 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUALVISION: RGB-Infrared Multimodal Large Language Models for Robust Visual Reasoning
Apr 20, 2026Multimodal large language models (MLLMs) have achieved impressive performance on visual perception and reasoning tasks with RGB imagery, yet they remain fragile under common degradations, such as fog, blur, or low-light conditions. Infrared (IR) imaging, a well-established complement to RGB, offers inherent robustness in these conditions, but its integration into MLLMs remains underexplored. To bridge this gap, we propose DUALVISION, a lightweight fusion module that efficiently incorporates IR-RGB information into MLLMs via patch-level localized cross-attention. To support training and evaluation and to facilitate future research, we also introduce DV-204K, a dataset of ~25K publicly available aligned IR-RGB image pairs with 204K modality-specific QA annotations, and DV-500, a benchmark of 500 IR-RGB image pairs with 500 QA pairs designed for evaluating cross-modal reasoning. Leveraging these datasets, we benchmark both open- and closed-source MLLMs and demonstrate that DUALVISION delivers strong empirical performance under a wide range of visual degradations. Our code and dataset are available at https://abrarmajeedi.github.io/dualvision.
RMBench: Memory-Dependent Robotic Manipulation Benchmark with Insights into Policy Design
Mar 01, 2026Robotic manipulation policies have made rapid progress in recent years, yet most existing approaches give limited consideration to memory capabilities. Consequently, they struggle to solve tasks that require reasoning over historical observations and maintaining task-relevant information over time, which are common requirements in real-world manipulation scenarios. Although several memory-aware policies have been proposed, systematic evaluation of memory-dependent manipulation remains underexplored, and the relationship between architectural design choices and memory performance is still not well understood. To address this gap, we introduce RMBench, a simulation benchmark comprising 9 manipulation tasks that span multiple levels of memory complexity, enabling systematic evaluation of policy memory capabilities. We further propose Mem-0, a modular manipulation policy with explicit memory components designed to support controlled ablation studies. Through extensive simulation and real-world experiments, we identify memory-related limitations in existing policies and provide empirical insights into how architectural design choices influence memory performance. The website is available at https://rmbench.github.io/.
User-Centric Object Navigation: A Benchmark with Integrated User Habits for Personalized Embodied Object Search
Feb 06, 2026In the evolving field of robotics, the challenge of Object Navigation (ON) in household environments has attracted significant interest. Existing ON benchmarks typically place objects in locations guided by general scene priors, without accounting for the specific placement habits of individual users. This omission limits the adaptability of navigation agents in personalized household environments. To address this, we introduce User-centric Object Navigation (UcON), a new benchmark that incorporates user-specific object placement habits, referred to as user habits. This benchmark requires agents to leverage these user habits for more informed decision-making during navigation. UcON encompasses approximately 22,600 user habits across 489 object categories. UcON is, to our knowledge, the first benchmark that explicitly formalizes and evaluates habit-conditioned object navigation at scale and covers the widest range of target object categories. Additionally, we propose a habit retrieval module to extract and utilize habits related to target objects, enabling agents to infer their likely locations more effectively. Experimental results demonstrate that current SOTA methods exhibit substantial performance degradation under habit-driven object placement, while integrating user habits consistently improves success rates. Code is available at https://github.com/whcpumpkin/User-Centric-Object-Navigation.
SimpleCall: A Lightweight Image Restoration Agent in Label-Free Environments with MLLM Perceptual Feedback
Dec 21, 2025Complex image restoration aims to recover high-quality images from inputs affected by multiple degradations such as blur, noise, rain, and compression artifacts. Recent restoration agents, powered by vision-language models and large language models, offer promising restoration capabilities but suffer from significant efficiency bottlenecks due to reflection, rollback, and iterative tool searching. Moreover, their performance heavily depends on degradation recognition models that require extensive annotations for training, limiting their applicability in label-free environments. To address these limitations, we propose a policy optimization-based restoration framework that learns an lightweight agent to determine tool-calling sequences. The agent operates in a sequential decision process, selecting the most appropriate restoration operation at each step to maximize final image quality. To enable training within label-free environments, we introduce a novel reward mechanism driven by multimodal large language models, which act as human-aligned evaluator and provide perceptual feedback for policy improvement. Once trained, our agent executes a deterministic restoration plans without redundant tool invocations, significantly accelerating inference while maintaining high restoration quality. Extensive experiments show that despite using no supervision, our method matches SOTA performance on full-reference metrics and surpasses existing approaches on no-reference metrics across diverse degradation scenarios.
