 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Privacy-Savvy Are Large Language Models? A Case Study on Compliance and Privacy Technical Review
Sep 04, 2024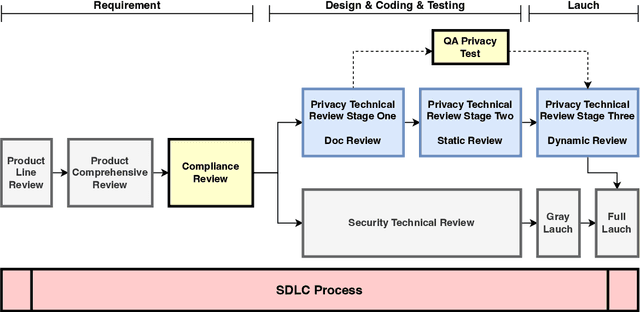
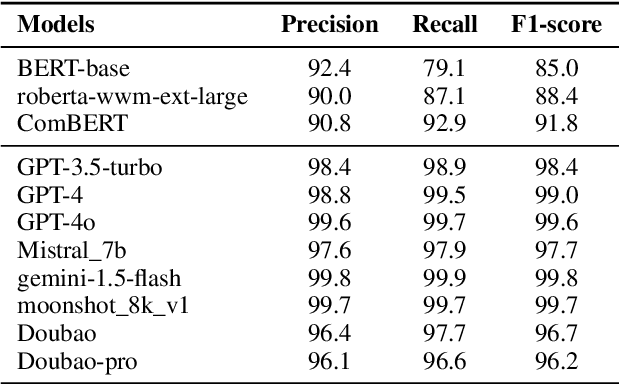
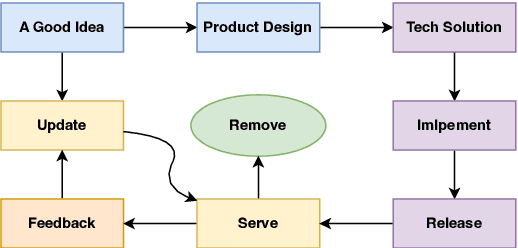
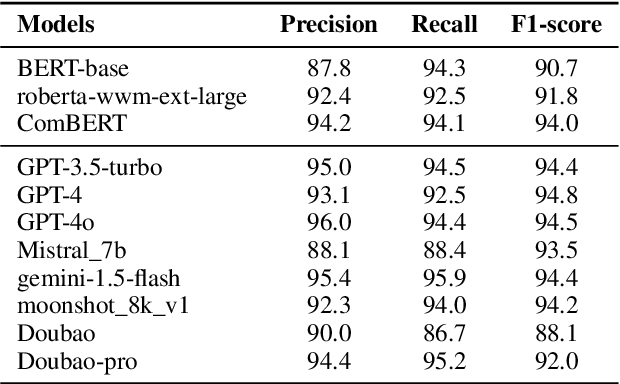
The recent advances in large language models (LLMs) have significantly expanded their applications across various fields such as language generation, summarization, and complex question answering. However, their application to privacy compliance and technical privacy reviews remains under-explored, raising critical concerns about their ability to adhere to global privacy standards and protect sensitive user data. This paper seeks to address this gap by providing a comprehensive case study evaluating LLMs' performance in privacy-related tasks such as privacy information extraction (PIE), legal and regulatory key point detection (KPD), and question answering (QA) with respect to privacy policies and data protection regulations. We introduce a Privacy Technical Review (PTR) framework, highlighting its role in mitigating privacy risks during the software development life-cycle. Through an empirical assessment, we investigate the capacity of several prominent LLMs, including BERT, GPT-3.5, GPT-4, and custom models, in executing privacy compliance checks and technical privacy reviews. Our experiments benchmark the models across multiple dimensions, focusing on their precision, recall, and F1-scores in extracting privacy-sensitive information and detecting key regulatory compliance points. While LLMs show promise in automating privacy reviews and identifying regulatory discrepancies, significant gaps persist in their ability to fully comply with evolving legal standards. We provide actionable recommendations for enhancing LLMs' capabilities in privacy compliance, emphasizing the need for robust model improvements and better integration with legal and regulatory requirements. This study underscores the growing importance of developing privacy-aware LLMs that can both support businesses in compliance efforts and safeguard user privacy rights.
Do Large Language Models Possess Sensitive to Sentiment?
