 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Privacy-Savvy Are Large Language Models? A Case Study on Compliance and Privacy Technical Review
Sep 04, 2024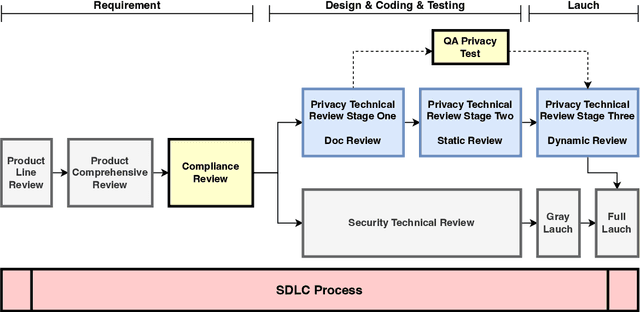
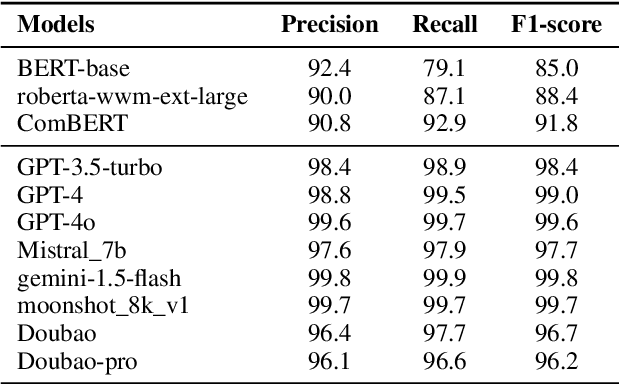
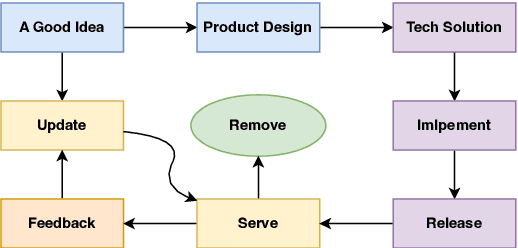
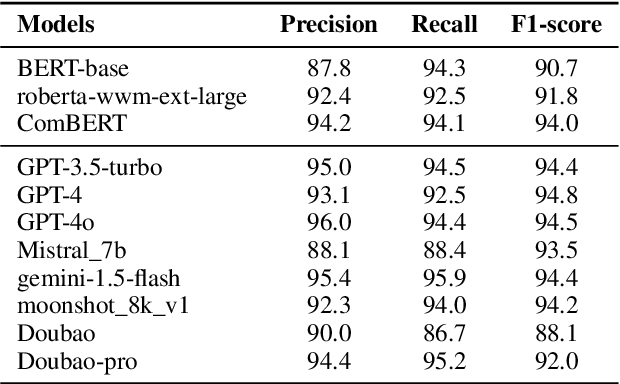
The recent advances in large language models (LLMs) have significantly expanded their applications across various fields such as language generation, summarization, and complex question answering. However, their application to privacy compliance and technical privacy reviews remains under-explored, raising critical concerns about their ability to adhere to global privacy standards and protect sensitive user data. This paper seeks to address this gap by providing a comprehensive case study evaluating LLMs' performance in privacy-related tasks such as privacy information extraction (PIE), legal and regulatory key point detection (KPD), and question answering (QA) with respect to privacy policies and data protection regulations. We introduce a Privacy Technical Review (PTR) framework, highlighting its role in mitigating privacy risks during the software development life-cycle. Through an empirical assessment, we investigate the capacity of several prominent LLMs, including BERT, GPT-3.5, GPT-4, and custom models, in executing privacy compliance checks and technical privacy reviews. Our experiments benchmark the models across multiple dimensions, focusing on their precision, recall, and F1-scores in extracting privacy-sensitive information and detecting key regulatory compliance points. While LLMs show promise in automating privacy reviews and identifying regulatory discrepancies, significant gaps persist in their ability to fully comply with evolving legal standards. We provide actionable recommendations for enhancing LLMs' capabilities in privacy compliance, emphasizing the need for robust model improvements and better integration with legal and regulatory requirements. This study underscores the growing importance of developing privacy-aware LLMs that can both support businesses in compliance efforts and safeguard user privacy rights.