MO-DDN: A Coarse-to-Fine Attribute-based Exploration Agent for Multi-object Demand-driven Navigation
Oct 04, 2024The process of satisfying daily demands is a fundamental aspect of humans' daily lives. With the advancement of embodied AI, robots are increasingly capable of satisfying human demands. Demand-driven navigation (DDN) is a task in which an agent must locate an object to satisfy a specified demand instruction, such as ``I am thirsty.'' The previous study typically assumes that each demand instruction requires only one object to be fulfilled and does not consider individual preferences. However, the realistic human demand may involve multiple objects. In this paper, we introduce the Multi-object Demand-driven Navigation (MO-DDN) benchmark, which addresses these nuanced aspects, including multi-object search and personal preferences, thus making the MO-DDN task more reflective of real-life scenarios compared to DDN. Building upon previous work, we employ the concept of ``attribute'' to tackle this new task. However, instead of solely relying on attribute features in an end-to-end manner like DDN, we propose a modular method that involves constructing a coarse-to-fine attribute-based exploration agent (C2FAgent). Our experimental results illustrate that this coarse-to-fine exploration strategy capitalizes on the advantages of attributes at various decision-making levels, resulting in superior performance compared to baseline methods. Code and video can be found at https://sites.google.com/view/moddn.
Data Pruning via Separability, Integrity, and Model Uncertainty-Aware Importance Sampling
Sep 20, 2024



This paper improves upon existing data pruning methods for image classification by introducing a novel pruning metric and pruning procedure based on importance sampling. The proposed pruning metric explicitly accounts for data separability, data integrity, and model uncertainty, while the sampling procedure is adaptive to the pruning ratio and considers both intra-class and inter-class separation to further enhance the effectiveness of pruning. Furthermore, the sampling method can readily be applied to other pruning metrics to improve their performance. Overall, the proposed approach scales well to high pruning ratio and generalizes better across different classification models, as demonstrated by experiments on four benchmark datasets, including the fine-grained classification scenario.
InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment
Jun 07, 2024



Enabling robots to navigate following diverse language instructions in unexplored environments is an attractive goal for human-robot interaction. However, this goal is challenging because different navigation tasks require different strategies. The scarcity of instruction navigation data hinders training an instruction navigation model with varied strategies. Therefore, previous methods are all constrained to one specific type of navigation instruction. In this work, we propose InstructNav, a generic instruction navigation system. InstructNav makes the first endeavor to handle various instruction navigation tasks without any navigation training or pre-built maps. To reach this goal, we introduce Dynamic Chain-of-Navigation (DCoN) to unify the planning process for different types of navigation instructions. Furthermore, we propose Multi-sourced Value Maps to model key elements in instruction navigation so that linguistic DCoN planning can be converted into robot actionable trajectories. With InstructNav, we complete the R2R-CE task in a zero-shot way for the first time and outperform many task-training methods. Besides, InstructNav also surpasses the previous SOTA method by 10.48% on the zero-shot Habitat ObjNav and by 86.34% on demand-driven navigation DDN. Real robot experiments on diverse indoor scenes further demonstrate our method's robustness in coping with the environment and instruction variations.
Find What You Want: Learning Demand-conditioned Object Attribute Space for Demand-driven Navigation
Sep 15, 2023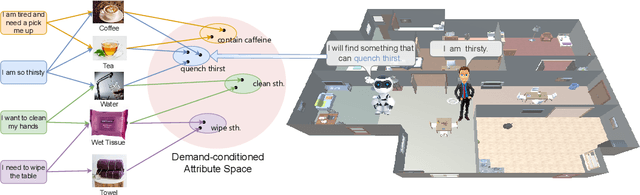
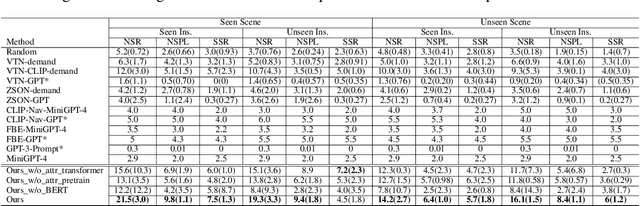
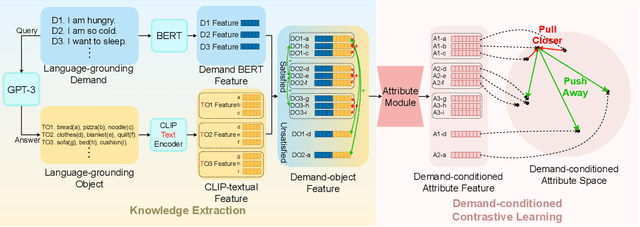
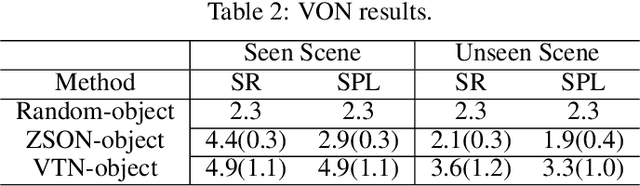
