 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Coherent Hierarchical Probabilistic Forecasting of Electric Vehicle Charging Demand
Nov 04, 2024



The growing penetration of electric vehicles (EVs) significantly changes typical load curves in smart grids. With the development of fast charging technology, the volatility of EV charging demand is increasing, which requires additional flexibility for real-time power balance. The forecasting of EV charging demand involves probabilistic modeling of high dimensional time series dynamics across diverse electric vehicle charging stations (EVCSs). This paper studies the forecasting problem of multiple EVCS in a hierarchical probabilistic manner. For each charging station, a deep learning model based on a partial input convex neural network (PICNN) is trained to predict the day-ahead charging demand's conditional distribution, preventing the common quantile crossing problem in traditional quantile regression models. Then, differentiable convex optimization layers (DCLs) are used to reconcile the scenarios sampled from the distributions to yield coherent scenarios that satisfy the hierarchical constraint. It learns a better weight matrix for adjusting the forecasting results of different targets in a machine-learning approach compared to traditional optimization-based hierarchical reconciling methods. Numerical experiments based on real-world EV charging data are conducted to demonstrate the efficacy of the proposed method.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Mar 11, 2024
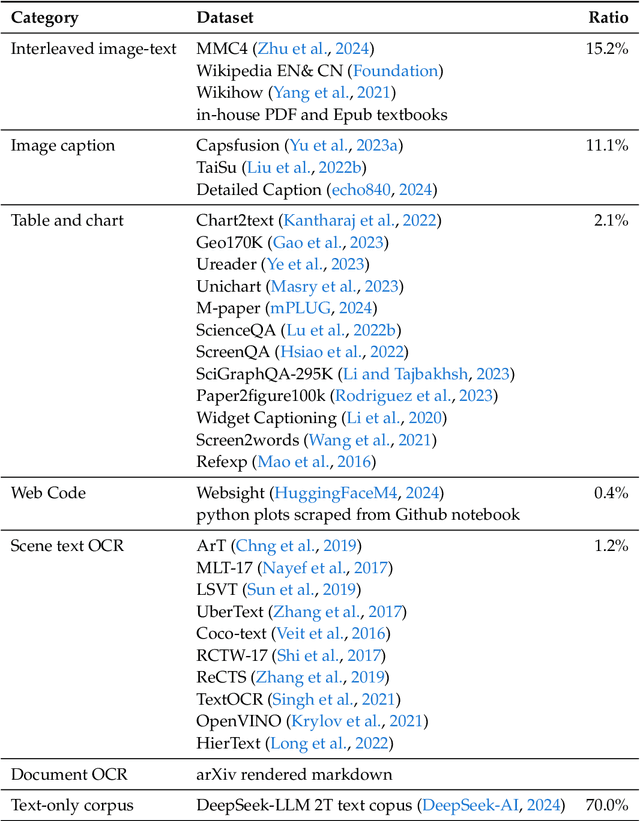
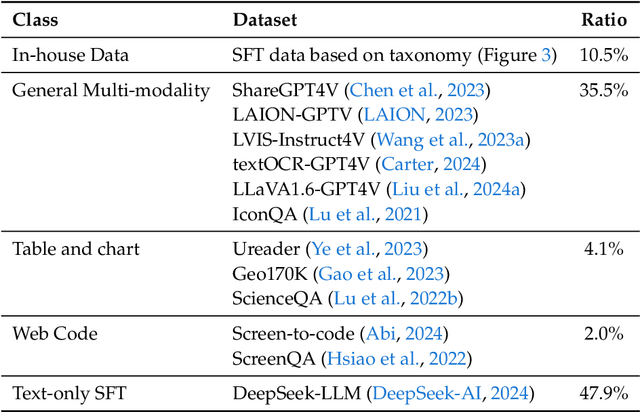
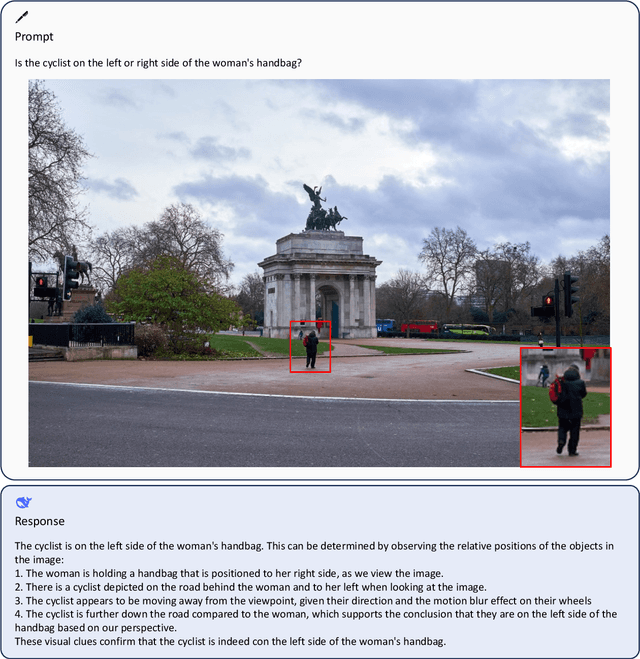
We present DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. Our approach is structured around three key dimensions: We strive to ensure our data is diverse, scalable, and extensively covers real-world scenarios including web screenshots, PDFs, OCR, charts, and knowledge-based content, aiming for a comprehensive representation of practical contexts. Further, we create a use case taxonomy from real user scenarios and construct an instruction tuning dataset accordingly. The fine-tuning with this dataset substantially improves the model's user experience in practical applications. Considering efficiency and the demands of most real-world scenarios, DeepSeek-VL incorporates a hybrid vision encoder that efficiently processes high-resolution images (1024 x 1024), while maintaining a relatively low computational overhead. This design choice ensures the model's ability to capture critical semantic and detailed information across various visual tasks. We posit that a proficient Vision-Language Model should, foremost, possess strong language abilities. To ensure the preservation of LLM capabilities during pretraining, we investigate an effective VL pretraining strategy by integrating LLM training from the beginning and carefully managing the competitive dynamics observed between vision and language modalities. The DeepSeek-VL family (both 1.3B and 7B models) showcases superior user experiences as a vision-language chatbot in real-world applications, achieving state-of-the-art or competitive performance across a wide range of visual-language benchmarks at the same model size while maintaining robust performance on language-centric benchmarks. We have made both 1.3B and 7B models publicly accessible to foster innovations based on this foundation model.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
GPS: Genetic Prompt Search for Efficient Few-shot Learning
Oct 31, 2022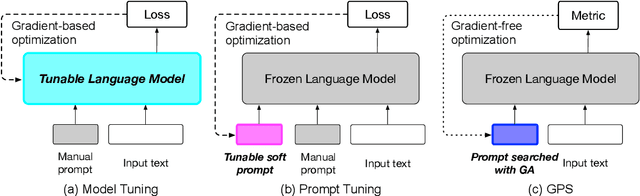
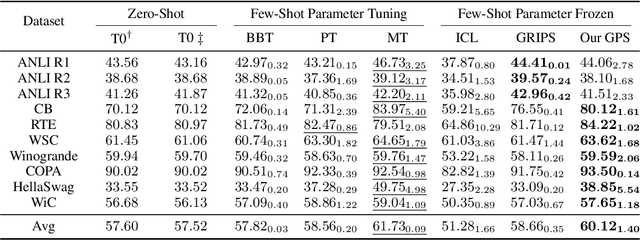
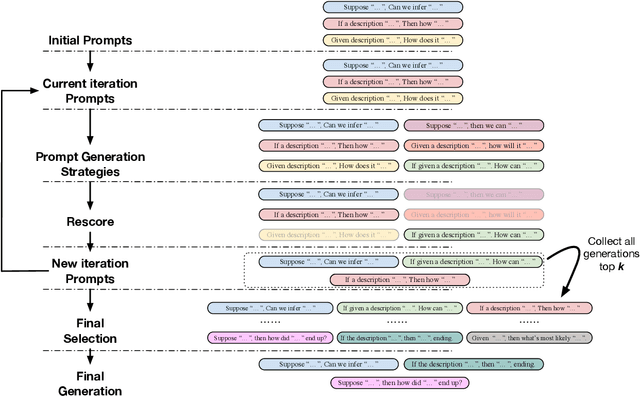