Sep 04, 2024Large Language Models (LLMs) have recently displayed their extraordinary capabilities in language understanding. However, how to comprehensively assess the sentiment capabilities of LLMs continues to be a challenge. This paper investigates the ability of LLMs to detect and react to sentiment in text modal. As the integration of LLMs into diverse applications is on the rise, it becomes highly critical to comprehend their sensitivity to emotional tone, as it can influence the user experience and the efficacy of sentiment-driven tasks. We conduct a series of experiments to evaluate the performance of several prominent LLMs in identifying and responding appropriately to sentiments like positive, negative, and neutral emotions. The models' outputs are analyzed across various sentiment benchmarks, and their responses are compared with human evaluations. Our discoveries indicate that although LLMs show a basic sensitivity to sentiment, there are substantial variations in their accuracy and consistency, emphasizing the requirement for further enhancements in their training processes to better capture subtle emotional cues. Take an example in our findings, in some cases, the models might wrongly classify a strongly positive sentiment as neutral, or fail to recognize sarcasm or irony in the text. Such misclassifications highlight the complexity of sentiment analysis and the areas where the models need to be refined. Another aspect is that different LLMs might perform differently on the same set of data, depending on their architecture and training datasets. This variance calls for a more in-depth study of the factors that contribute to the performance differences and how they can be optimized.
Beyond the Label Itself: Latent Labels Enhance Semi-supervised Point Cloud Panoptic Segmentation
Dec 13, 2023As the exorbitant expense of labeling autopilot datasets and the growing trend of utilizing unlabeled data, semi-supervised segmentation on point clouds becomes increasingly imperative. Intuitively, finding out more ``unspoken words'' (i.e., latent instance information) beyond the label itself should be helpful to improve performance. In this paper, we discover two types of latent labels behind the displayed label embedded in LiDAR and image data. First, in the LiDAR Branch, we propose a novel augmentation, Cylinder-Mix, which is able to augment more yet reliable samples for training. Second, in the Image Branch, we propose the Instance Position-scale Learning (IPSL) Module to learn and fuse the information of instance position and scale, which is from a 2D pre-trained detector and a type of latent label obtained from 3D to 2D projection. Finally, the two latent labels are embedded into the multi-modal panoptic segmentation network. The ablation of the IPSL module demonstrates its robust adaptability, and the experiments evaluated on SemanticKITTI and nuScenes demonstrate that our model outperforms the state-of-the-art method, LaserMix.
Learning to Detect Noisy Labels Using Model-Based Features
Dec 28, 2022



Label noise is ubiquitous in various machine learning scenarios such as self-labeling with model predictions and erroneous data annotation. Many existing approaches are based on heuristics such as sample losses, which might not be flexible enough to achieve optimal solutions. Meta learning based methods address this issue by learning a data selection function, but can be hard to optimize. In light of these pros and cons, we propose Selection-Enhanced Noisy label Training (SENT) that does not rely on meta learning while having the flexibility of being data-driven. SENT transfers the noise distribution to a clean set and trains a model to distinguish noisy labels from clean ones using model-based features. Empirically, on a wide range of tasks including text classification and speech recognition, SENT improves performance over strong baselines under the settings of self-training and label corruption.
GPS: Genetic Prompt Search for Efficient Few-shot Learning
Oct 31, 2022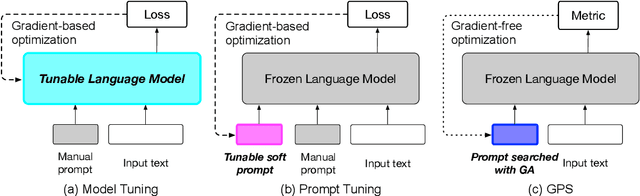
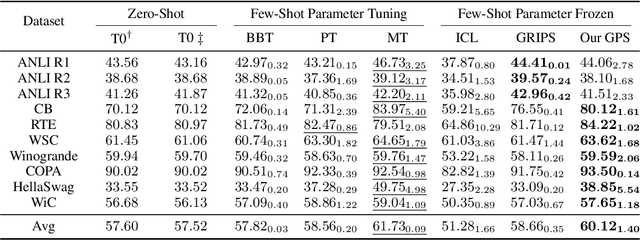
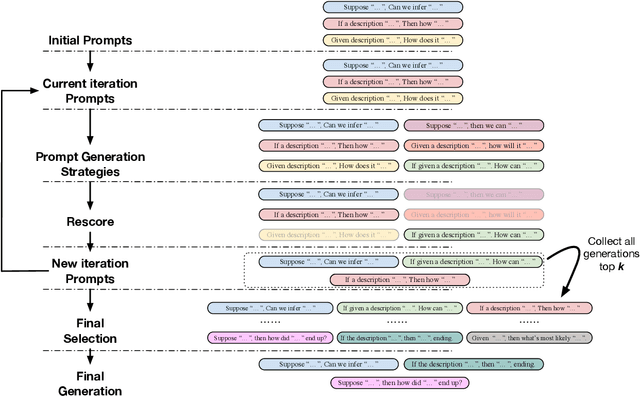

Prompt-based techniques have demostrated great potential for improving the few-shot generalization of pretrained language models. However, their performance heavily relies on the manual design of prompts and thus requires a lot of human efforts. In this paper, we introduce Genetic Prompt Search (GPS) to improve few-shot learning with prompts, which utilizes a genetic algorithm to automatically search for high-performing prompts. GPS is gradient-free and requires no update of model parameters but only a small validation set. Experiments on diverse datasets proved the effectiveness of GPS, which outperforms manual prompts by a large margin of 2.6 points. Our method is also better than other parameter-efficient tuning methods such as prompt tuning.
