieve a similar performance, though behind that of the oracle, and MLLMs are currently inferior to the other models, though their performance can be improved through suitable prompting.
ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
Feb 21, 2025The objective in this paper is to improve the performance of text-to-image retrieval. To this end, we introduce a new framework that can boost the performance of large-scale pre-trained vision-language models, so that they can be used for text-to-image re-ranking. The approach, Enhanced Language-Image Pre-training (ELIP), uses the text query to predict a set of visual prompts to condition the ViT image encoding. ELIP can easily be applied to the commonly used CLIP/SigLIP and the state-of-the-art BLIP-2 architectures. To train the architecture with limited computing resources, we develop a 'student friendly' best practice involving global hard sample mining, and selection and curation of a large-scale dataset. On the evaluation side, we set up two new out-of-distribution benchmarks, Occluded COCO and ImageNet-R, to assess the zero-shot generalisation of the models to different domains. Benefiting from the novel architecture and data curation, experiments show our enhanced network significantly boosts CLIP/SigLIP performance and outperforms the state-of-the-art BLIP-2 model on text-to-image retrieval.
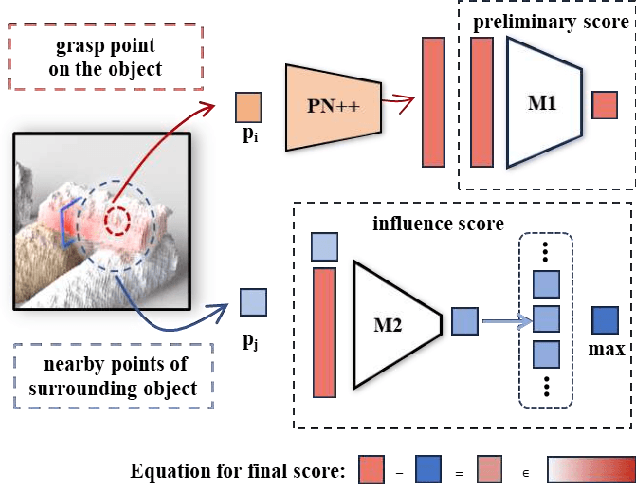
TARGO: Benchmarking Target-driven Object Grasping under Occlusions
Jul 08, 2024Recent advances in predicting 6D grasp poses from a single depth image have led to promising performance in robotic grasping. However, previous grasping models face challenges in cluttered environments where nearby objects impact the target object's grasp. In this paper, we first establish a new benchmark dataset for TARget-driven Grasping under Occlusions, named TARGO. We make the following contributions: 1) We are the first to study the occlusion level of grasping. 2) We set up an evaluation benchmark consisting of large-scale synthetic data and part of real-world data, and we evaluated five grasp models and found that even the current SOTA model suffers when the occlusion level increases, leaving grasping under occlusion still a challenge. 3) We also generate a large-scale training dataset via a scalable pipeline, which can be used to boost the performance of grasping under occlusion and generalized to the real world. 4) We further propose a transformer-based grasping model involving a shape completion module, termed TARGO-Net, which performs most robustly as occlusion increases. Our benchmark dataset can be found at https://TARGO-benchmark.github.io/.
InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment
Jun 07, 2024



Enabling robots to navigate following diverse language instructions in unexplored environments is an attractive goal for human-robot interaction. However, this goal is challenging because different navigation tasks require different strategies. The scarcity of instruction navigation data hinders training an instruction navigation model with varied strategies. Therefore, previous methods are all constrained to one specific type of navigation instruction. In this work, we propose InstructNav, a generic instruction navigation system. InstructNav makes the first endeavor to handle various instruction navigation tasks without any navigation training or pre-built maps. To reach this goal, we introduce Dynamic Chain-of-Navigation (DCoN) to unify the planning process for different types of navigation instructions. Furthermore, we propose Multi-sourced Value Maps to model key elements in instruction navigation so that linguistic DCoN planning can be converted into robot actionable trajectories. With InstructNav, we complete the R2R-CE task in a zero-shot way for the first time and outperform many task-training methods. Besides, InstructNav also surpasses the previous SOTA method by 10.48% on the zero-shot Habitat ObjNav and by 86.34% on demand-driven navigation DDN. Real robot experiments on diverse indoor scenes further demonstrate our method's robustness in coping with the environment and instruction variations.
