 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
Jan 22, 2024


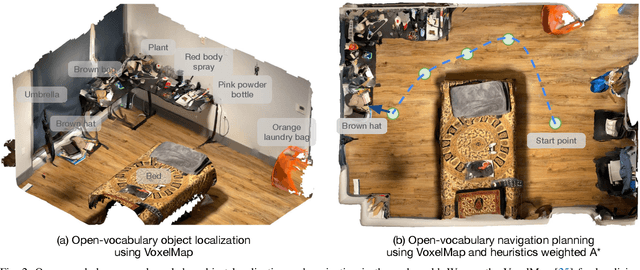
Remarkable progress has been made in recent years in the fields of vision, language, and robotics. We now have vision models capable of recognizing objects based on language queries, navigation systems that can effectively control mobile systems, and grasping models that can handle a wide range of objects. Despite these advancements, general-purpose applications of robotics still lag behind, even though they rely on these fundamental capabilities of recognition, navigation, and grasping. In this paper, we adopt a systems-first approach to develop a new Open Knowledge-based robotics framework called OK-Robot. By combining Vision-Language Models (VLMs) for object detection, navigation primitives for movement, and grasping primitives for object manipulation, OK-Robot offers a integrated solution for pick-and-drop operations without requiring any training. To evaluate its performance, we run OK-Robot in 10 real-world home environments. The results demonstrate that OK-Robot achieves a 58.5% success rate in open-ended pick-and-drop tasks, representing a new state-of-the-art in Open Vocabulary Mobile Manipulation (OVMM) with nearly 1.8x the performance of prior work. On cleaner, uncluttered environments, OK-Robot's performance increases to 82%. However, the most important insight gained from OK-Robot is the critical role of nuanced details when combining Open Knowledge systems like VLMs with robotic modules. Videos of our experiments are available on our website: https://ok-robot.github.io