 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAW-GATCN: Adaptive Weighted Graph Attention Convolutional Network for Event Camera Data Joint Denoising and Object Recognition
May 16, 2025Event cameras, which capture brightness changes with high temporal resolution, inherently generate a significant amount of redundant and noisy data beyond essential object structures. The primary challenge in event-based object recognition lies in effectively removing this noise without losing critical spatial-temporal information. To address this, we propose an Adaptive Graph-based Noisy Data Removal framework for Event-based Object Recognition. Specifically, our approach integrates adaptive event segmentation based on normalized density analysis, a multifactorial edge-weighting mechanism, and adaptive graph-based denoising strategies. These innovations significantly enhance the integration of spatiotemporal information, effectively filtering noise while preserving critical structural features for robust recognition. Experimental evaluations on four challenging datasets demonstrate that our method achieves superior recognition accuracies of 83.77%, 76.79%, 99.30%, and 96.89%, surpassing existing graph-based methods by up to 8.79%, and improving noise reduction performance by up to 19.57%, with an additional accuracy gain of 6.26% compared to traditional Euclidean-based techniques.
GPS: Genetic Prompt Search for Efficient Few-shot Learning
Oct 31, 2022
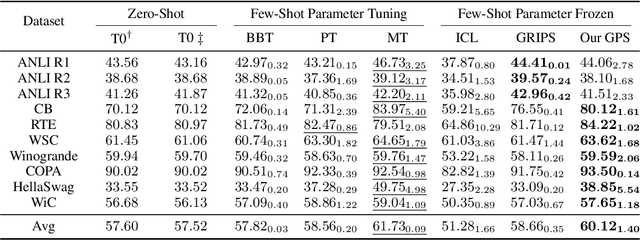
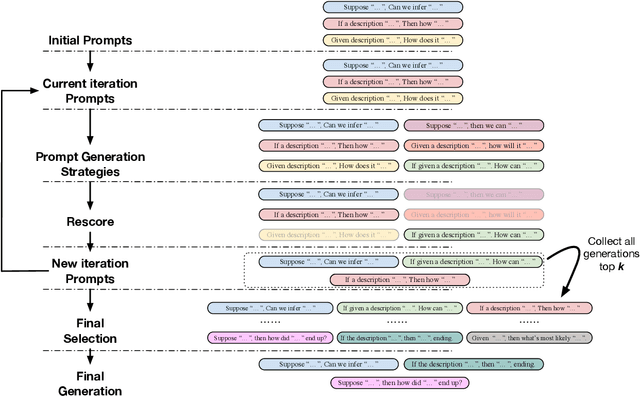

Prompt-based techniques have demostrated great potential for improving the few-shot generalization of pretrained language models. However, their performance heavily relies on the manual design of prompts and thus requires a lot of human efforts. In this paper, we introduce Genetic Prompt Search (GPS) to improve few-shot learning with prompts, which utilizes a genetic algorithm to automatically search for high-performing prompts. GPS is gradient-free and requires no update of model parameters but only a small validation set. Experiments on diverse datasets proved the effectiveness of GPS, which outperforms manual prompts by a large margin of 2.6 points. Our method is also better than other parameter-efficient tuning methods such as prompt tuning.
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Jan 18, 2022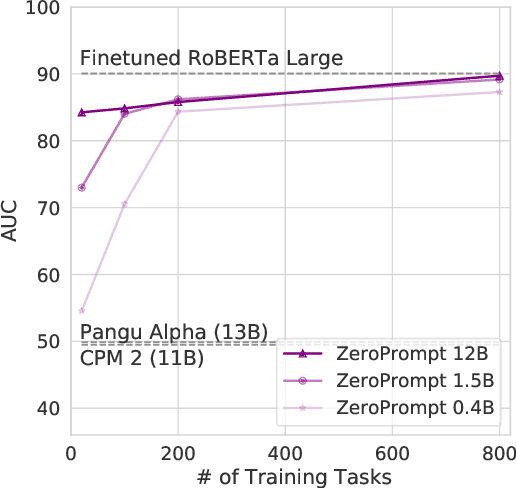



We propose a multitask pretraining approach ZeroPrompt for zero-shot generalization, focusing on task scaling and zero-shot prompting. While previous models are trained on only a few dozen tasks, we scale to 1,000 tasks for the first time using real-world data. This leads to a crucial discovery that task scaling can be an efficient alternative to model scaling; i.e., the model size has little impact on performance with an extremely large number of tasks. Our results show that task scaling can substantially improve training efficiency by 30 times in FLOPs. Moreover, we present a prompting method that incorporates a genetic algorithm to automatically search for the best prompt for unseen tasks, along with a few other improvements. Empirically, ZeroPrompt substantially improves both the efficiency and the performance of zero-shot learning across a variety of academic and production datasets.