Broadcasting Support Relations Recursively from Local Dynamics for Object Retrieval in Clutters
Jun 04, 2024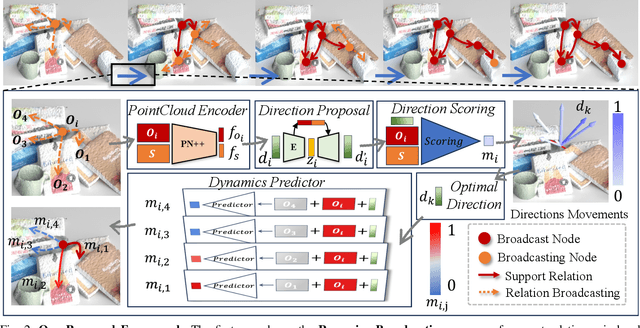
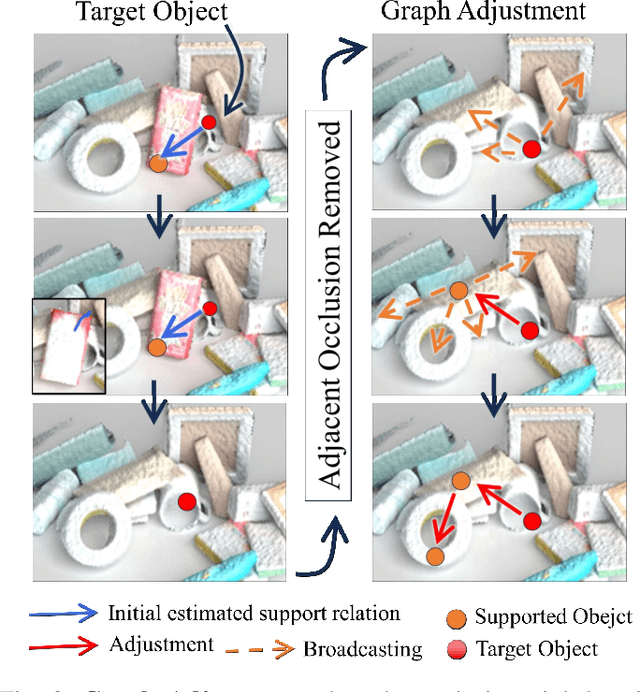

In our daily life, cluttered objects are everywhere, from scattered stationery and books cluttering the table to bowls and plates filling the kitchen sink. Retrieving a target object from clutters is an essential while challenging skill for robots, for the difficulty of safely manipulating an object without disturbing others, which requires the robot to plan a manipulation sequence and first move away a few other objects supported by the target object step by step. However, due to the diversity of object configurations (e.g., categories, geometries, locations and poses) and their combinations in clutters, it is difficult for a robot to accurately infer the support relations between objects faraway with various objects in between. In this paper, we study retrieving objects in complicated clutters via a novel method of recursively broadcasting the accurate local dynamics to build a support relation graph of the whole scene, which largely reduces the complexity of the support relation inference and improves the accuracy. Experiments in both simulation and the real world demonstrate the efficiency and effectiveness of our method.
Amodal Ground Truth and Completion in the Wild
Dec 28, 2023The problem we study in this paper is amodal image segmentation: predicting entire object segmentation masks including both visible and invisible (occluded) parts. In previous work, the amodal segmentation ground truth on real images is usually predicted by manual annotaton and thus is subjective. In contrast, we use 3D data to establish an automatic pipeline to determine authentic ground truth amodal masks for partially occluded objects in real images. This pipeline is used to construct an amodal completion evaluation benchmark, MP3D-Amodal, consisting of a variety of object categories and labels. To better handle the amodal completion task in the wild, we explore two architecture variants: a two-stage model that first infers the occluder, followed by amodal mask completion; and a one-stage model that exploits the representation power of Stable Diffusion for amodal segmentation across many categories. Without bells and whistles, our method achieves a new state-of-the-art performance on Amodal segmentation datasets that cover a large variety of objects, including COCOA and our new MP3D-Amodal dataset. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/amodal/.
What Does Stable Diffusion Know about the 3D Scene?
Oct 10, 2023



Recent advances in generative models like Stable Diffusion enable the generation of highly photo-realistic images. Our objective in this paper is to probe the diffusion network to determine to what extent it 'understands' different properties of the 3D scene depicted in an image. To this end, we make the following contributions: (i) We introduce a protocol to evaluate whether a network models a number of physical 'properties' of the 3D scene by probing for explicit features that represent these properties. The probes are applied on datasets of real images with annotations for the property. (ii) We apply this protocol to properties covering scene geometry, scene material, support relations, lighting, and view dependent measures. (iii) We find that Stable Diffusion is good at a number of properties including scene geometry, support relations, shadows and depth, but less performant for occlusion. (iv) We also apply the probes to other models trained at large-scale, including DINO and CLIP, and find their performance inferior to that of Stable Diffusion.
