 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaMem: Online Dynamic Spatio-Semantic Memory for Open World Mobile Manipulation
Nov 07, 2024

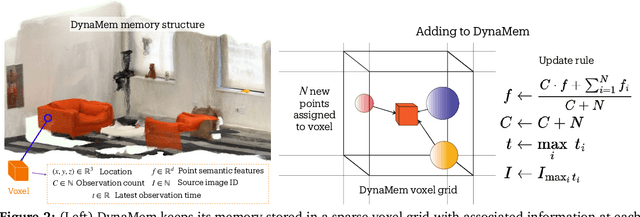
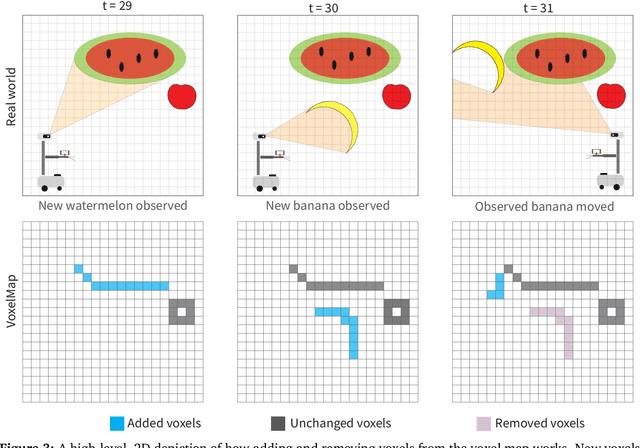
Significant progress has been made in open-vocabulary mobile manipulation, where the goal is for a robot to perform tasks in any environment given a natural language description. However, most current systems assume a static environment, which limits the system's applicability in real-world scenarios where environments frequently change due to human intervention or the robot's own actions. In this work, we present DynaMem, a new approach to open-world mobile manipulation that uses a dynamic spatio-semantic memory to represent a robot's environment. DynaMem constructs a 3D data structure to maintain a dynamic memory of point clouds, and answers open-vocabulary object localization queries using multimodal LLMs or open-vocabulary features generated by state-of-the-art vision-language models. Powered by DynaMem, our robots can explore novel environments, search for objects not found in memory, and continuously update the memory as objects move, appear, or disappear in the scene. We run extensive experiments on the Stretch SE3 robots in three real and nine offline scenes, and achieve an average pick-and-drop success rate of 70% on non-stationary objects, which is more than a 2x improvement over state-of-the-art static systems. Our code as well as our experiment and deployment videos are open sourced and can be found on our project website: https://dynamem.github.io/
MO-DDN: A Coarse-to-Fine Attribute-based Exploration Agent for Multi-object Demand-driven Navigation
Oct 04, 2024The process of satisfying daily demands is a fundamental aspect of humans' daily lives. With the advancement of embodied AI, robots are increasingly capable of satisfying human demands. Demand-driven navigation (DDN) is a task in which an agent must locate an object to satisfy a specified demand instruction, such as ``I am thirsty.'' The previous study typically assumes that each demand instruction requires only one object to be fulfilled and does not consider individual preferences. However, the realistic human demand may involve multiple objects. In this paper, we introduce the Multi-object Demand-driven Navigation (MO-DDN) benchmark, which addresses these nuanced aspects, including multi-object search and personal preferences, thus making the MO-DDN task more reflective of real-life scenarios compared to DDN. Building upon previous work, we employ the concept of ``attribute'' to tackle this new task. However, instead of solely relying on attribute features in an end-to-end manner like DDN, we propose a modular method that involves constructing a coarse-to-fine attribute-based exploration agent (C2FAgent). Our experimental results illustrate that this coarse-to-fine exploration strategy capitalizes on the advantages of attributes at various decision-making levels, resulting in superior performance compared to baseline methods. Code and video can be found at https://sites.google.com/view/moddn.
OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
Jan 22, 2024


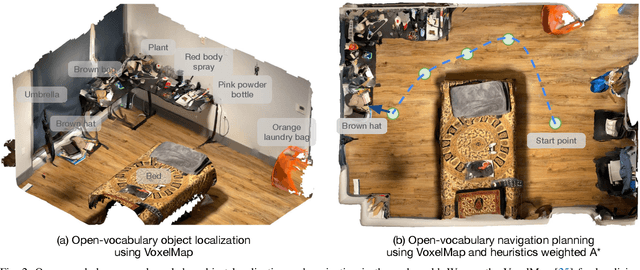
Remarkable progress has been made in recent years in the fields of vision, language, and robotics. We now have vision models capable of recognizing objects based on language queries, navigation systems that can effectively control mobile systems, and grasping models that can handle a wide range of objects. Despite these advancements, general-purpose applications of robotics still lag behind, even though they rely on these fundamental capabilities of recognition, navigation, and grasping. In this paper, we adopt a systems-first approach to develop a new Open Knowledge-based robotics framework called OK-Robot. By combining Vision-Language Models (VLMs) for object detection, navigation primitives for movement, and grasping primitives for object manipulation, OK-Robot offers a integrated solution for pick-and-drop operations without requiring any training. To evaluate its performance, we run OK-Robot in 10 real-world home environments. The results demonstrate that OK-Robot achieves a 58.5% success rate in open-ended pick-and-drop tasks, representing a new state-of-the-art in Open Vocabulary Mobile Manipulation (OVMM) with nearly 1.8x the performance of prior work. On cleaner, uncluttered environments, OK-Robot's performance increases to 82%. However, the most important insight gained from OK-Robot is the critical role of nuanced details when combining Open Knowledge systems like VLMs with robotic modules. Videos of our experiments are available on our website: https://ok-robot.github.io
Learning to Detect Noisy Labels Using Model-Based Features
Dec 28, 2022



Label noise is ubiquitous in various machine learning scenarios such as self-labeling with model predictions and erroneous data annotation. Many existing approaches are based on heuristics such as sample losses, which might not be flexible enough to achieve optimal solutions. Meta learning based methods address this issue by learning a data selection function, but can be hard to optimize. In light of these pros and cons, we propose Selection-Enhanced Noisy label Training (SENT) that does not rely on meta learning while having the flexibility of being data-driven. SENT transfers the noise distribution to a clean set and trains a model to distinguish noisy labels from clean ones using model-based features. Empirically, on a wide range of tasks including text classification and speech recognition, SENT improves performance over strong baselines under the settings of self-training and label corruption.