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Jan 18, 2022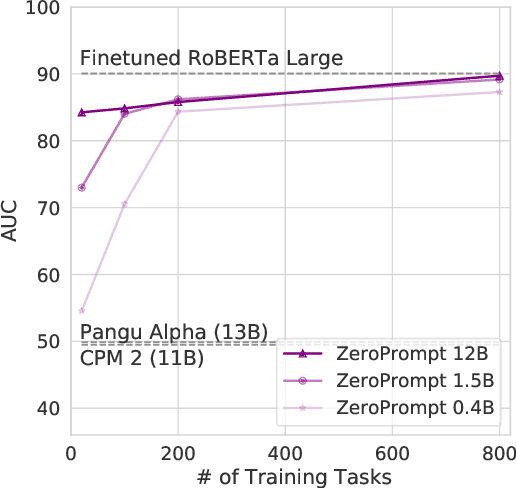



We propose a multitask pretraining approach ZeroPrompt for zero-shot generalization, focusing on task scaling and zero-shot prompting. While previous models are trained on only a few dozen tasks, we scale to 1,000 tasks for the first time using real-world data. This leads to a crucial discovery that task scaling can be an efficient alternative to model scaling; i.e., the model size has little impact on performance with an extremely large number of tasks. Our results show that task scaling can substantially improve training efficiency by 30 times in FLOPs. Moreover, we present a prompting method that incorporates a genetic algorithm to automatically search for the best prompt for unseen tasks, along with a few other improvements. Empirically, ZeroPrompt substantially improves both the efficiency and the performance of zero-shot learning across a variety of academic and production datasets.
Distribution Matching for Rationalization
Jun 01, 2021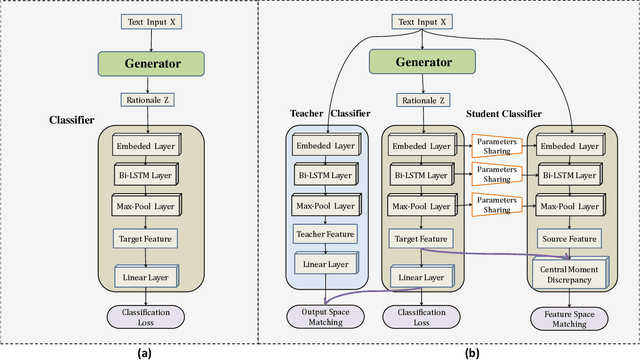

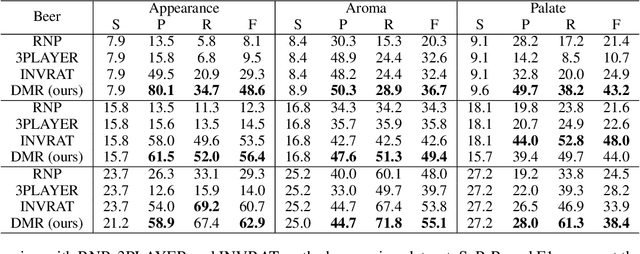
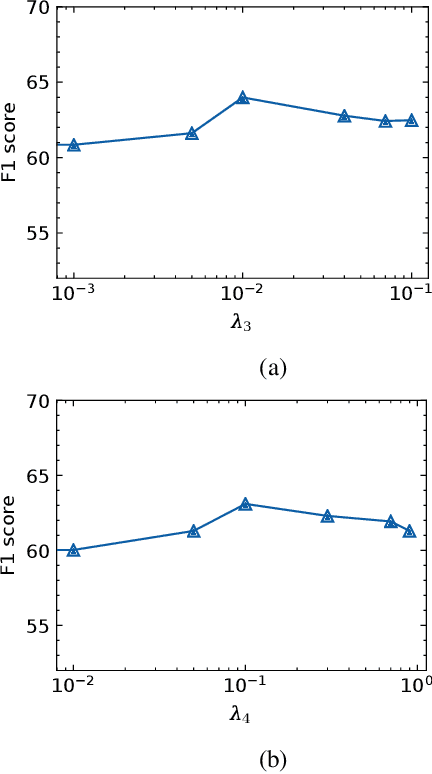
The task of rationalization aims to extract pieces of input text as rationales to justify neural network predictions on text classification tasks. By definition, rationales represent key text pieces used for prediction and thus should have similar classification feature distribution compared to the original input text. However, previous methods mainly focused on maximizing the mutual information between rationales and labels while neglecting the relationship between rationales and input text. To address this issue, we propose a novel rationalization method that matches the distributions of rationales and input text in both the feature space and output space. Empirically, the proposed distribution matching approach consistently outperforms previous methods by a large margin. Our data and code are available.
* Accepted by AAAI2021