Prompt-based techniques have demostrated great potential for improving the few-shot generalization of pretrained language models. However, their performance heavily relies on the manual design of prompts and thus requires a lot of human efforts. In this paper, we introduce Genetic Prompt Search (GPS) to improve few-shot learning with prompts, which utilizes a genetic algorithm to automatically search for high-performing prompts. GPS is gradient-free and requires no update of model parameters but only a small validation set. Experiments on diverse datasets proved the effectiveness of GPS, which outperforms manual prompts by a large margin of 2.6 points. Our method is also better than other parameter-efficient tuning methods such as prompt tuning.
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Jan 18, 2022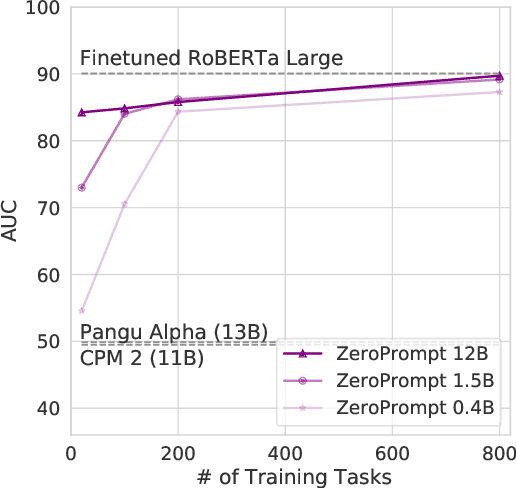



We propose a multitask pretraining approach ZeroPrompt for zero-shot generalization, focusing on task scaling and zero-shot prompting. While previous models are trained on only a few dozen tasks, we scale to 1,000 tasks for the first time using real-world data. This leads to a crucial discovery that task scaling can be an efficient alternative to model scaling; i.e., the model size has little impact on performance with an extremely large number of tasks. Our results show that task scaling can substantially improve training efficiency by 30 times in FLOPs. Moreover, we present a prompting method that incorporates a genetic algorithm to automatically search for the best prompt for unseen tasks, along with a few other improvements. Empirically, ZeroPrompt substantially improves both the efficiency and the performance of zero-shot learning across a variety of academic and production datasets.