The task of Visual Object Navigation (VON) involves an agent's ability to locate a particular object within a given scene. In order to successfully accomplish the VON task, two essential conditions must be fulfilled:1) the user must know the name of the desired object; and 2) the user-specified object must actually be present within the scene. To meet these conditions, a simulator can incorporate pre-defined object names and positions into the metadata of the scene. However, in real-world scenarios, it is often challenging to ensure that these conditions are always met. Human in an unfamiliar environment may not know which objects are present in the scene, or they may mistakenly specify an object that is not actually present. Nevertheless, despite these challenges, human may still have a demand for an object, which could potentially be fulfilled by other objects present within the scene in an equivalent manner. Hence, we propose Demand-driven Navigation (DDN), which leverages the user's demand as the task instruction and prompts the agent to find the object matches the specified demand. DDN aims to relax the stringent conditions of VON by focusing on fulfilling the user's demand rather than relying solely on predefined object categories or names. We propose a method first acquire textual attribute features of objects by extracting common knowledge from a large language model. These textual attribute features are subsequently aligned with visual attribute features using Contrastive Language-Image Pre-training (CLIP). By incorporating the visual attribute features as prior knowledge, we enhance the navigation process. Experiments on AI2Thor with the ProcThor dataset demonstrate the visual attribute features improve the agent's navigation performance and outperform the baseline methods commonly used in VON.
Lightweight Delivery Detection on Doorbell Cameras
May 13, 2023
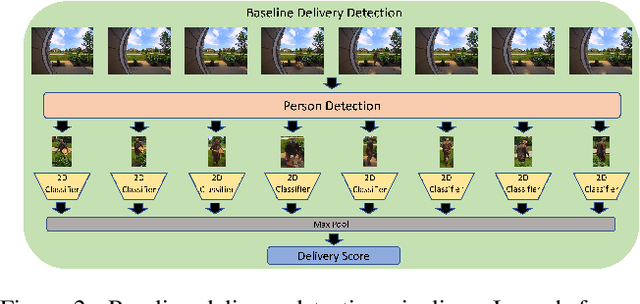
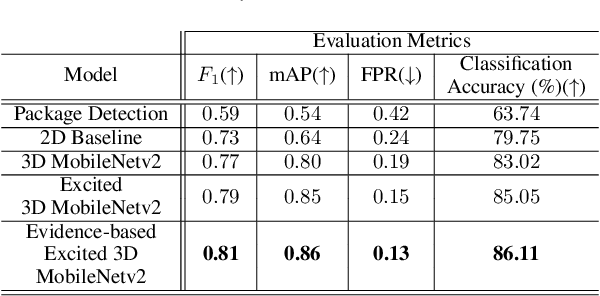

Despite recent advances in video-based action recognition and robust spatio-temporal modeling, most of the proposed approaches rely on the abundance of computational resources to afford running huge and computation-intensive convolutional or transformer-based neural networks to obtain satisfactory results. This limits the deployment of such models on edge devices with limited power and computing resources. In this work we investigate an important smart home application, video based delivery detection, and present a simple and lightweight pipeline for this task that can run on resource-constrained doorbell cameras. Our proposed pipeline relies on motion cues to generate a set of coarse activity proposals followed by their classification with a mobile-friendly 3DCNN network. For training we design a novel semi-supervised attention module that helps the network to learn robust spatio-temporal features and adopt an evidence-based optimization objective that allows for quantifying the uncertainty of predictions made by the network. Experimental results on our curated delivery dataset shows the significant effectiveness of our pipeline compared to alternatives and highlights the benefits of our training phase novelties to achieve free and considerable inference-time performance gains.
Learning Semantic-Agnostic and Spatial-Aware Representation for Generalizable Visual-Audio Navigation
Apr 21, 2023



Visual-audio navigation (VAN) is attracting more and more attention from the robotic community due to its broad applications, \emph{e.g.}, household robots and rescue robots. In this task, an embodied agent must search for and navigate to the sound source with egocentric visual and audio observations. However, the existing methods are limited in two aspects: 1) poor generalization to unheard sound categories; 2) sample inefficient in training. Focusing on these two problems, we propose a brain-inspired plug-and-play method to learn a semantic-agnostic and spatial-aware representation for generalizable visual-audio navigation. We meticulously design two auxiliary tasks for respectively accelerating learning representations with the above-desired characteristics. With these two auxiliary tasks, the agent learns a spatially-correlated representation of visual and audio inputs that can be applied to work on environments with novel sounds and maps. Experiment results on realistic 3D scenes (Replica and Matterport3D) demonstrate that our method achieves better generalization performance when zero-shot transferred to scenes with unseen maps and unheard sound categories.