 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Delivery Detection on Doorbell Cameras
May 13, 2023Despite recent advances in video-based action recognition and robust spatio-temporal modeling, most of the proposed approaches rely on the abundance of computational resources to afford running huge and computation-intensive convolutional or transformer-based neural networks to obtain satisfactory results. This limits the deployment of such models on edge devices with limited power and computing resources. In this work we investigate an important smart home application, video based delivery detection, and present a simple and lightweight pipeline for this task that can run on resource-constrained doorbell cameras. Our proposed pipeline relies on motion cues to generate a set of coarse activity proposals followed by their classification with a mobile-friendly 3DCNN network. For training we design a novel semi-supervised attention module that helps the network to learn robust spatio-temporal features and adopt an evidence-based optimization objective that allows for quantifying the uncertainty of predictions made by the network. Experimental results on our curated delivery dataset shows the significant effectiveness of our pipeline compared to alternatives and highlights the benefits of our training phase novelties to achieve free and considerable inference-time performance gains.
Scalable Vehicle Re-Identification via Self-Supervision
May 16, 2022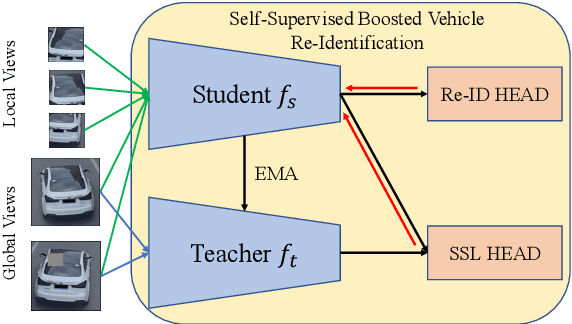
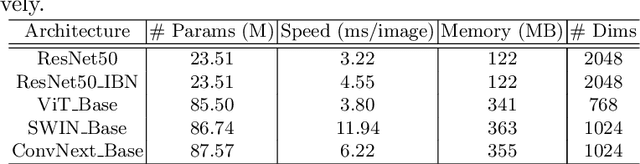


As Computer Vision technologies become more mature for intelligent transportation applications, it is time to ask how efficient and scalable they are for large-scale and real-time deployment. Among these technologies is Vehicle Re-Identification which is one of the key elements in city-scale vehicle analytics systems. Many state-of-the-art solutions for vehicle re-id mostly focus on improving the accuracy on existing re-id benchmarks and often ignore computational complexity. To balance the demands of accuracy and computational efficiency, in this work we propose a simple yet effective hybrid solution empowered by self-supervised training which only uses a single network during inference time and is free of intricate and computation-demanding add-on modules often seen in state-of-the-art approaches. Through extensive experiments, we show our approach, termed Self-Supervised and Boosted VEhicle Re-Identification (SSBVER), is on par with state-of-the-art alternatives in terms of accuracy without introducing any additional overhead during deployment. Additionally we show that our approach, generalizes to different backbone architectures which facilitates various resource constraints and consistently results in a significant accuracy boost.
Scalable and Real-time Multi-Camera Vehicle Detection, Re-Identification, and Tracking
Apr 15, 2022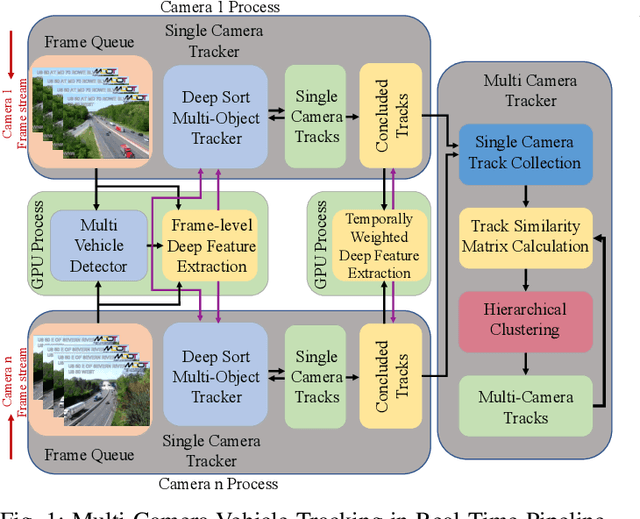

