 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPS: Genetic Prompt Search for Efficient Few-shot Learning
Oct 31, 2022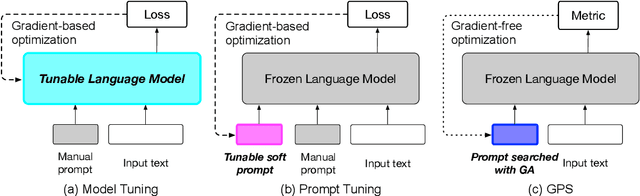
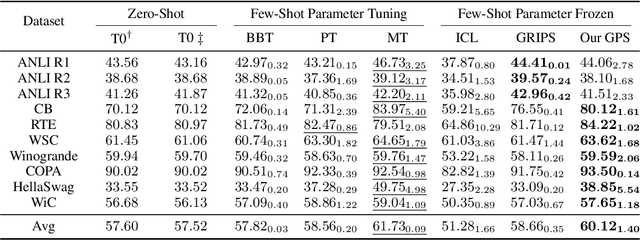
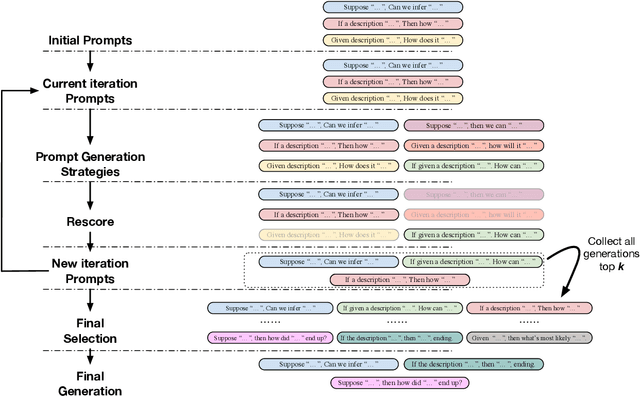

Prompt-based techniques have demostrated great potential for improving the few-shot generalization of pretrained language models. However, their performance heavily relies on the manual design of prompts and thus requires a lot of human efforts. In this paper, we introduce Genetic Prompt Search (GPS) to improve few-shot learning with prompts, which utilizes a genetic algorithm to automatically search for high-performing prompts. GPS is gradient-free and requires no update of model parameters but only a small validation set. Experiments on diverse datasets proved the effectiveness of GPS, which outperforms manual prompts by a large margin of 2.6 points. Our method is also better than other parameter-efficient tuning methods such as prompt tuning.
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Jan 18, 2022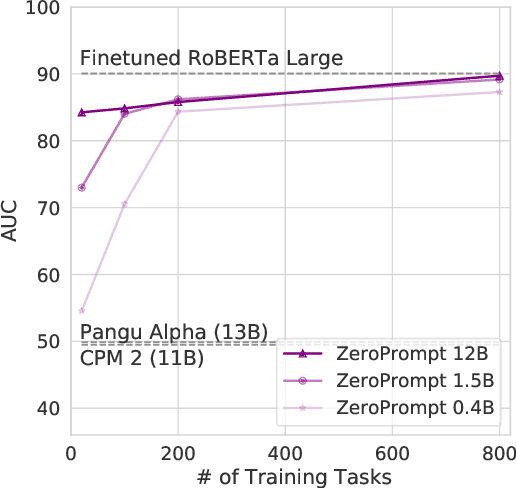



We propose a multitask pretraining approach ZeroPrompt for zero-shot generalization, focusing on task scaling and zero-shot prompting. While previous models are trained on only a few dozen tasks, we scale to 1,000 tasks for the first time using real-world data. This leads to a crucial discovery that task scaling can be an efficient alternative to model scaling; i.e., the model size has little impact on performance with an extremely large number of tasks. Our results show that task scaling can substantially improve training efficiency by 30 times in FLOPs. Moreover, we present a prompting method that incorporates a genetic algorithm to automatically search for the best prompt for unseen tasks, along with a few other improvements. Empirically, ZeroPrompt substantially improves both the efficiency and the performance of zero-shot learning across a variety of academic and production datasets.
Memory Augmented Sequential Paragraph Retrieval for Multi-hop Question Answering
Feb 07, 2021Retrieving information from correlative paragraphs or documents to answer open-domain multi-hop questions is very challenging. To deal with this challenge, most of the existing works consider paragraphs as nodes in a graph and propose graph-based methods to retrieve them. However, in this paper, we point out the intrinsic defect of such methods. Instead, we propose a new architecture that models paragraphs as sequential data and considers multi-hop information retrieval as a kind of sequence labeling task. Specifically, we design a rewritable external memory to model the dependency among paragraphs. Moreover, a threshold gate mechanism is proposed to eliminate the distraction of noise paragraphs. We evaluate our method on both full wiki and distractor subtask of HotpotQA, a public textual multi-hop QA dataset requiring multi-hop information retrieval. Experiments show that our method achieves significant improvement over the published state-of-the-art method in retrieval and downstream QA task performance.
Is Graph Structure Necessary for Multi-hop Reasoning?
Apr 07, 2020



Recently, many works attempt to model texts as graph structure and introduce graph neural networks to deal with it on many NLP tasks.In this paper, we investigate whether graph structure is necessary for multi-hop reasoning tasks and what role it plays. Our analysis is centered on HotpotQA. We use the state-of-the-art published model, Dynamically Fused Graph Network (DFGN), as our baseline. By directly modifying the pre-trained model, our baseline model gains a large improvement and significantly surpass both published and unpublished works. Ablation experiments established that, with the proper use of pre-trained models, graph structure may not be necessary for multi-hop reasoning. We point out that both the graph structure and the adjacency matrix are task-related prior knowledge, and graph-attention can be considered as a special case of self-attention. Experiments demonstrate that graph-attention or the entire graph structure can be replaced by self-attention or Transformers, and achieve similar results to the previous state-of-the-art model achieved.
TripleNet: Triple Attention Network for Multi-Turn Response Selection in Retrieval-based Chatbots
Sep 29, 2019


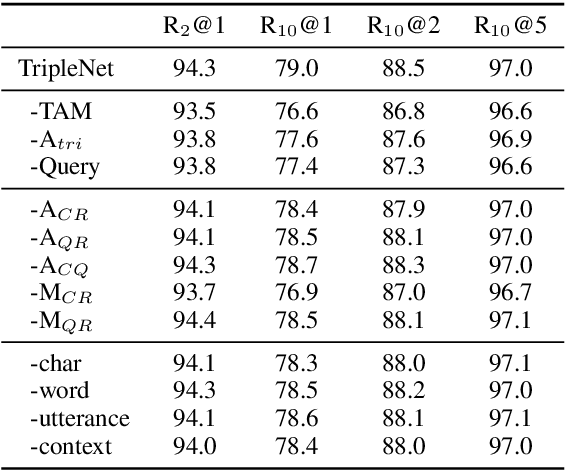
We consider the importance of different utterances in the context for selecting the response usually depends on the current query. In this paper, we propose the model TripleNet to fully model the task with the triple <context, query, response> instead of <context, response> in previous works. The heart of TripleNet is a novel attention mechanism named triple attention to model the relationships within the triple at four levels. The new mechanism updates the representation for each element based on the attention with the other two concurrently and symmetrically. We match the triple <C, Q, R> centered on the response from char to context level for prediction. Experimental results on two large-scale multi-turn response selection datasets show that the proposed model can significantly outperform the state-of-the-art methods. TripleNet source code is available at https://github.com/wtma/TripleNet