 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomer Sentiment Analysis using Weak Supervision for Customer-Agent Chat
Nov 30, 2021



Prior work on sentiment analysis using weak supervision primarily focuses on different reviews such as movies (IMDB), restaurants (Yelp), products (Amazon).~One under-explored field in this regard is customer chat data for a customer-agent chat in customer support due to the lack of availability of free public data. Here, we perform sentiment analysis on customer chat using weak supervision on our in-house dataset. We fine-tune the pre-trained language model (LM) RoBERTa as a sentiment classifier using weak supervision. Our contribution is as follows:1) We show that by using weak sentiment classifiers along with domain-specific lexicon-based rules as Labeling Functions (LF), we can train a fairly accurate customer chat sentiment classifier using weak supervision. 2) We compare the performance of our custom-trained model with off-the-shelf google cloud NLP API for sentiment analysis. We show that by injecting domain-specific knowledge using LFs, even with weak supervision, we can train a model to handle some domain-specific use cases better than off-the-shelf google cloud NLP API. 3) We also present an analysis of how customer sentiment in a chat relates to problem resolution.
Inclusive Speaker Verification with Adaptive thresholding
Nov 10, 2021
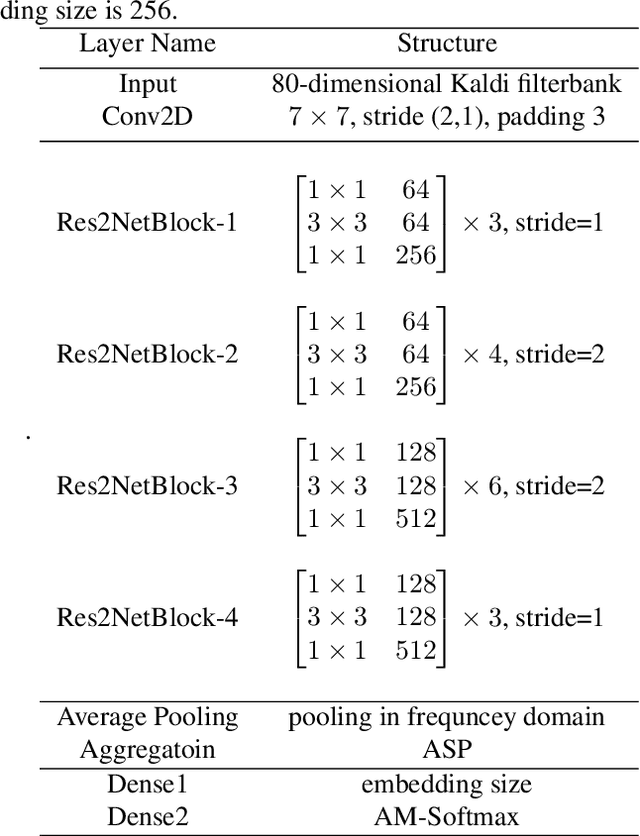
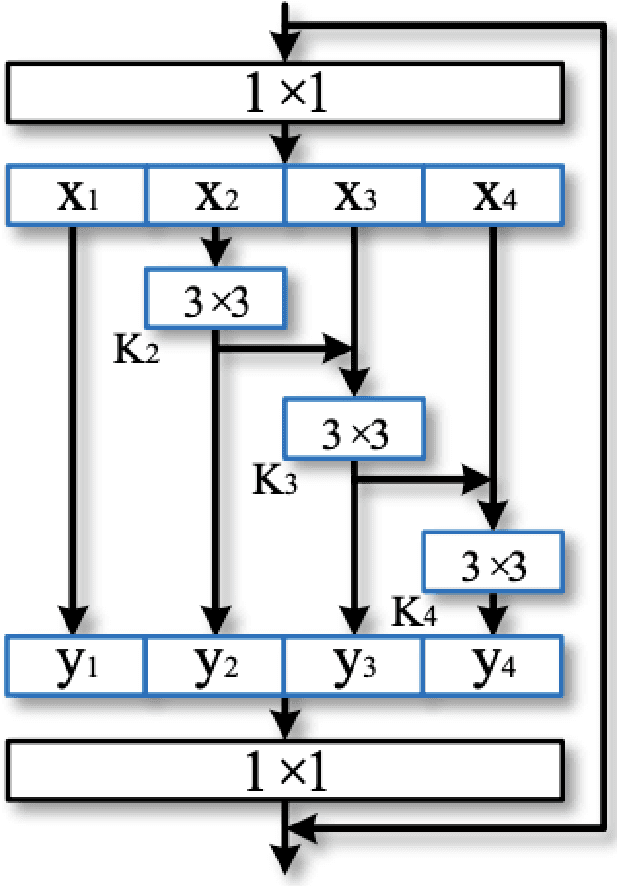

While using a speaker verification (SV) based system in a commercial application, it is important that customers have an inclusive experience irrespective of their gender, age, or ethnicity. In this paper, we analyze the impact of gender and age on SV and find that for a desired common False Acceptance Rate (FAR) across different gender and age groups, the False Rejection Rate (FRR) is different for different gender and age groups. To optimize FRR for all users for a desired FAR, we propose a context (e.g. gender, age) adaptive thresholding framework for SV. The context can be available as prior information for many practical applications. We also propose a concatenated gender/age detection model to algorithmically derive the context in absence of such prior information. We experimentally show that our context-adaptive thresholding method is effective in building a more efficient inclusive SV system. Specifically, we show that we can reduce FRR for specific gender for a desired FAR on the voxceleb1 test set by using gender-specific thresholds. Similar analysis on OGI kids' speech corpus shows that by using an age-specific threshold, we can significantly reduce FRR for certain age groups for desired FAR.