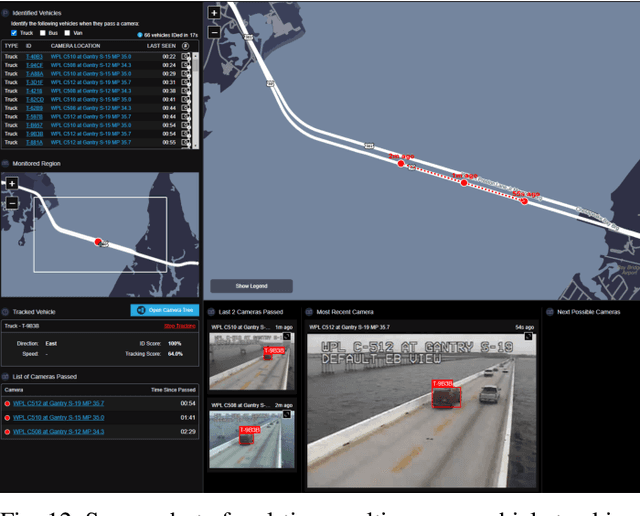
Multi-camera vehicle tracking is one of the most complicated tasks in Computer Vision as it involves distinct tasks including Vehicle Detection, Tracking, and Re-identification. Despite the challenges, multi-camera vehicle tracking has immense potential in transportation applications including speed, volume, origin-destination (O-D), and routing data generation. Several recent works have addressed the multi-camera tracking problem. However, most of the effort has gone towards improving accuracy on high-quality benchmark datasets while disregarding lower camera resolutions, compression artifacts and the overwhelming amount of computational power and time needed to carry out this task on its edge and thus making it prohibitive for large-scale and real-time deployment. Therefore, in this work we shed light on practical issues that should be addressed for the design of a multi-camera tracking system to provide actionable and timely insights. Moreover, we propose a real-time city-scale multi-camera vehicle tracking system that compares favorably to computationally intensive alternatives and handles real-world, low-resolution CCTV instead of idealized and curated video streams. To show its effectiveness, in addition to integration into the Regional Integrated Transportation Information System (RITIS), we participated in the 2021 NVIDIA AI City multi-camera tracking challenge and our method is ranked among the top five performers on the public leaderboard.
Identification of Attack-Specific Signatures in Adversarial Examples
Oct 13, 2021

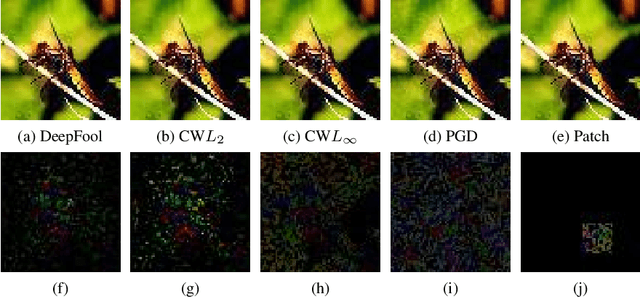
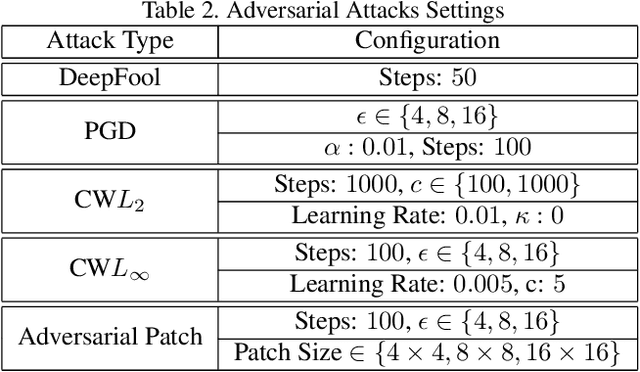
The adversarial attack literature contains a myriad of algorithms for crafting perturbations which yield pathological behavior in neural networks. In many cases, multiple algorithms target the same tasks and even enforce the same constraints. In this work, we show that different attack algorithms produce adversarial examples which are distinct not only in their effectiveness but also in how they qualitatively affect their victims. We begin by demonstrating that one can determine the attack algorithm that crafted an adversarial example. Then, we leverage recent advances in parameter-space saliency maps to show, both visually and quantitatively, that adversarial attack algorithms differ in which parts of the network and image they target. Our findings suggest that prospective adversarial attacks should be compared not only via their success rates at fooling models but also via deeper downstream effects they have on victims.
GANs with Variational Entropy Regularizers: Applications in Mitigating the Mode-Collapse Issue
Sep 24, 2020
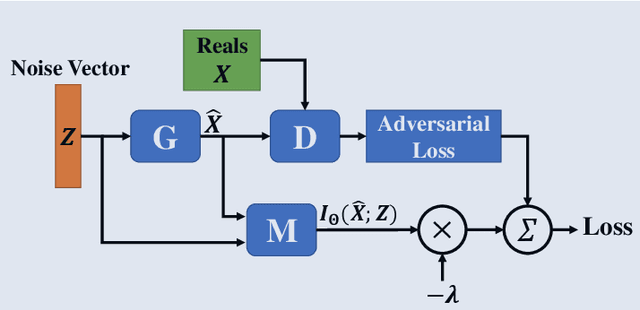
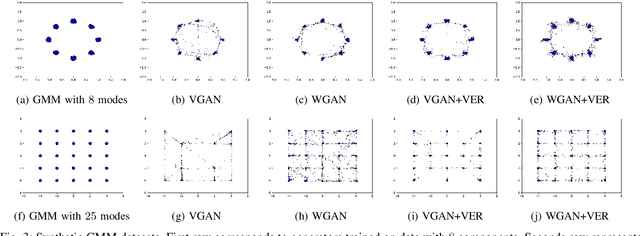
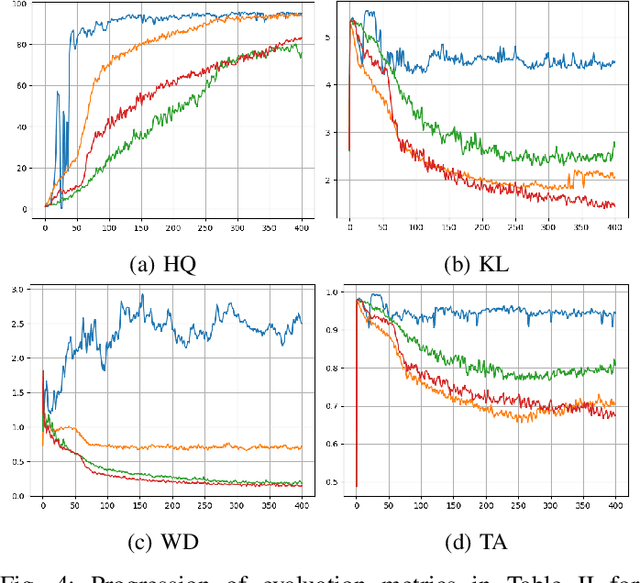
Building on the success of deep learning, Generative Adversarial Networks (GANs) provide a modern approach to learn a probability distribution from observed samples. GANs are often formulated as a zero-sum game between two sets of functions; the generator and the discriminator. Although GANs have shown great potentials in learning complex distributions such as images, they often suffer from the mode collapse issue where the generator fails to capture all existing modes of the input distribution. As a consequence, the diversity of generated samples is lower than that of the observed ones. To tackle this issue, we take an information-theoretic approach and maximize a variational lower bound on the entropy of the generated samples to increase their diversity. We call this approach GANs with Variational Entropy Regularizers (GAN+VER). Existing remedies for the mode collapse issue in GANs can be easily coupled with our proposed variational entropy regularization. Through extensive experimentation on standard benchmark datasets, we show all the existing evaluation metrics highlighting difference of real and generated samples are significantly improved with GAN+VER.
The Devil is in the Details: Self-Supervised Attention for Vehicle Re-Identification
Apr 15, 2020