Learning Environment-Aware Affordance for 3D Articulated Object Manipulation under Occlusions
Sep 25, 2023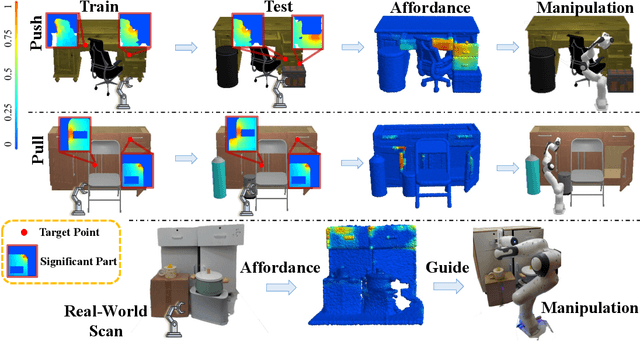
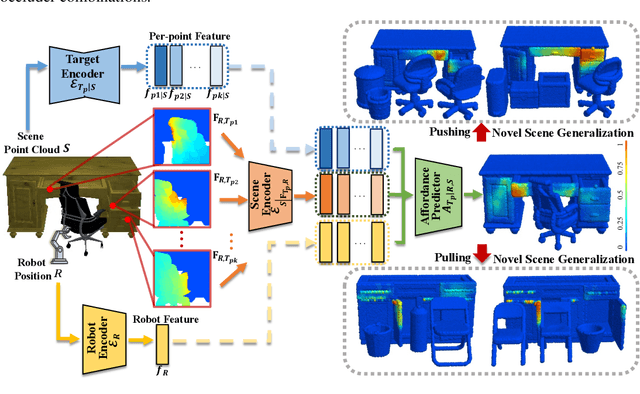

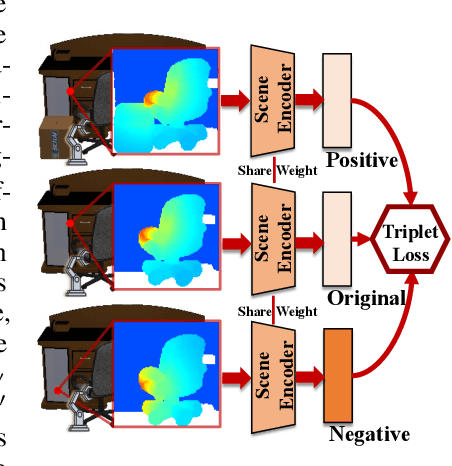
Perceiving and manipulating 3D articulated objects in diverse environments is essential for home-assistant robots. Recent studies have shown that point-level affordance provides actionable priors for downstream manipulation tasks. However, existing works primarily focus on single-object scenarios with homogeneous agents, overlooking the realistic constraints imposed by the environment and the agent's morphology, e.g., occlusions and physical limitations. In this paper, we propose an environment-aware affordance framework that incorporates both object-level actionable priors and environment constraints. Unlike object-centric affordance approaches, learning environment-aware affordance faces the challenge of combinatorial explosion due to the complexity of various occlusions, characterized by their quantities, geometries, positions and poses. To address this and enhance data efficiency, we introduce a novel contrastive affordance learning framework capable of training on scenes containing a single occluder and generalizing to scenes with complex occluder combinations. Experiments demonstrate the effectiveness of our proposed approach in learning affordance considering environment constraints. Project page at https://chengkaiacademycity.github.io/EnvAwareAfford/
Score-PA: Score-based 3D Part Assembly
Sep 08, 2023Autonomous 3D part assembly is a challenging task in the areas of robotics and 3D computer vision. This task aims to assemble individual components into a complete shape without relying on predefined instructions. In this paper, we formulate this task from a novel generative perspective, introducing the Score-based 3D Part Assembly framework (Score-PA) for 3D part assembly. Knowing that score-based methods are typically time-consuming during the inference stage. To address this issue, we introduce a novel algorithm called the Fast Predictor-Corrector Sampler (FPC) that accelerates the sampling process within the framework. We employ various metrics to assess assembly quality and diversity, and our evaluation results demonstrate that our algorithm outperforms existing state-of-the-art approaches. We release our code at https://github.com/J-F-Cheng/Score-PA_Score-based-3D-Part-Assembly.