In recent years, the research community has approached the problem of vehicle re-identification (re-id) with attention-based models, specifically focusing on regions of a vehicle containing discriminative information. These re-id methods rely on expensive key-point labels, part annotations, and additional attributes including vehicle make, model, and color. Given the large number of vehicle re-id datasets with various levels of annotations, strongly-supervised methods are unable to scale across different domains. In this paper, we present Self-supervised Attention for Vehicle Re-identification (SAVER), a novel approach to effectively learn vehicle-specific discriminative features. Through extensive experimentation, we show that SAVER improves upon the state-of-the-art on challenging vehicle re-id benchmarks including Veri-776, VehicleID, Vehicle-1M and Veri-Wild. SAVER demonstrates how proper regularization techniques significantly constrain the vehicle re-id task and help generate robust deep features.
A Dual Path ModelWith Adaptive Attention For Vehicle Re-Identification
May 09, 2019
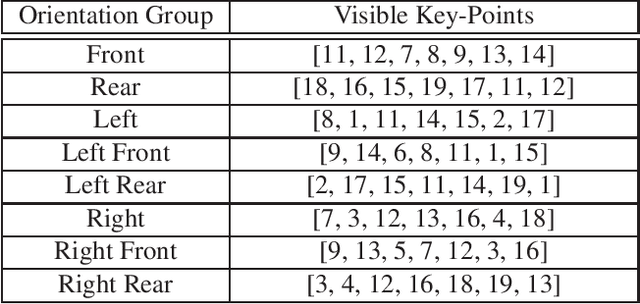
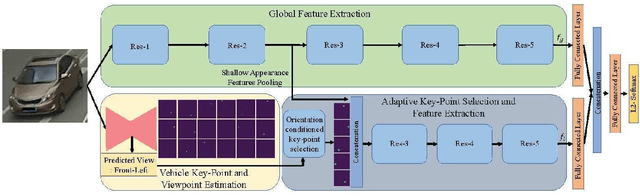

In recent years, attention models have been extensively used for person and vehicle re-identification. Most reidentification methods are designed to focus attention at key-point locations. However, depending on the orientation the contribution of each key-point varies. In this paper, we present a novel dual path adaptive attention model for vehicle re-identification (AAVER). The global appearance path captures macroscopic vehicle features while the orientation conditioned part appearance path learns to capture localized discriminative features by focusing attention to the most informative key-points. Through extensive experimentation, we show that the proposed AAVER method is able to accurately re-identify vehicles in unconstrained scenarios, yielding state of the art results on the challenging dataset VeRi-776. As a byproduct, the proposed system is also able to accurately predict vehicle key-points and shows an improvement of more than 7% over state of the art.